
Adobe Research 的研究人员提出一种针对以人为主体的视频的自动高亮集锦生成的方法,在无需任何人工注释和用户偏好信息来完成训练的前提下,该方法比现有最优方法在匹配人工注释的准确度上提升了 4%~12%。
 论文链接:https://arxiv.org/pdf/2110.01774.pdf
论文链接:https://arxiv.org/pdf/2110.01774.pdf
在这篇论文中,我们提出了一种领域和用户偏好无关的方法来检测以人为中心的视频中的高亮片段。我们使用基于图表达的方法作为视频中多个可观察到的以人为中心的模式,如姿势和面孔。我们使用一个配备了时空图卷积的自动编码器网络来检测基于这些模式的人类活动和交互。我们基于帧的代表性训练我们的网络,从而将不同模式的基于活动和交互的潜在结构表示映射到每帧的高亮得分。我们使用这些分数来计算突出哪些帧,并结合相邻帧来产生摘录。我们在大规模动作数据集 AVA-Kinetics 上训练我们的网络,并在 DSH、TVSum、PHD 和 SumMe 四个基准视频高亮数据集上评估网络。在这些数据集中,与最先进的方法相比,我们在不需要任何用户偏好信息或对新数据集调参的情况下在匹配人工标注的高亮上的平均精度上提高了 4%-12%。
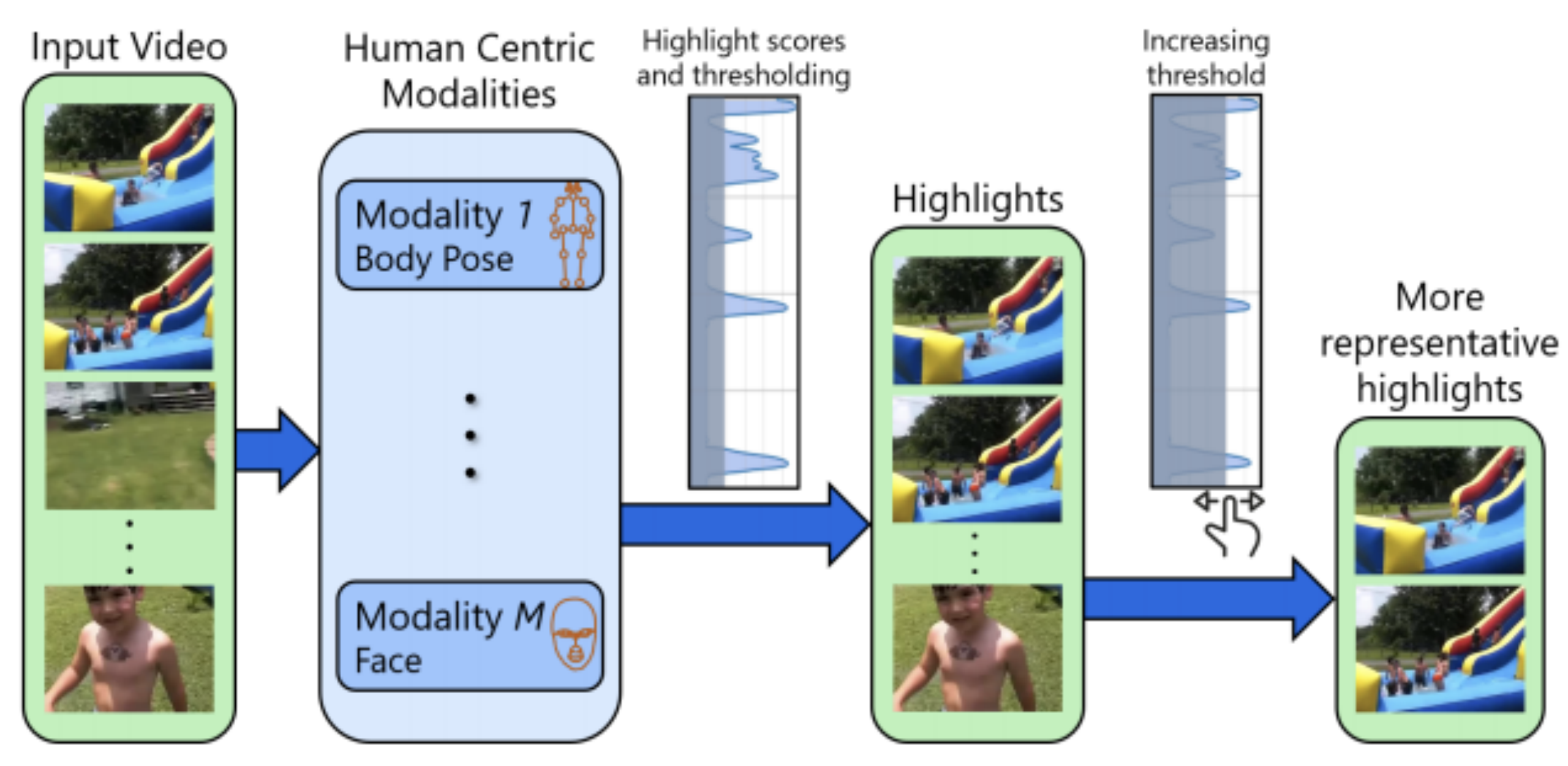 图 1:使用以人为中心的模式检测高亮摘录。我们的方法利用了多种以人为中心的模式以检测亮点,例如,可以在关注人类活动的视频中观察到的身体姿势和面部。我们使用每个模态的二维或三维互联点表示来构建一个时空图表示来计算高亮分数。
图 1:使用以人为中心的模式检测高亮摘录。我们的方法利用了多种以人为中心的模式以检测亮点,例如,可以在关注人类活动的视频中观察到的身体姿势和面部。我们使用每个模态的二维或三维互联点表示来构建一个时空图表示来计算高亮分数。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢