
一篇正在盲审中的ICLR 2022论文引起关注。特斯拉 AI 高级总监 Andrej Karpathy 在Twitter上感叹道:我被新的 ConvMixer 架构震撼了。
文章的摘要中提到:
尽管多年来卷积网络一直是视觉任务的主要架构,但最近的实验表明,基于 Transformer 的模型,尤其是 Vision Transformer (ViT),在某些情况下可能会超过其性能。然而,由于 Transformer 中自注意力层的二次运行时间,ViT 需要使用补丁(Patches)嵌入,将图像的小区域组合成单个输入特征,以便应用于更大的图像尺寸。这就提出了一个问题:ViT 的性能是由于其固有的更强大的 Transformer 架构,还是至少部分是由于使用补丁作为输入表示?
在本文中,我们为后者提供了一些证据:具体而言,我们提出了 ConvMixer,这是一个极其简单的模型,在精神上与 ViT 和更基本的 MLP-Mixer 相似,因为它直接将补丁作为输入进行操作,分离空间和通道维度的混合,并在整个网络中保持相同的大小和分辨率。然而,相比之下,ConvMixer 仅使用标准卷积来实现混合步骤。尽管它很简单,但我们表明,除了优于 ResNet 等经典视觉模型之外,ConvMixer 在类似的参数计数和数据集大小方面也优于 ViT、MLP-Mixer 及其一些变体。
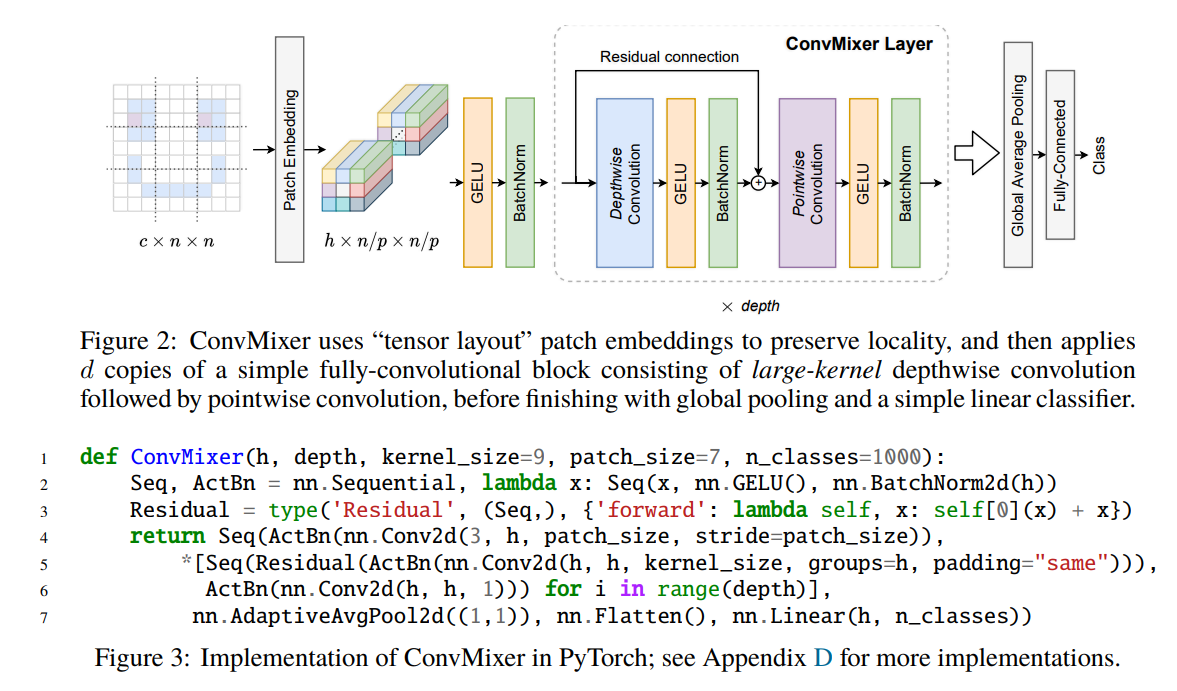
这个工作的价值可能不在于架构本身,而是预示着:更强大的新架构可能要诞生了。
有意思的是,论文中标题是这样的:

论文代码可在 https://github.com/tmp-iclr/convmixer 获得。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢