
传统上,大多数深度学习应用在其训练和推理工作负载中多采用32位浮点精度(FP32)。高精度数据格式固然能带来更精确的结果,但囿于系统内存带宽等限制,深度学习在执行操作时,往往易陷入内存瓶颈而影响计算效率。
近年来已有众多研究和实践表明,以较低精度的数据格式进行深度学习训练和推理,并不会对结果的准确性带来太多影响,而低精度数据格式带来的优势,也不仅在于提升内存利用效率,在深度学习常见的乘法运算上,它也能减少处理器资源消耗并实现更高的操作速度(OPS)。
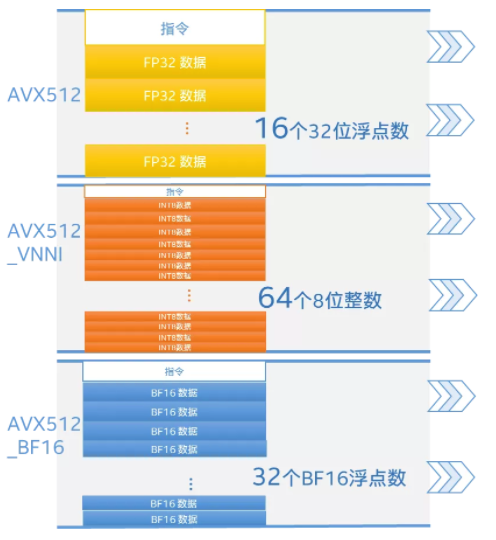
英特尔® 深度学习加速(英特尔® DL Boost)技术的精髓,就是把对低精度数据格式的操作指令融入到了AVX-512指令集中,即AVX-512_VNNI(矢量神经网络指令)和AVX-512_BF16(bfloat16),分别提供了对INT8(主打推理)和BF16(兼顾推理和训练)的支持。
 英特尔® 深度学习加速技术带来训练和推理效率提升
英特尔® 深度学习加速技术带来训练和推理效率提升
2020年问世的第三代英特尔® 至强® 可扩展处理器家族已集成了英特尔® 深度学习加速技术这两种AI加速指令集,并被广泛运用于商业深度学习应用的训练和推理过程。其中,AVX-512_VNNI理论上可使推理效率提升至4倍,而AVX-512_BF16则能帮助训练性能提升达1.93倍。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢