

论文链接:https://arxiv.org/pdf/2105.03245.pdf
代码和预训练模型:https://github.com/blackfeather-wang/AdaFocus
B站视频简介:https://www.bilibili.com/video/BV1vb4y1a7sD/

现有高效视频识别算法往往关注于降低视频的时间冗余性(即将计算集中于视频的部分关键帧),如图1 (b)。本文则发现,降低视频的空间冗余性(即寻找和重点处理视频帧中最关键的图像区域),如图1 ©,同样是一种效果显著、值得探索的方法;且后者与前者有效互补(即完全可以同时建模时空冗余性,例如关注于关键帧中的关键区域),如图1 (d)。在方法上,本文提出了一个通用于大多数网络的AdaFocus框架,在同等精度的条件下,相较AR-Net (ECCV-2020)将计算开销降低了2.1-3.2倍,将TSM的GPU实测推理速度加快了1.4倍。
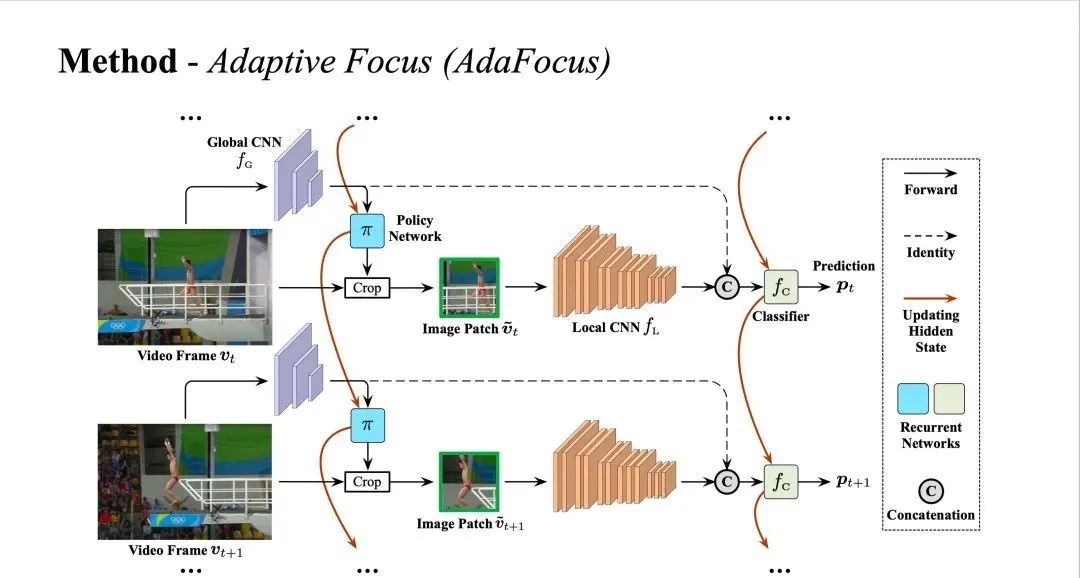
图 AdaFocus 网络结构
 图 AdaFocus与现有方法的对比
图 AdaFocus与现有方法的对比
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢