
预训练模型在计算机视觉和语言上都取得了显著成果,但这些语言模型有一个大问题就是训练过程和推理过程不匹配。清华大学孙茂松团队提出了一个全新的微调框架CPT,用颜色来遮蔽、融合图像和语言,准确率提升17.3%,标准差降低73.8%!
清华大学的研究人员提出了一个新模型跨模态提示调节(Cross-Modal Prompt Tuning, CPT),也可以称为Colorful Prompt Tuning。CPT是一种调整VL-PTM参数的新范式,关键点在于通过在图像和文本中添加基于颜色的共同参照标记,视觉基础可以重新形成填补空白的问题,最大限度地减少预训练和微调之间的差距。

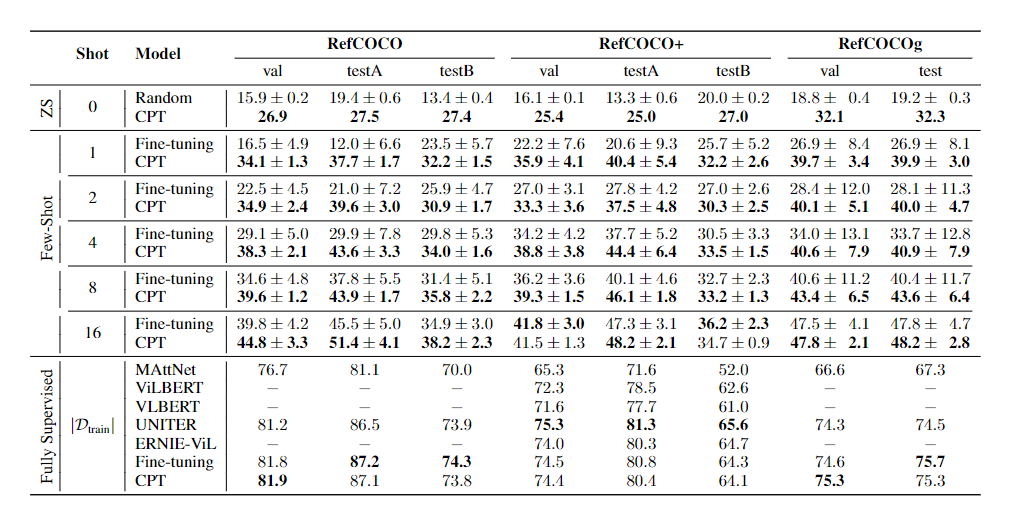
实验结果表明,提示微调后的 VL-PTM的性能大大优于微调后的PTM,
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢