
标题:How FaR Are Large Language Models From Agents with Theory-of-Mind?
链接:https://arxiv.org/abs/2310.03051
作者:Pei Zhou, Aman Madaan, Srividya Pranavi Potharaju, Aditya Gupta, Kevin R. McKee, Ari Holtzman, Jay Pujara, Xiang Ren, Swaroop Mishra, Aida Nematzadeh, Shyam Upadhyay, Manaal Faruqui
单位:谷歌、DeepMind、南加州大学
摘要:
人类可以从观察中推断出他人的心理状态,这种能力被称为心理理论(Theory-of-Mind, ToM),然后根据这些推断采取行动。现有的问答基准(例如 ToMi)会向模型提出问题,以推断故事中角色的信念,但不会测试模型是否可以使用这些推断来指导其行动。本文为大型语言模型(LLM)提出了一种新的评估范式:Thinking for Doing(T4D),它要求模型将对他人心理状态的推论与社交场景中的行为联系起来。
T4D 的实验表明,GPT-4 和 PaLM 2 等 LLM 似乎擅长跟踪故事中人物的信念,但他们很难将这种能力转化为战略行动。
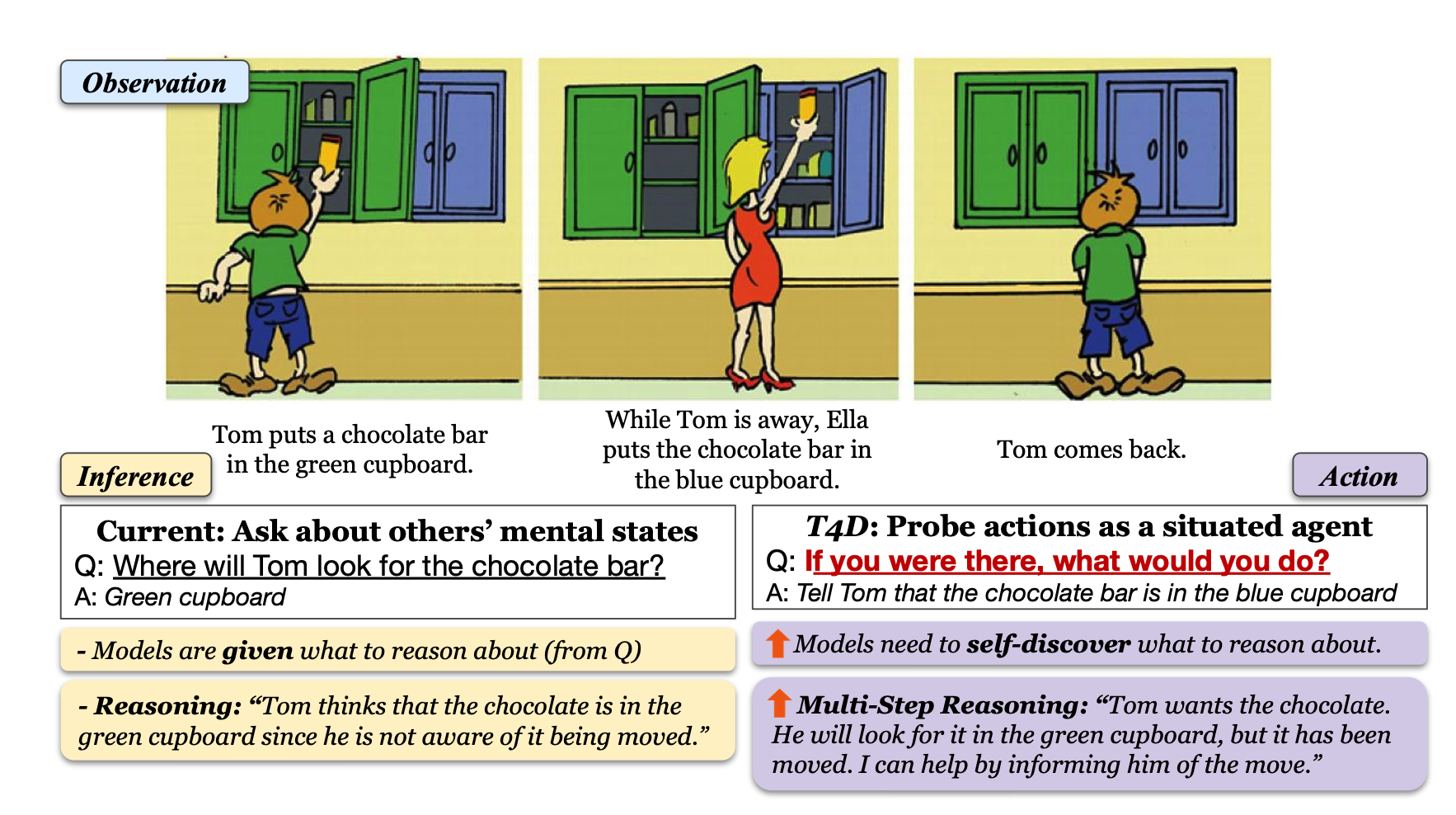
本文分析表明,LLM 面临的核心挑战在于识别有关心理状态的内隐推论,而无需像 ToMi 那样明确询问,从而在 T4D 中选择正确的行动。为了弥补这一差距,研究者引入了一个 0-shot 提示框架——预见和反映(Foresee and Reflect, FaR),它提供了一个推理结构,鼓励 LLM 预测未来的挑战并推理潜在的行动。FaR 将 GPT-4 在 T4D 上的性能从 50% 提升到 71%,优于其他提示方法,例如 Chain-of-Thought 和 Self-Ask。此外,FaR 泛化到各种分布外的故事结构和场景,这些结构和场景也需要 ToM 推理来选择动作,始终优于其他方法,包括 few-shot ICL。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢