
【标题】Online Robust Reinforcement Learning with Model Uncertainty
【作者团队】Yue Wang, Shaofeng Zou
【论文链接】https://arxiv.org/pdf/2109.14523.pdf
【发表日期】2021.9.29
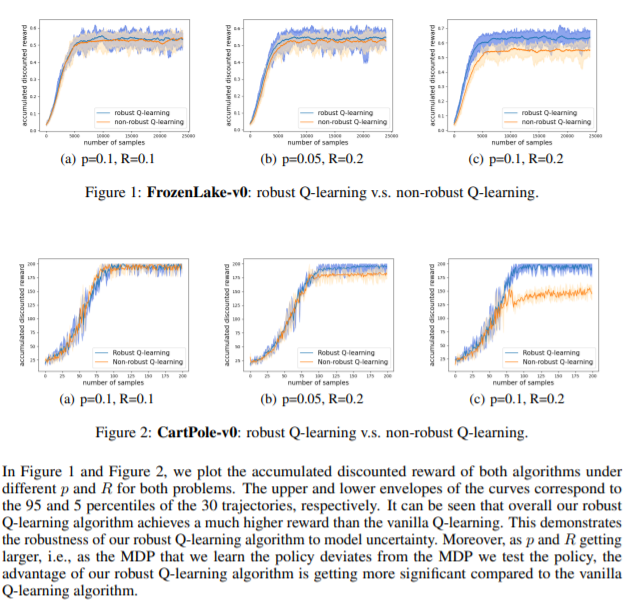
【推荐理由】鲁棒强化学习(RL)是在不确定的MDP集上找到一种优化最坏情况性能的策略。本文聚焦于无模型鲁棒RL,其中不确定性集被定义为以错误指定的MDP为中心,该MDP顺序生成单个样本轨迹,并假设为未知。通过基于样本的方法来估计未知不确定性集,并设计了一种鲁棒Q-学习算法(表格形式)和鲁棒TDC算法(函数近似设置),该算法可以在线和增量方式实现。对于鲁棒Q-学习算法,本文证明了它收敛到最优鲁棒Q函数,对于鲁棒TDC算法,本文证明了它渐近收敛到一些平稳点。该算法不需要任何额外的贴现因子条件来保证收敛性。数值实验进一步证明了算法的鲁棒性。该方法可以很容易地扩展到许多其他算法,例如TD、SARSA和其他GTD算法。


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢