

近日,百度强化学习团队联合小度机器人团队,基于飞桨机器人控制算法框架 PaddleRobotics,发布了四足机器人控制的最新进展。该算法首次提出基于自进化的步态生成器来引导强化学习训练,通过自主学习,机器人能探索出合理的步态并穿越各种各样的高难度场景。从零开始学习并掌握多种运动步态,一套算法解决包括独木桥、跳隔板、钻洞穴等多种场景控制难题。百度已开源全部仿真环境和训练代码,并公开相关论文。
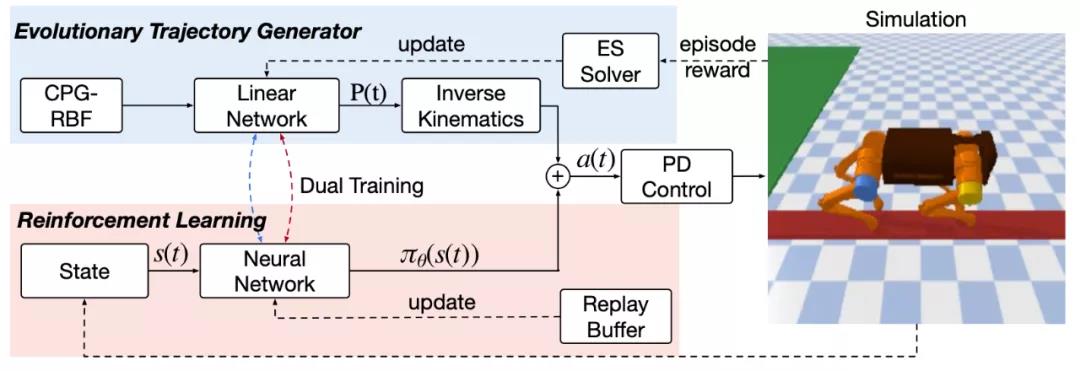
该框架的概览图如上图,算法的控制信号由两部分组成:一个开环的步态生成器以及基于强化学习的神经网络。
步态生成器可以提供步态先验来引导强化学习进行训练,首次提出在轨迹空间直接进行搜索的自进化步态生成器优化方式。相比在参数空间进行搜索的方式,它可以更高效地搜索到合理的轨迹,因为在参数层面进行扰动很可能生成完全不合理的轨迹,并且搜索的参数量也大很多。
强化学习部分的训练通过目前主流的 SAC 连续控制算法进行参数更新,在优化过程中,强化学习的策略网络需要输出合理的控制信号去结合开环的控制信号,以获得更高的奖励。需要注意的是,该框架在更新过程中,是采用交替训练的方式,即独立更新步态生成器以及神经网络。
最后,为了提升样本的有效利用率,该框架还复用了进化算法在优化步态生成器的数据,将其添加到强化学习的训练数据中。百度基于开源的 pybullet 构建了 9 个实验场景,包括了上下楼梯、斜坡、穿越不规整地形、独木板、洞穴、跳跃隔板等场景。其算法效果与经典的开环控制器、强化学习算法相比,提升相当大。
百度的工作展现出,基于自主学习的方法在四足机器人控制上具有完全替代甚至超越经典算法的潜力,有可能成为强化学习和进化学习在复杂非线性系统中开始大规模落地和实用化的契机。
完整仿真效果和真机视频:https://www.bilibili.com/video/BV1a44y1b7nQ
论文:https://arxiv.org/abs/2109.06409
强化学习框架 PARL:https://github.com/PaddlePaddle/PARL
开源仿真环境 RLSchool:https://github.com/PaddlePaddle/RLSchool
飞桨机器人控制算法框架 PaddleRobotics:https://github.com/PaddlePaddle/PaddleRobotics
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢