
作者简介:何灏宇,美国东北大学硕士,主要从事自然语言处理方面的研究,目前在Facebook实习。
近年来,“预训练+微调”的方式成为自然语言处理的主流范式,该方法首先利用大规模的无标签数据对模型进行无监督/自监督预训练,然后在下游任务上使用相对少量的标注数据进行微调。该范式在几乎所有的自然语言下游任务上都取得了优异的表现。然而,如何在机器翻译(NMT)中利用好“预训练+微调”的范式仍然是一个值得研究的方向并且仍然存在以下挑战:1) 以BERT为代表的自然语言理解模型只利用编码器(Encoder)去训练模型对语言的表征能力,而一个NMT模型通常是包含编码器(Encoder)和解码器(Decoder)的,这使得对NMT模型进行预训练变得相对困难。2)大部分的预训练模型都是基于单语种(英语等)进行训练,如BERT和GPT,而机器翻译是一个包含多语种的任务。3)自然语言处理中的预训练方法大多关注于文本信息的预训练,如何利用预训练的方法去提升语音翻译(Speech Translation)的表现也是一个挑战。本文将会从单语种、多语种和语音翻译三个方面分别介绍预训练范式在机器翻译任务中取得的进展,同时也解释了现在的方法是怎么样解决以上提到的三个挑战的。
基于单语种语料的预训练
我们知道,单语种的训练数据要比双语种的平行语料多得多,而训练NMT模型时数据量的规模起到了一个非常关键的作用,数据越多,训练的效果越好。因此,研究基于单语种语料的预训练方法在机器翻译中的应用也非常重要。早期的一些方法尝试利用预训练模型的表征向量来初始化NMT模型的表征向量,这样的做法在训练效果上得到了极大的提升,尤其是对于训练数据少的双语数据集,这表明预训练模型的表征向量中蕴含的语义信息或许在NMT模型训练时起到了一定的作用。如果可以用预训练模型的表征向量来做初始化,那么也就一定可以直接用预训练模型本身来作NMT模型的初始化,许多工作探索了如何将预训练模型(BERT)融合进机器翻译模型中。起初的一些研究发现,只用预训练模型的表征向量做初始化甚至比直接将预训练模型初始化为翻译模型的编码器或者解码器结果要更好,因此很多研究的重点是放在如何利用预训练模型的特征上的。比如使用额外的Attention模型将预训练模型(BERT)的特征融合进NMT模型的编码器和解码器中去,这样的方法虽然在结果上取得了一定的提升,但是提升并不大而且还增加了额外的参数量(Attention),如何将预训练模型在机器翻译任务上进行微调依然是一个难点。那么为什么在机器翻译任务上对预训练模型进行微调并不像在其他自然语言任务上那么有效呢?研究发现,机器翻译任务上的微调可能会引发预训练模型的灾难性遗忘(catastrophic forgetting),导致模型最终无法完全利用预训练模型在预训练阶段学习到的知识。
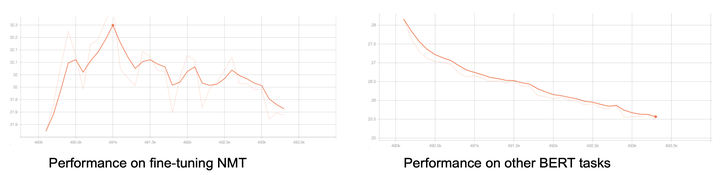
图1: 机器翻译任务的微调导致预训练模型在其他任务上的表现变差,说明在微调过程中可能存在灾难性遗忘的问题。
为了尝试去解决灾难性遗忘的问题,Towards Making the Most of BERT in Neural Machine Translation一文提出了CTNMT的训练框架。该框架利用渐进蒸馏(asymptotic distillation)来防止作为NMT模型编码/解码器的预训练模型丢失大部分的预训练信息;同时利用一个可以学习的门(gate)来动态地控制预训练模型的信息转移过程;此外,对于模型中的不同模块使用不同的学习率进行更新。CTNMT的训练框架使得模型在微调时不会走的太远,从而有效减轻灾难性遗忘的问题。实验结果表明,该框架在多个NMT数据集上都取得了非常大的提升。
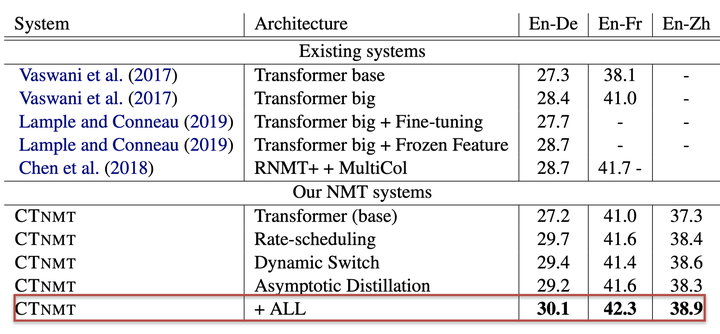
图2: CTNMT训练策略下的BERT base模型结果甚至超过了参数量更多的Transformer big基线模型。
除了将预训练模型融合进NMT模型中,端到端统一预训练模型(MASS,BART等)也被用于机器翻译任务。MASS和BART针对序列到序列的自然语言生成任务而提出了新的预训练方法,这样的预训练模型拥有编码器和解码器并且二者是联合训练的,在模型结构上十分适用于机器翻译任务。同时,这些模型只需要单语数据进行预训练,因此特别适合无监督或者少样本的机器翻译任务,实验结果也证明这两个模型在这一类任务下取得了非常大的提升。然而,不论是预训练模型的融合,还是端到端的统一模型,都是在弱监督或者少量数据的NMT任务上取得进展,并没有在数据丰富的NMT数据集上有所提升。主要原因在于,基于单语种的预训练与机器翻译本身的目标(多语种)是不一致的,因此,对于多语种的预训练模型的研究是非常有必要的。
基于多语种语料的预训练
学习跨语种的知识表示是多语种预训练的目标,目前有两大类方法:多语种融合的预训练(Multilingual Fused Pre-training)和多语种端到端的预训练(Multilingual Sequence to Sequence Pre-training)。多语种融合的预训练主要关注如何使用多语种的平行语料对BERT等预训练模型的预训练任务及训练数据进行改编,从而更好地适应机器翻译任务。由于不同语种之间的训练数据量相差很大,有些语种的语料数据十分缺乏,如果能够促进不同语种之间的知识迁移,那么就可以利用从训练数据较多的语种学到的知识来学习训练数据较少的语种,这也符合人类学习语言的过程。Cross-lingual Language Model Pretraining这一研究提出了几种基于BERT的掩码语言模型(MLM)的预训练任务,这些预训练任务的目标都是在训练时使用多语种的语料并且学习到跨语种的表征能力。实验结果表明,对于机器翻译任务来说,跨语种的预训练是非常有必要的,经过预训练后的模型能够在以往模型的基础上带来巨大提升。同时,预训练也减小了监督学习和无监督学习结果之间的差异,这是单语种预训练模型无法做到的。
Alternating Language Modeling for Cross-Lingual Pre-Training一文基于BERT的掩码语言模型(MLM)预训练任务,提出了适用于机器翻译的交替语言模型(ALM)作为预训练任务。
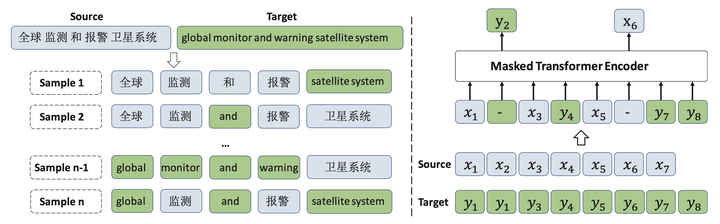
图3: 交替语言模型(ALM)将源语言和目标语言的语句进行混合,训练时模型依然是在做掩码预测,只不过掩码符号不再是特殊符号[MASK],而是另一种语言的语言符号(token)。
这样的预训练任务鼓励模型在预训练阶段就学习多语种之间的相关信息,从而使得模型能够捕捉到大量跨语种的字符和词组之间的上下文语义信息。
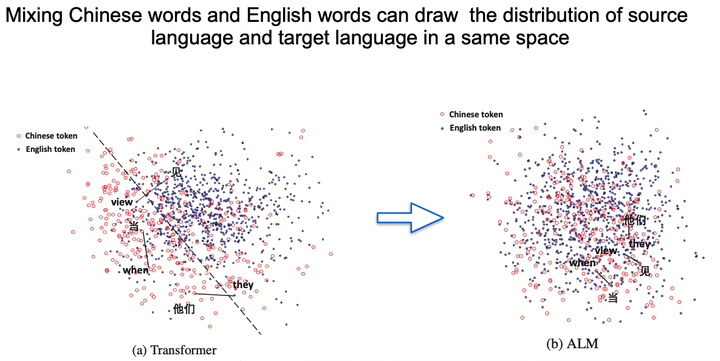
图4: 通过ALM训练的模型能够拉近不同语种(中文,英文)的同义词在向量空间中的距离。
XLM-T: Scaling up Multilingual Machine Translation with Pretrained Cross-lingual Transformer Encoders一文利用了预训练好的多语种语言理解模型XLM-R作为编码器和解码器的初始化模型,该方法在基线的基础上有了很大的提升,同时在数据匮乏(low-resource)的语言对上取得了效果的显著提升。以上这些方法都表明,在机器翻译预训练中,实现跨语种之间的知识迁移是非常有希望的。
对于多语种端到端的预训练,其中比较有代表性的一个系统是mBART。mBART使用BART的训练目标,在多个大规模单语料数据库上进行降噪自编码(denoising auto-encoder)
的预训练,整个训练过程分为预训练和微调两步,在包含了25个不同语言的单语语料的CC25语料库上进行预训练,训练时使用与BART相同的噪声函数。mBART也是第一个对多种语言的完整文本进行降噪来进行预训练的端到端模型。结果表明,这样的训练方式虽然简单,但是非常有效,在数据匮乏的数据集上实现了超过6个点的BLEU值提升,对中等数据量的数据集也有超过3个点的BLEU值提升。同时,研究者还对预训练时语言的数量进行了研究,因为CC25语料库里有25种不同语言的单语语料,研究者建立了利用全部25种语言进行预训练的模型mBERT25,使用六种欧洲语言的子集进行预训练的模型mBERT06,以及只利用两种语言的双语模型mBERT02,实验结果表明,当单语种的数据量比较多时,使用两种语言进行预训练的mBERT02要更好,而对于那些单语种数据量有限的语言,mBERT25能够达到更好的效果。
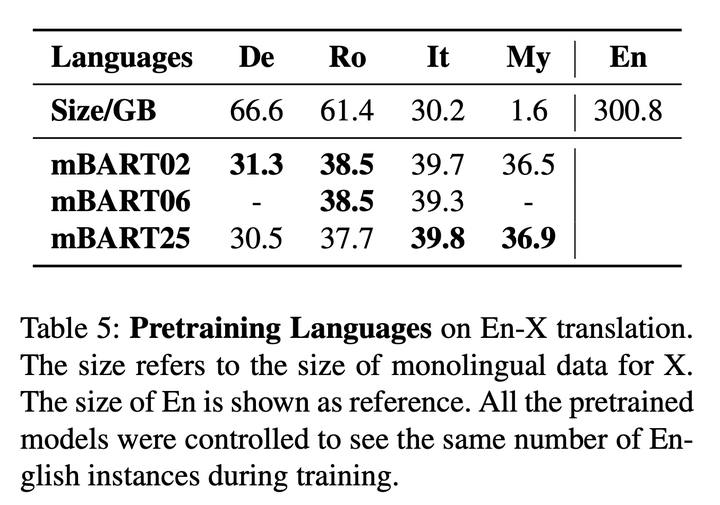
图5: 使用不同数量语种进行预训练的模型mBART02, mBART06和mBART25在语言X-英语的机器翻译设定下的实验结果。
另一个端到端的预训练模型是mRASP,它是基于在平行语料上进行随机对齐变换(Random Aligned Substitution)进行的预训练新范式。随机对齐变换是在预训练阶段随机将原语料中的某个字/词替换成其他语言的同义词,这样的做法能够非常好的学习到多种语言的转换能力,并且尽可能学习到语言的通用表示,将不同语种的语义空间拉近。实验结果表明,mRASP的通用性极强,在数据量多(high-resource)和数据匮乏(low-resource)的数据集上皆都取得了很好的效果。在mRASP的基础上,研究者们提出了mRASP2,该模型利用对比学习(Contrastive Learning)和对齐增强(Aligned Augmentation)的方法,将单语语料和双语语料包含在统一的预训练框架下,从而能够充分利用语料,在有监督、无监督甚至零样本(zero-shot)的任务上都能取得翻译效果的提升。除了mBART和mRASP,还有很多研究探索了不同的端到端训练方法,比如LaSS通过对每个语言对分配专属的子网络来解决灾难性遗忘问题等。
端到端的语音翻译预训练
传统的语音翻译系统是级联的,整个翻译系统分成多个模块:由语音识别ASR模块将语音信号转录为相应的文字作为原文本,再通过机器翻译模型将原文本翻译成目标文本。这种方法有两个缺点,一是多个模块会消耗更多的算力,整个系统的计算效率比较低,二是会出现误差传播的问题,如果ASR识别产生误差那么最后的翻译结果大概率是错误的。为了解决这些问题,研究者们探索了端到端的语音翻译模型,通过一个带有编码器和解码器的单一模型(如Transformer)来实现从语音到文本的直接翻译。这种方法拥有更快的响应速度,更方便部署,并且从根源上避免了误差传播的问题。端到端的语音翻译模型与机器翻译模型的结构非常相似,区别是语音翻译模型在编码器一端的输入是语音信号而机器翻译模型编码器的输入是文本。要实现端到端的语音翻译,目前有几个挑战:首先,缺乏大量的语音-文本的平行语料;其次,语音和文本这两个模态之间有比较大的差异,如何通过端到端的方式融合这两个模态的信号亟待解决;直接进行端到端训练的语音翻译模型与文本机器翻译模型的表现结果具有比较大的差异,这表明端到端的语音翻译还有很大的提升空间。
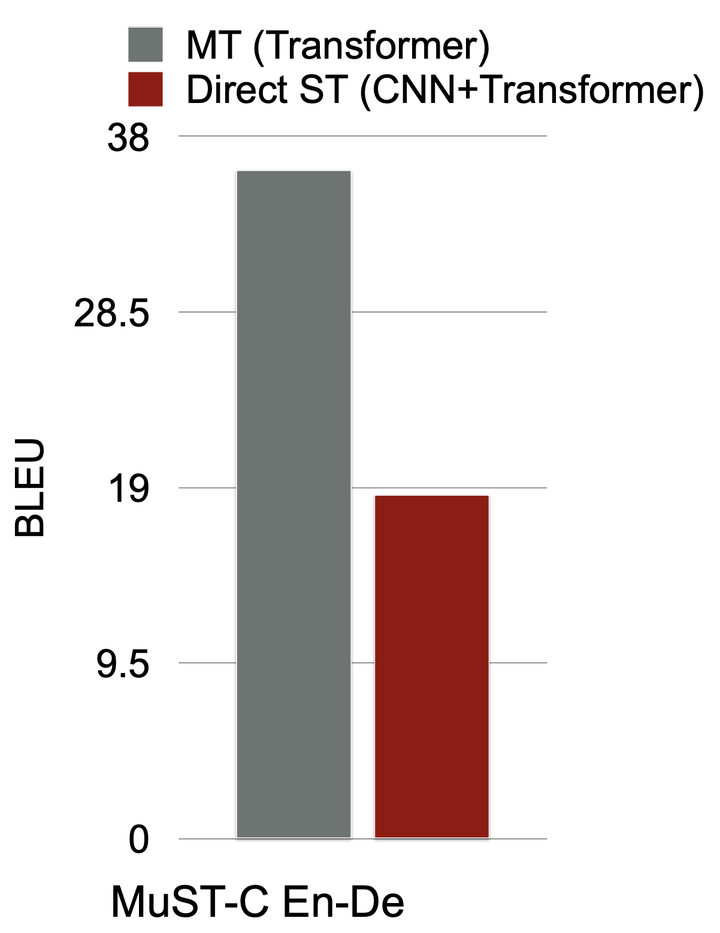
图6: 直接进行端到端训练的语音翻译模型(Direct ST)和机器翻译模型在英文-德语的数据集上的训练结果有比较大的差异。
面对这些挑战,研究者们提出了多种解决方案。比如COSTT、LUT等工作利用大规模的机器翻译单模态语料首先对编码器和解码器分别进行预训练,然后再使用语音翻译的数据去训练/微调整个模型,从而能够更好地利用大规模的机器翻译语料;Wav2Vec2.0使用大量未标记的语音数据进行预训练自监督学习,再使用少量转录数据进行微调;Chimera、XSTNet、FAT-ST等工作通过对模型结构以及训练目标函数进行改进,尝试解决语音和文本两个模态之间的信号差异问题,从而使得语音-文本的平行语料可以直接用于对模型进行端到端的预训练。
当前机器翻译的研究已经克服了大量的挑战,这使得机器翻译系统变得越来越高效,尤其是在低资源的条件下。当然,关于机器翻译仍有许多需要解决的困难与挑战,等待着研究者们的持续探索。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢