

论文地址:https://arxiv.org/pdf/2208.08612
引言
求职招聘是一个双向选择的过程,作为参与方的求职者和招聘岗位应当同时满足双边的需要,而不仅仅满足其中某一方。针对该场景下的人岗匹配问题,本文提出了一种双视角图表示学习方法,同时建模求职者和招聘岗位之间的双向选择偏好。
为了从求职者和岗位的双重视角对双方偏好进行建模,本文为每个求职者(或岗位)引入两个不同的节点,并通过统一的双重视角交互图对不同方向和类型的交互进行建模,同时为了有效地学习双视角节点表示,本文还设计了一种有效的优化算法,包含四元损失和双视角对比学习损失。
背景介绍
随着互联网技术的快速发展,在线招聘平台中的求职者和招聘岗位的数量迅速增长,在这一背景下,如何能够设计有效的算法并通过推荐机制在求职者和招聘岗位之间建立高质量的联系是至关重要的。
现有的研究或者对单向选择过程(如根据岗位要求推荐合适的求职者)进行建模,或者对静态匹配关系(如简历/职位文本匹配方法)进行建模。由于求职招聘过程涉及求职者和招聘岗位双方,自然应当体现从求职者和招聘岗位两个角度的双向选择偏好,为了实现求职者与岗位的匹配,参与互动的双方应该同时满足对方的需要,单方面的满意无法使得匹配成功,双边期望的达成才是人岗匹配成功的关键。
问题定义
本文定义的人岗匹配为求职者和招聘岗位的匹配问题,最终目标是为人岗双方做推荐,所以可以视作为求职者和招聘岗位双方做推荐的排序问题。
在该场景下,每一个求职者和招聘岗位都有一段描述简历或职位的文本,同时在招聘平台中也沉淀了求职者和招聘方的一系列行为记录,比如求职者主动沟通岗位和招聘方主动联系求职者等,我们将其定义为三种不同的行为,求职者单向行为,招聘方单向行为以及成功匹配达成。
我们认为在求职招聘过程中,提供和接受职位是一个双向的过程,求职者和招聘方都会对对方表达自己的意图,这是双方的选择偏好。我们显式地将求职者和招聘方的选择偏好建模为 和 ,通过融合双视角的选择偏好来提升人岗匹配的效果。
方法描述
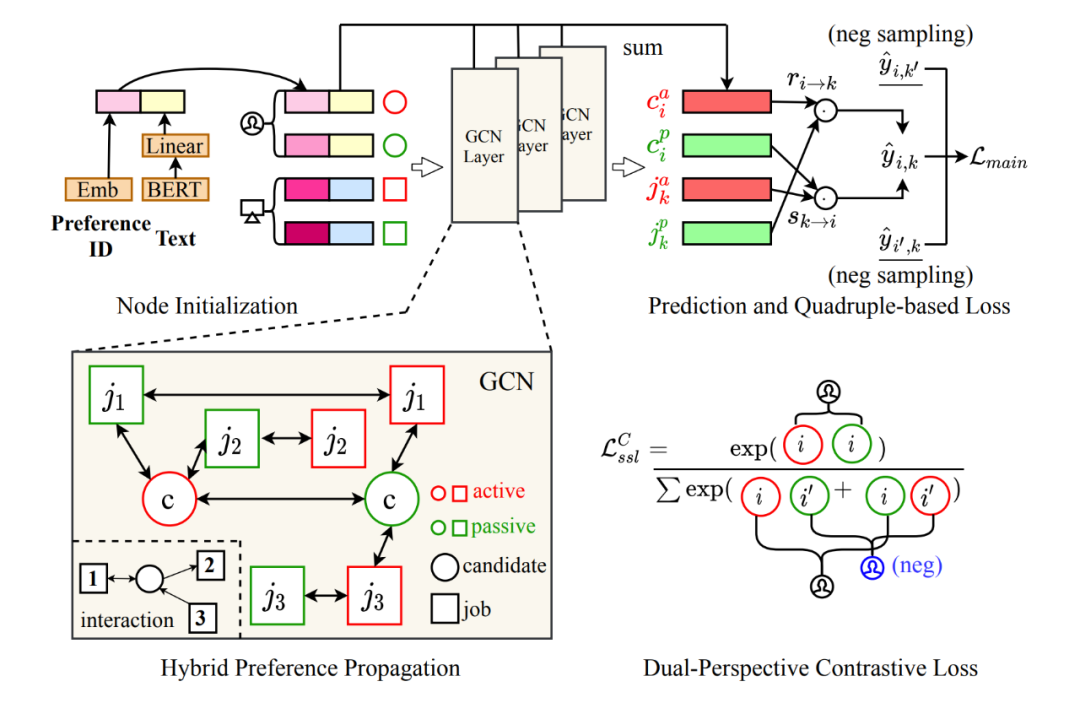 人岗匹配需要考虑双向选择偏好,本文提出双视角图卷积神经网络来建模求职者和岗位之间不同的有向行为。上图为所提出的 DPGNN 模型的总体框架,以下将从双视角图表示学习、自监督增强的双视角排序优化两个方面来介绍本文所提出的模型的细节内容。
人岗匹配需要考虑双向选择偏好,本文提出双视角图卷积神经网络来建模求职者和岗位之间不同的有向行为。上图为所提出的 DPGNN 模型的总体框架,以下将从双视角图表示学习、自监督增强的双视角排序优化两个方面来介绍本文所提出的模型的细节内容。
4.1 双视角表示学习
1. 构建双视角交互图
为了刻画不同方向的行为,给定一个求职者c,我们将其主动偏好和被动偏好分开表示,记为\( c^a \)和\( c^p \)类似的,用\( j^a \)和\( j^p \)代表岗位\( j \)的主动和被动表示,也就是说,在图的构建过程中,每个求职者和岗位分别建立两个节点,分别刻画他们的主动偏好和被动偏好。此交互图中的边通过三种不同的交互行为及其自身关联来构建,具体如下:
-
求职者主动申请但是没有被接受:这种情况代表了招聘岗位满足求职者的期望,但是求职者没有满足招聘岗位的期望,这种单向行为反映了求职者的主动偏好,因此建立\( c^a \)与\( j^p \)之间的边。
-
招聘方主动联系求职者但是被拒绝:与第一种情况类似,建立\( c^p \)与\( j^a \)之间的边。
-
双方达成了面试约定:这种情况代表双方都满足了对方的期望,因此建立对应的两条边(即\( c^a \)与\( j^p \),\( c^p \)与\( j^a \))
举例来讲,如上图左下角所示,红色代表主动节点,绿色代表被动节点,方形代表岗位,圆形代表求职者,对于一个给定的求职者c,岗位 3 主动沟通了该求职者却没被接受,其主动联系岗位 2 却被拒绝,而其与岗位 1 最终达成了面试约定,因此建立的边结构如图所示。
2. 节点初始化
对于图中每个节点n,首先根据 ID 获取一个偏好嵌入,其次,每一个求职者和岗位都与一段描述性文本(简历文本/职位描述),我们进一步利用 BERT 模型对这段文本进行编码:保留文本的原始顺序,在文本的前面插入一个特殊的 token ——[CLS],然后将这段文本序列送入 BERT 模型,添加一个线性层以获取最终文本表示。这里同一求职者(岗位)的两个节点的文本表示相同。
如上图左上角所示,最终的节点表示由两部分拼接而成:
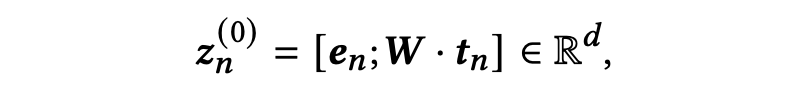
3. 混合偏好的传播
本文用交互图的形式来描述交互行为,采用图卷积网络(GCN)来学习节点表示。与之前的 GCN 研究不同,我们对每个涉及的求职者和岗位有两种不同的边,因此我们提出了一种混合偏好传播算法来学习节点表示。需要注意的是,这些差异体现在在边类型而不是节点类型上,因此可以统一定义所有节点的偏好传播:
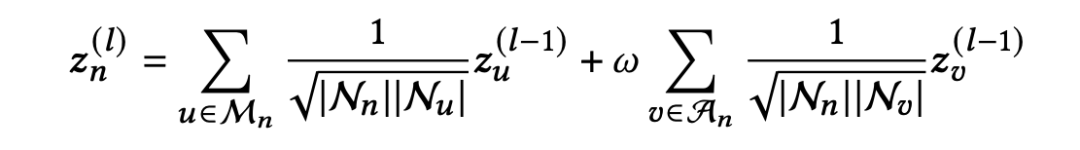
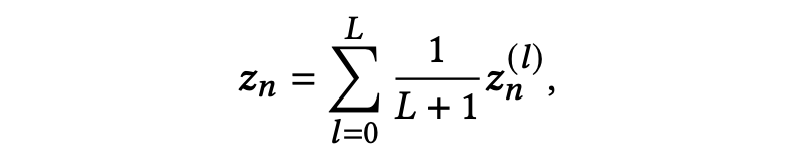
4. 预测
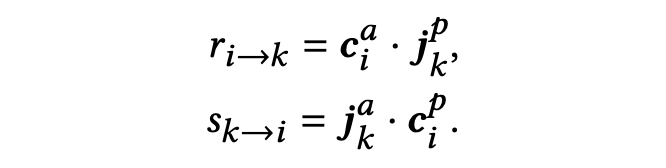
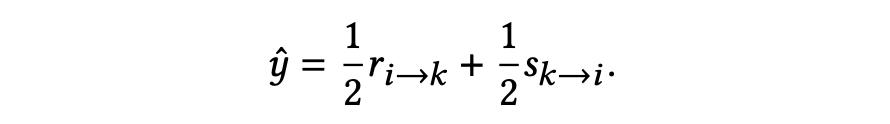
4.2 自监督增强的双视角排序优化
1. 四元损失函数
我们提出了一种新的四元损失函数。在求职招聘场景中,一个成功的匹配通常意味着从求职者的角度来看,该职位的排序应该很高,反之亦然。这两种视角都同样重要,必须同时满足双方偏好。
给定一个匹配的人岗对,通过采样获取一个与该岗位不匹配的求职者以及一个与该求职者不匹配的岗位,构建一个四元组 $$,直观上看,匹配记录的得分即正例得分应该同时高于双边负例得分,因此将广泛使用的 BPR 损失扩展为四元损失如下:
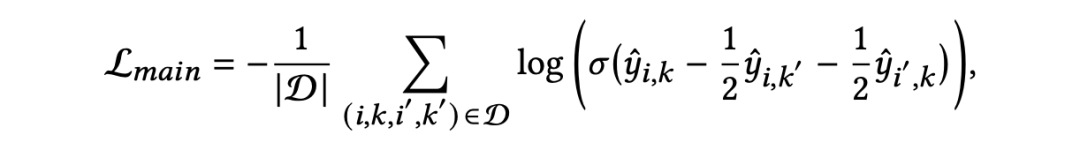
2. 双视角对比学习
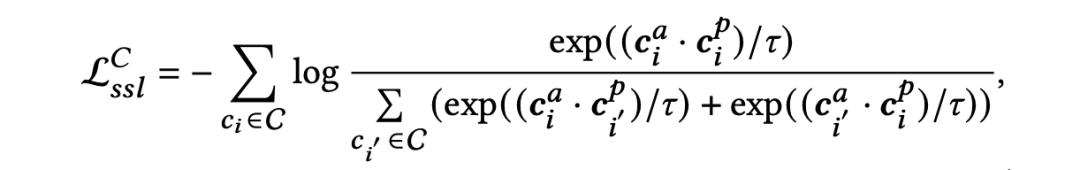
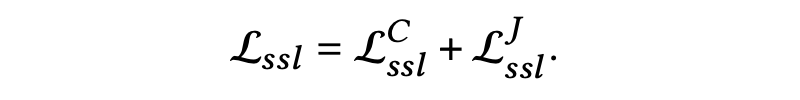
4.3 算法流程

实验结果
5.1 数据集介绍
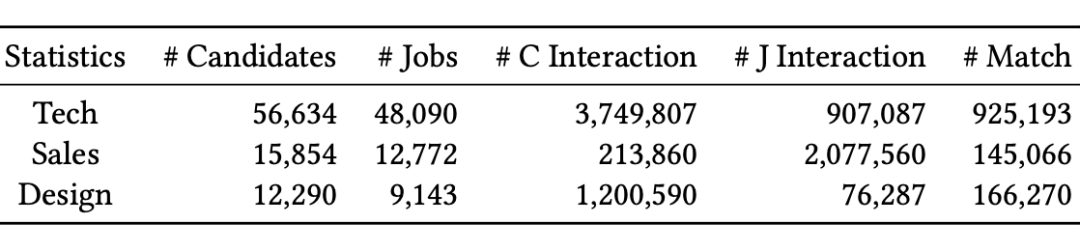
本文基于在线招聘平台 BOSS 直聘的数据集进行相关实验,数据集包括三个职位类别:技术类、销售类和设计类。下表统计了处理后的实验数据统计信息:
5.2 对比实验
本文选取的基线模型包括三类:基于协同过滤的方法(BPRMF [1],NCF [2],LightGCN [3],LFRR [4]),基于内容的方法(PJFNN [5],BPJFNN [6],APJFNN [6]),混合方法(LIGCN_BERT,IPJF [7],PJFFF [8]),主实验的实验结果如下图:
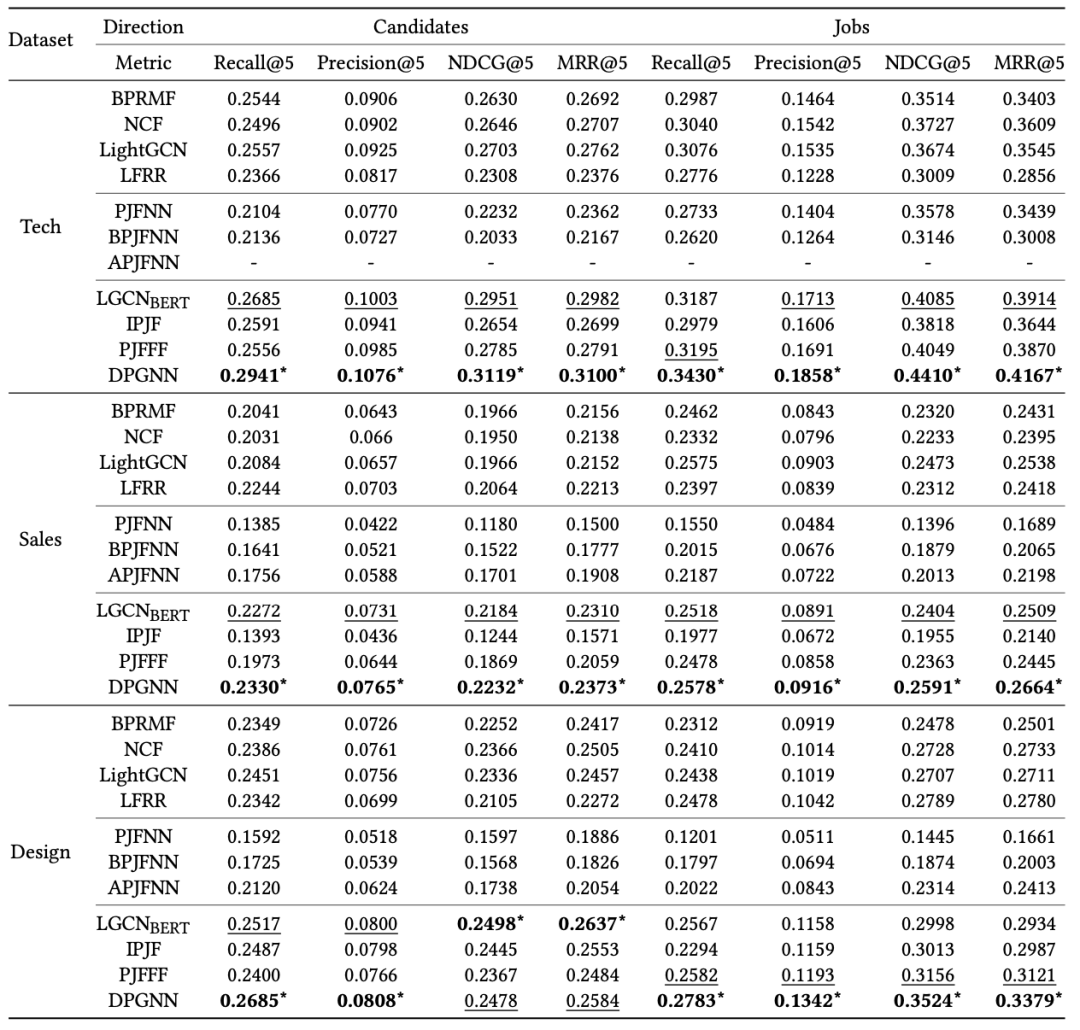
根据表中的实验结果,对于 4 种协同过滤模型,LightGCN 的性能最好,但与 BPRMF、NCF 和 LFRR 相比改进不显著。对于 BPJFNN、PJFNN 和 APJFNN 这三种基于内容的模型,其对文本内容的依赖程度较高,在大多数情况下表现不佳,可能的原因是,他们要求简历和岗位文本的结构性和完整性,而在我们的场景中,平台上的用户有不同的文本组织习惯。
IPJF 在销售方面表现不佳,这是由于不同类型交互的数量不平衡造成的。在大多数情况下,PJFFF 的性能更好,因为 PJFFF 集成了历史交互简历或职位描述。此外,技术类的岗位通常比其他岗位有更具体的技能要求,使得基于文本的模型在技术类中相对更有效。最后,正如我们所看到的,LIGCN_BERT 同时利用了交互行为和文本信息,它在基线模型中表现最好,这表明同时利用文本描述和交互行为是很重要的。
我们的方法在三个数据集的大多数指标上都取得了最好的性能。具体来说,在技术、销售和设计类数据集上,对比最佳基线模型,平均分别提升了 7.12%、4.81% 和 7.73%。与基线模型不同的是,我们的方法模拟了求职者和岗位的双向选择偏好,更适合于该场景。
5.3 消融实验
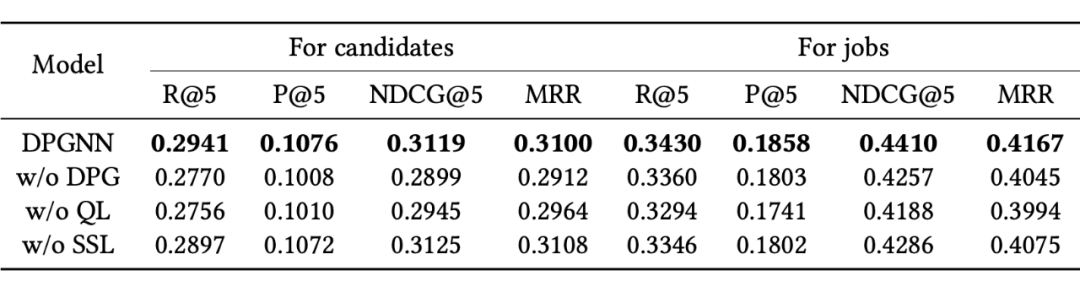
本文所提出方法的主要技术贡献在于双视角交互图的构建,以及涉及的两个优化目标,现在我们来分析每个部分对最终性能的影响。我们考虑 DPGNN 的以下三种变体:
(A) DPGNN w/o DPG:将提出的双视角交互图替换为每个用户只有一种表示的传统交互图;
(B) DPGNN w/o QL:将四元损失改为 BPR 损失;
(C) DPGNN w/o SSL:移除双视角对比损失。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢