

本文简要介绍TCSVT 2021录用论文:“Text Region Conditional Generative Adversarial Network for Text Concealment in the Wild”的主要工作。该工作针对场景文字擦除的问题,指出用单词级别的边界框来定位文字的区域,会引入过多的背景噪声。因此作者首先采用了字符级的边界框来替代单词级别的边界框,并且提出了一个字符级的对称线表示,去获取更细致的文字区域预测结果。该方法能够帮助网络更关注笔画的像素,而不是背景的像素。
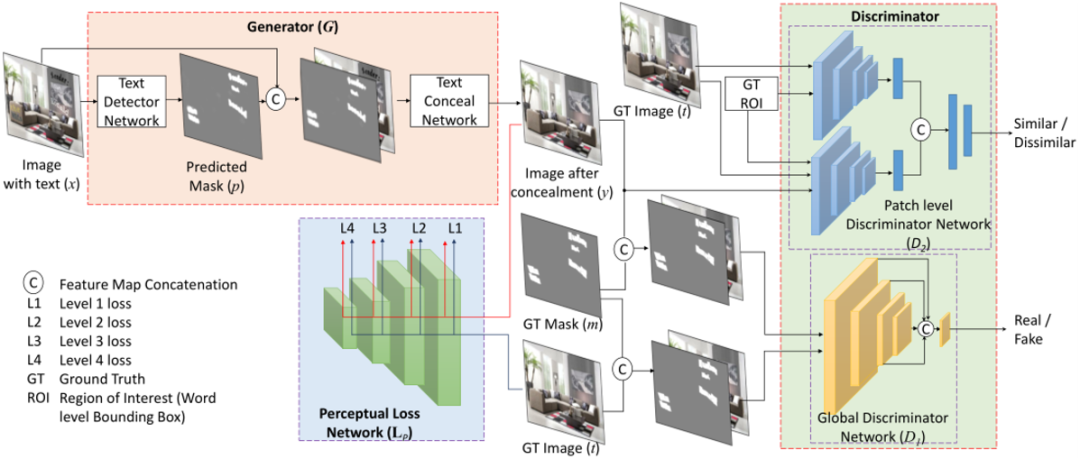
网络的整体框架如上图所示,它由两部分构成:生成器和判别器。生成器负责两个任务,分别是文字检测和文字擦除。其中文字检测网络用于文字区域的分割,文字区域的分割可以帮助擦除网络去区分文字的区域和非文字的区域。判别器由全局判别器(D1)和Patch Level的判别器(D2)构成,全局的判别器用于判断生成图片的真或假,Patch Level的判别器用于确保局部区域的正确性。
论文地址:
https://ieeexplore.ieee.org/abstract/document/9509541
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢