

Anima V1 是 CircleStone Labs 于 2026 年发布的动漫风格图像生成模型,专为角色立绘、插画等二次元视觉创作打造。通过文本 Prompt 描述人物细节与光影,即可快速输出精美图像。借助项目集成的 Gradio 交互界面,开发者可以告别繁琐的纯脚本调用,直接在浏览器中调节尺寸、采样步数、CFG 等关键参数,更完美地适配角色设定与概念验证等实务工作流。
目前,HyperAI超神经官网已上线了「Anima V1:动漫风格图像生成」,快来试试吧~
在线使用:https://go.hyper.ai/4PF0Y
欢迎登录官网查看更多内容:
5 月 16 日- 5 月 22 日,hyper.ai 官网更新速览:
* 优质公共数据集:5 个
* 优质教程精选:4 个
* 社区文章解读:4 篇
* 热门百科词条:5 条
* 6 月截稿顶会:4 个
访问官网:hyper.ai
公共数据集精选
1. VisCoR-55K 视觉推理数据集
VisCoR-55K 是由华中科技大学联合阿里云与 2026 年发布的一个高质量视觉推理数据集,该数据集包含约 55,000 个视觉推理样本,每个样本都利用对比样本生成相应的推理过程,涵盖通用、推理、数学、图表及 OCR 五大类别的高质量视觉推理数据集,旨在促进视觉语言模型在可信且稳健的视觉推理方面的研究。
在线使用:https://go.hyper.ai/iQlsz
2. AgentTrove 智能体交互轨迹数据集
AgentTrove 是由 OpenThoughts-Agent 团队发布的大规模开源智能体交互轨迹数据集。该数据集包含 1,696,847 行数据,源自 219 个数据集,涵盖代码修复、 Shell 脚本编写、数学问题解决、编程竞赛及通用计算机使用等任务领域。
在线使用:https://go.hyper.ai/iEMLh
3. Caravan 全球社区大样本水文数据集
Caravan 是一个开放的全球社区大样本水文数据集,该数据集标准化并整合了七个现有的大样本水文数据集,包含全球流域的气象强迫数据、流域属性和流量数据。该数据集包含 6,830 个流域的气象驱动数据、径流数据以及静态流域属性(例如,地球物理、社会、气候属性)。
在线使用:https://go.hyper.ai/OUa2g
4. MemLens 多模态长上下文基准数据集
MemLens 是一个用于评估视觉语言模型长程对话记忆的基准数据集,旨在测试模型在 32K、64K、128K 及 256K 上下文窗口中,检索、回忆、更新及推理跨多会话对话中嵌入的视觉与文本信息的能力。该数据集共包含 789 道题目,涵盖 5 种评估类型:信息提取、知识更新、时序推理、多会话推理与拒绝回答(Abstention),并提供 4 个上下文长度配置(32K /64K/128K/256K)。
在线使用:https://go.hyper.ai/ZR0s9
5. LongBlocks 长上下文多语言问答数据集
LongBlocks 是由里斯本大学、Instituto de Telecomunicações 联合 TransPerfect 等机构于 2026 年发布的一个长上下文多语言合成数据集。该数据集包含约 19.4 万条长上下文问答示例,涵盖书籍、网页文本、Wiki 百科、arXiv 论文、编程代码及社区问答等长文档语料。
在线使用:https://go.hyper.ai/dc0W6
公共教程精选
1. Anima V1:动漫风格图像生成
Anima V1 是 CircleStone Labs 于 2026 年发布的动漫风格图像生成模型,面向角色立绘、插画、概念图和二次元视觉创作等场景。用户可以通过文本 Prompt 描述人物、服饰、姿态、光照和画面氛围,并生成具有动漫审美的图像结果。
在线运行:https://go.hyper.ai/4PF0Y
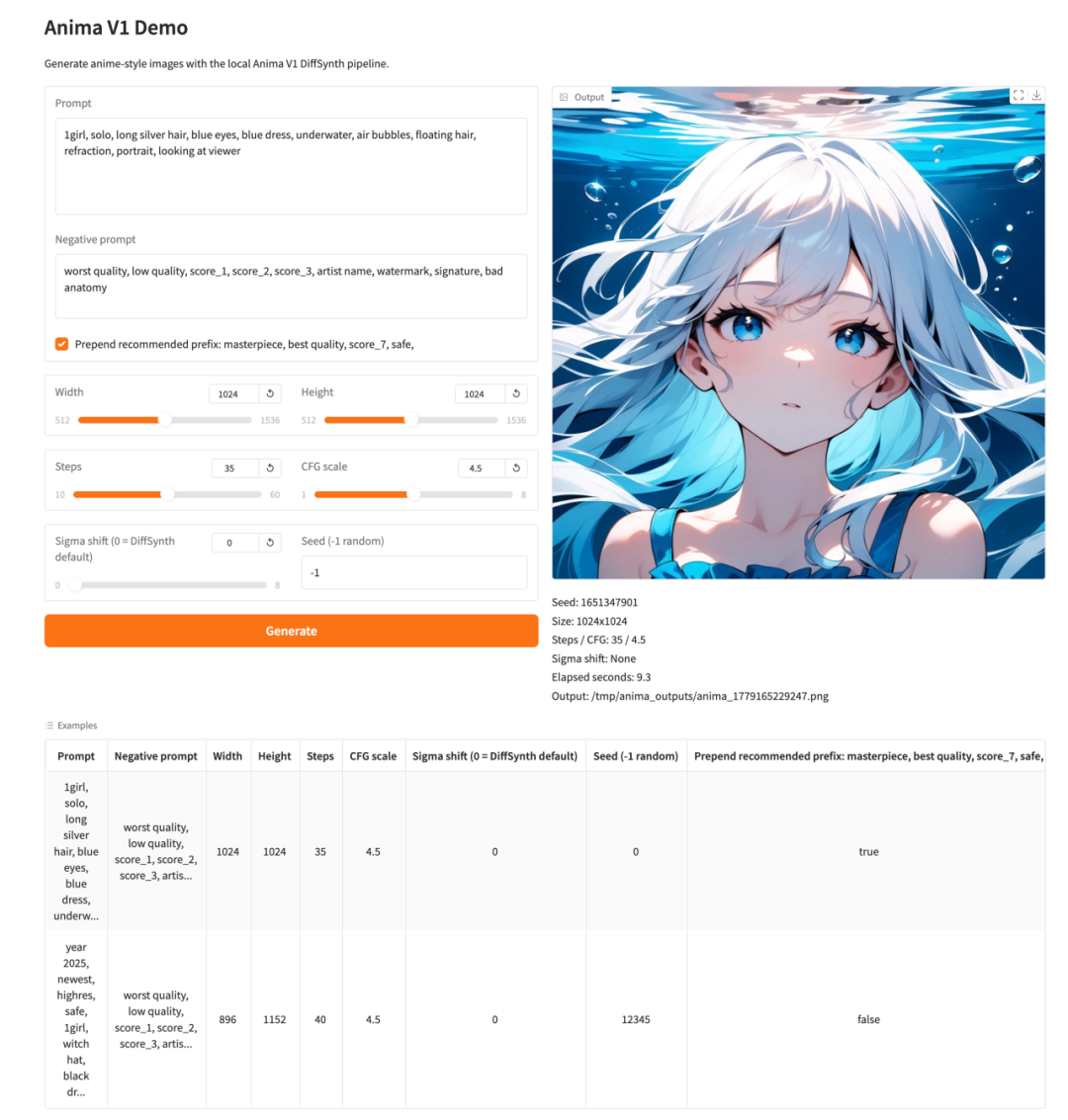
Demo 界面
2. MLSysBook:Co-Labs 交互式实验
MLSysBook 交互式实验是由哈佛大学开发的机器学习系统交互式教学平台。它包含 33 个可直接在浏览器中运行的实验,无需安装任何软件或配置环境。每个实验约需 50 分钟,遵循「预测—发现—解释」的学习循环,引导学习者解决真实的机器学习系统问题。
在线运行:https://go.hyper.ai/0XrSs
Demo 界面
3. Magic-Resume:AI 驱动简历编辑器
Magic Resume 是由 Siyue 于 2025 年开源的免费在线 AI 简历编辑器。该项目并非传统的静态简历模板集合,而是一个面向求职场景的现代化在线简历工作台。它支持实时预览、自动保存、本地存储、自定义主题、暗色模式、响应式布局以及 PDF 导出,用户可以在编辑区填写个人信息、教育经历、项目经历、工作经历等模块,并即时查看最终简历效果。
在线运行:https://go.hyper.ai/oLXO5
Demo 界面
4. Supertonic-3:轻量级本地多语言语音合成系统
Supertonic-3 由 Supertone 团队于 2026 年 5 月发布,是面向本地、离线和端侧场景的轻量级多语言文本转语音模型。官方实现提供了基于 supertonic Python SDK 的高层推理方式,底层通过 ONNX Runtime 执行语音合成,因此适合在CPU环境中完成快速验证与应用原型开发。
在线运行:https://go.hyper.ai/uRYzv
Demo 界面
社区文章解读
1. 精确率达94%,西班牙团队基于YOLO11实现自动化近地天体与卫星条纹检测,连续帧之间稳定识别
西班牙皇家海军学院天文观测站构建的 StreakMind 系统,能够自动识别天文图像中由卫星或小行星拖出的线性轨迹,提取轨迹的长度、位置和方向,为后续的天体测量和数据库入库提供标准化输出。其在独立测试集上,模型对短、中、长拖影均表现可靠,整体精确率达 94%、召回率 97%,110 条真实拖影中成功检出 107 条。
查看完整报道:https://go.hyper.ai/lo6jI
2. 速度提升252倍,斯坦福/UCLA等用LSTM将二阶非线性光学仿真带入毫秒级时代
来自斯坦福大学、加利福尼亚大学洛杉矶分校和 SLAC 国家加速器实验室的团队受先前将循环神经网络(RNNs)应用于光纤脉冲传播研究的启发,提出一项基于长短期记忆网络的代理模型,既能快速且精准地预测 SFG 的输出光场,又能大幅削减运算成本。
查看完整报道:https://go.hyper.ai/7VsCZ
3. 小样本生物医学研究新突破,德国团队基于生成式AI模型实现数据增强,或减少30-50%实验动物用量
德国法兰克福大学与弗劳恩霍夫 ITMP 研究所的联合研究团队研发出 genESOM——基于涌现自组织映射的生成式 AI 模型,专为小样本生物医学数据设计。该模型的核心创新是将结构学习与数据生成过程解耦,通过维度调节阻断误差传播,并引入阴性对照变量实时监控数据生成质量。
查看完整报道:https://go.hyper.ai/4kngS
4. 谷歌全球洪水预报系统最新升级,v2版本可靠预报时长延长6天,精度全面提升
Google Research 的全球洪水预报系统第二版(v2)已正式投入运行,并成为 Google FloodHub 河流预报模块的核心引擎。相比第一版系统,v2 围绕训练数据不足、时序长度受限以及输入数据分布偏移等三大长期制约业务化落地的关键问题提出了系统性的改进方案,显著提升了全球尺度径流预报的稳定性与可靠性。
查看完整报道:https://go.hyper.ai/xI1Xe
热门百科词条精选
1. 智能体记忆 Agent Memory
2. 人机回圈 Human-in-the-loop
3. 联邦学习 Federated Learning
4. 部署中学习 Learning While Deploying
5. 多智能体架构 Multi-Agent Architecture
这里汇编了数百条 AI 相关词条,让你在这里读懂「人工智能」:
6 月截稿顶会
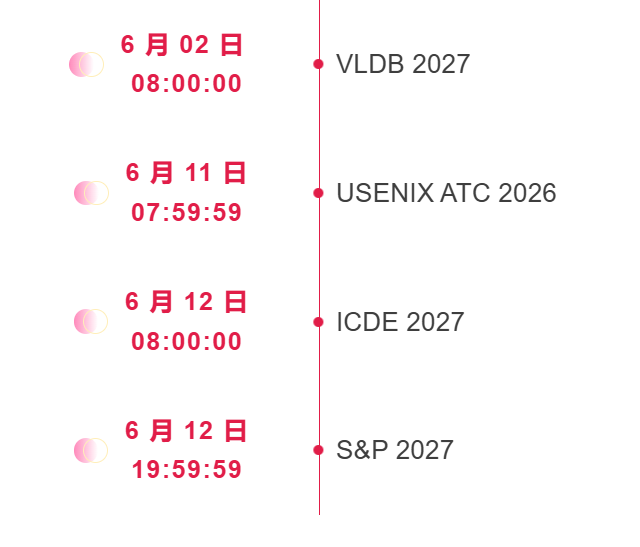
一站式追踪人工智能学术顶会:https://go.hyper.ai/event

以上就是本周编辑精选的全部内容,如果你有想要收录 hyper.ai 官方网站的资源,也欢迎留言或投稿告诉我们哦!
下周再见!
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢