
【论文标题】A Legal Approach to Hate Speech: Operationalizing the EU's Legal Framework against the Expression of Hatred as an NLP Task
【作者团队】Frederike Zufall, Marius Hamacher, Katharina Kloppenborg, Torsten Zesch
【发表时间】2021/10/05
【机 构】马普所、早稻田大学等
【论文链接】https://arxiv.org/abs/2004.03422v3
【代码链接】 https://github.com/smiles724/3D-Transformer
本文提出了一种检测仇恨言论的 "法律方法",将决定一个帖子是否受刑事法律约束的任务操作化为一个NLP任务。比较现有的仇恨言论的监管制度,本文的工作以欧盟的框架为基础,因为它提供了一个广泛适用的法律最低标准。准确判断一个帖子是否应受惩罚,通常需要法律培训。本文表明,通过将法律评估分解成一系列更简单的子决定,即使是外行也能一致地进行注释。基于一个新的注释数据集,本文的实验表明,直接学习一个可惩罚内容的自动模型是具有挑战性的。然而,学习 "目标群体 "和 "目标行为 "这两个子任务,而不是端到端的可惩罚性方法,会产生更好的结果。总的来说,本文的方法还提供了比端到端模型更透明的决定,这是法律决策中的一个关键点。
为了研究本文的注释数据在多大程度上可以作为自动检测的基础,本文训练了一个基线分类器,将一个帖子作为输入,并估计该帖子是否应受惩罚。对于模型的训练,注释者之间的分歧由法律专家来裁定。
近年来微调的BERT模型已被证明是各种NLP任务的强大基线,因此本文遵循这种做法13,使用GBERT-base(Chan et ak,2020)。该模型使用16 batch大小和NLL loss训练了20个epochs。对于优化,本文选择Adam(学习率为2e-5。在训练的前10%期间,学习率线性上升至峰值,然后线性下降。这些选择遵循了Mosbach等人关于在微调BERT时增加训练稳定性的建议。为了评估,本文进行了分层的10-foldCV。
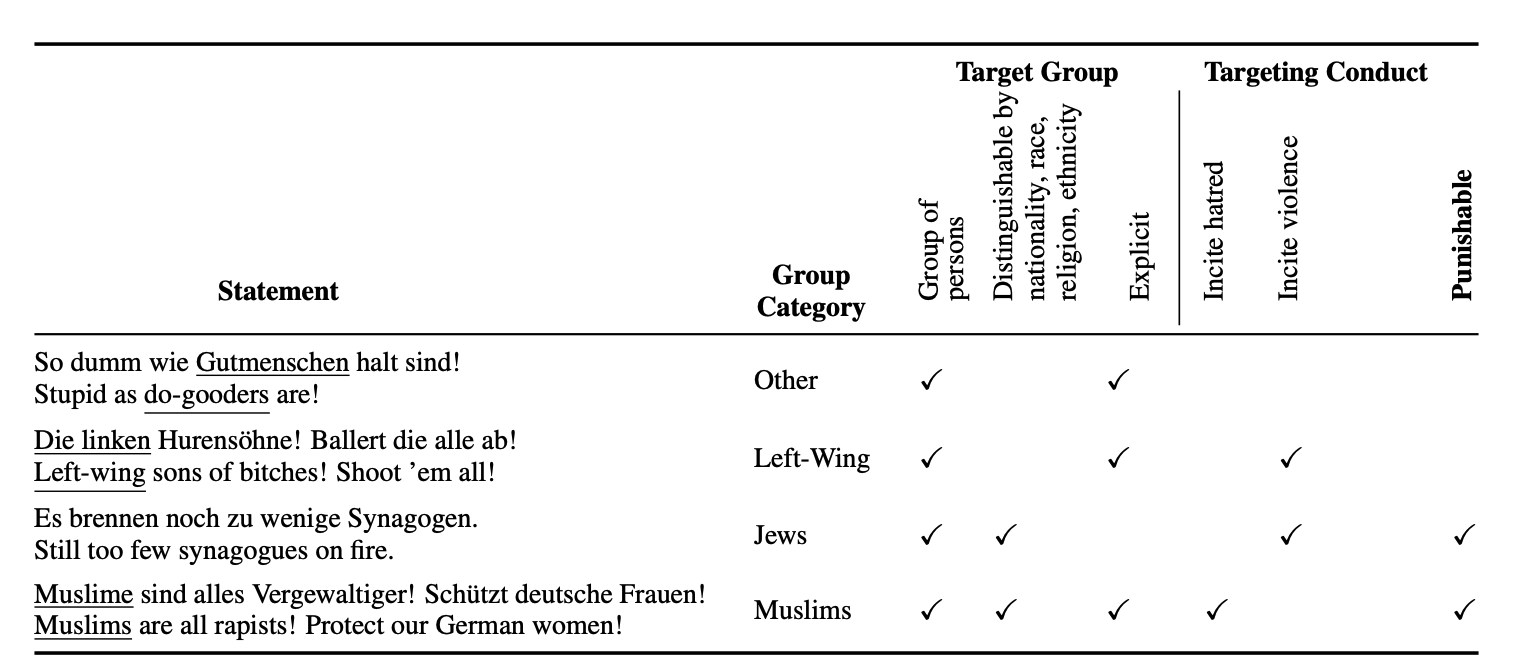
上图展示了数据集的注释实例和判定结果,参考群体用下划线表示。
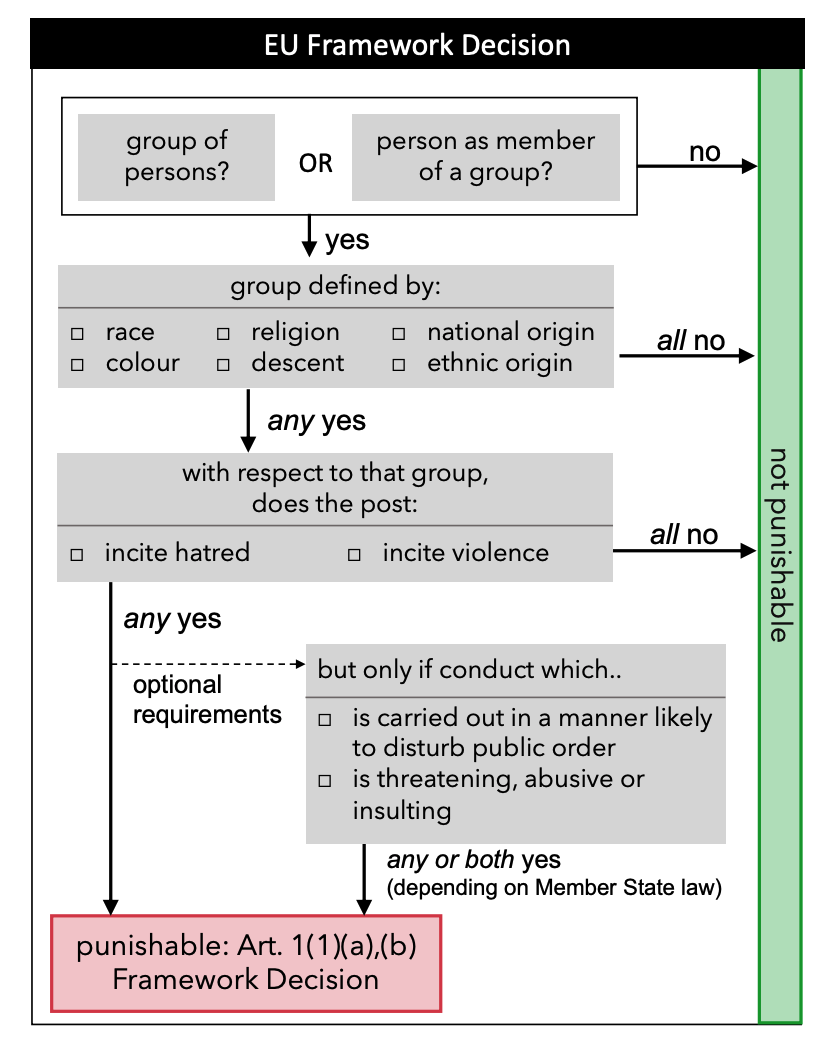
上图展示了根据法律体系所制定的辅助判定是否Punish的决策树。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢