
论文标题:Pix2seq: A Language Modeling Framework for Object Detection
论文链接:https://arxiv.org/abs/2109.10852
作者单位:谷歌大脑
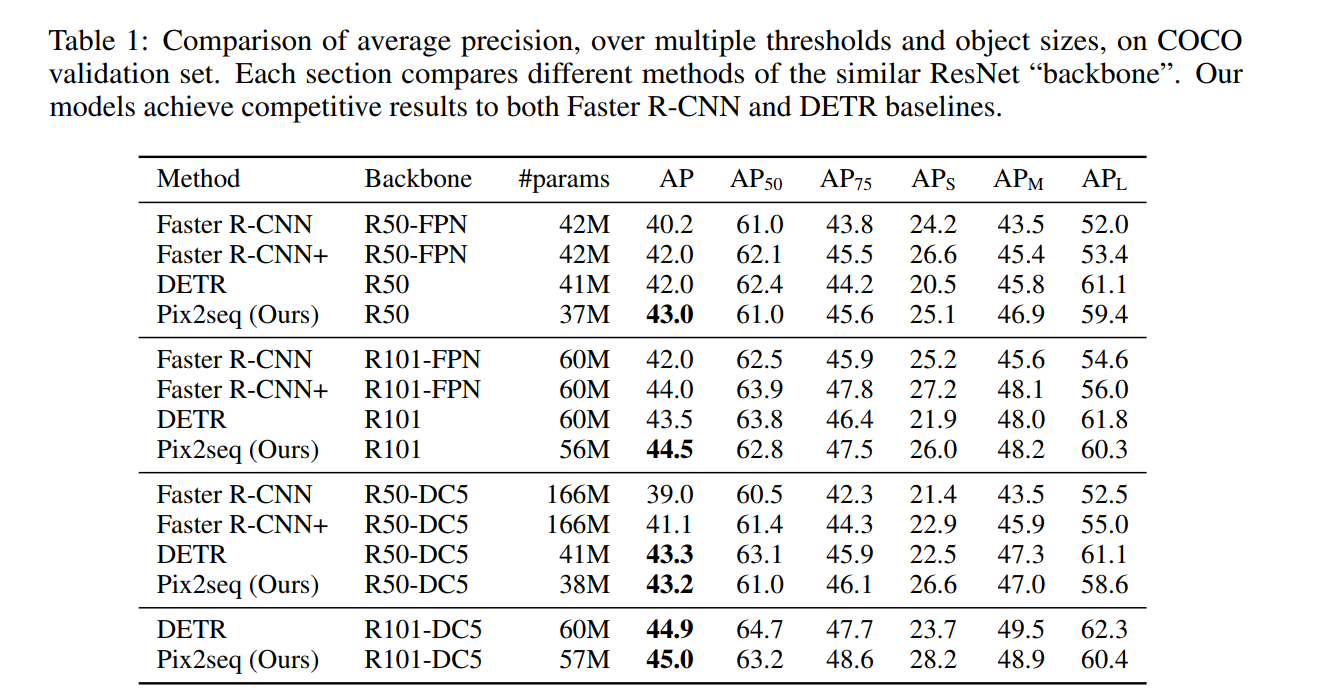
本文介绍了 Pix2Seq,这是一个用于目标检测的简单通用框架。与显式集成有关任务的先验^口识的现有方法 不同,我们简单地将目标检测转换为以观察到的像素输入为条件的语言建模任务。Object descriptions (例 如,边界框和类标签)表示为高散标记序列,我们训练神经网络来感知图像并生成所需的序列。我们的方 法主要基于这样一种直觉,即如杲神经网络知道物体的位置和内容,我们只需要教它如何读取它们。除了 使用特定于任务的数据增强之外,我们的方法对任务做出了最少的假设,但与高度专业化和优化良好的检 测算法相比,它在具有挑战性的COCO数据集上取得了有竞争力的结果。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢