
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
转自:爱可可爱生活
1、[CV] ADOP: Approximate Differentiable One-Pixel Point Rendering
D Rückert, L Franke, M Stamminger
[University of Erlangen-Nuremberg]
ADOP:近似可微单像素点渲染。本文提出一种新的基于点的可微神经渲染管线,用于场景细化和新视图合成。其输入是对点云和相机参数的初始估计。输出是来自任意相机位置的合成图像。点云渲染是由一个用多分辨率单像素点栅格化的可微渲染器进行的。离散栅格化的空间梯度是由新的ghost几何概念来近似的。渲染后,神经图像金字塔通过一个深度神经网络进行阴影计算和孔洞填充。一个可微的、基于物理的色调映射器将中间输出转换为目标图像。由于管线的所有阶段都可微,优化了场景所有参数,即相机模型、相机姿势、点位置、点颜色、环境图、渲染网络权重、渐晕、相机响应函数、每张图像的曝光和每张图像的白平衡。所提出系统能比现有方法合成更清晰、更一致的新视图,因为初始重建在训练中得到了完善。高效的但像素点栅格化使我们能够使用任意的相机模型,并实时显示超过1亿个点的场景。
We present a novel point-based, differentiable neural rendering pipeline for scene refinement and novel view synthesis. The input are an initial estimate of the point cloud and the camera parameters. The output are synthesized images from arbitrary camera poses. The point cloud rendering is performed by a differentiable renderer using multi-resolution one-pixel point rasterization. Spatial gradients of the discrete rasterization are approximated by the novel concept of ghost geometry. After rendering, the neural image pyramid is passed through a deep neural network for shading calculations and hole-filling. A differentiable, physically-based tonemapper then converts the intermediate output to the target image. Since all stages of the pipeline are differentiable, we optimize all of the scene’s parameters i.e. camera model, camera pose, point position, point color, environment map, rendering network weights, vignetting, camera response function, per image exposure, and per image white balance. We show that our system is able to synthesize sharper and more consistent novel views than existing approaches because the initial reconstruction is refined during training. The efficient one-pixel point rasterization allows us to use arbitrary camera models and display scenes with well over 100M points in real time.
https://weibo.com/1402400261/KCMqcyOA7




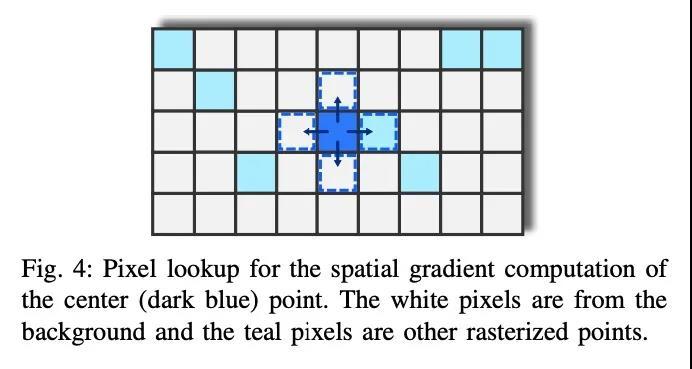
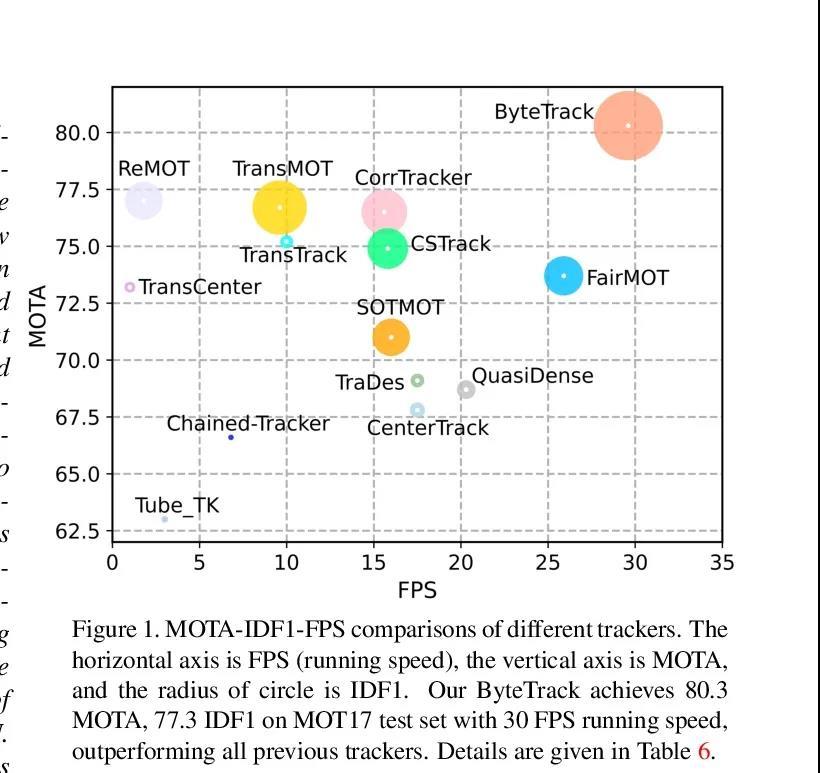
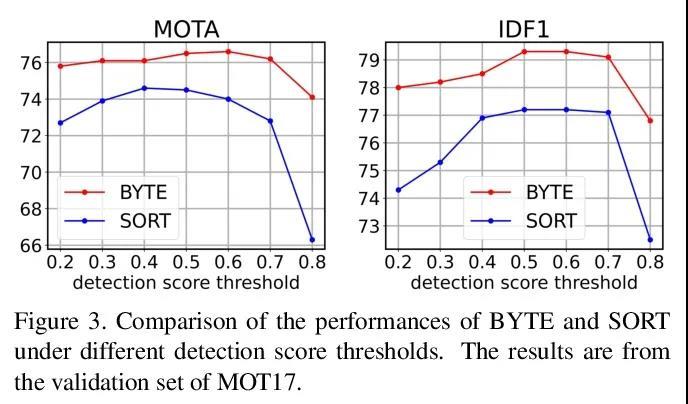
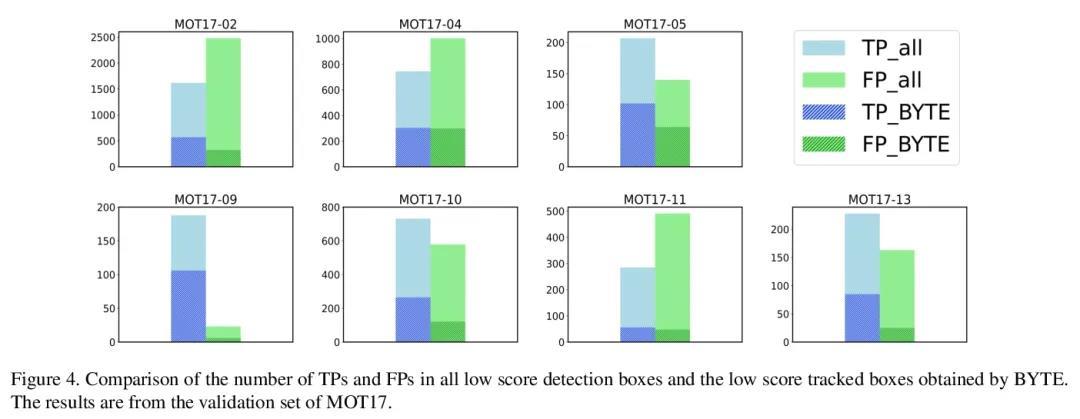
2、[CV] ByteTrack: Multi-Object Tracking by Associating Every Detection Box
Y Zhang, P Sun, Y Jiang, D Yu, Z Yuan, P Luo, W Liu, X Wang
[Huazhong University of Science and Technology & The University of Hong Kong & ByteDance]
ByteTrack: 基于全检测框关联的多目标追踪。多物体追踪(MOT)的目的是估计视频中目标的边框和身份。大多数方法通过关联分数高于阈值的检测框来获得身份。检测分数低的物体,例如被遮挡的物体,会被简单丢弃,这就带来了不可忽略的真实目标缺失和碎片化的轨迹。为解决这个问题,本文提出一种简单、有效和通用的关联方法BYTE,基于每检测框关联的追踪,而不是只关联高分的检测框。对于低分的检测框,利用它们与tracklets的相似性来恢复真正的目标并过滤掉背景检测。将BYTE应用于9个不同的最先进的追踪器,并在IDF1得分上取得了1到10分的一致改进。为了展示MOT的先进性能,设计了一个简单而强大的追踪器ByteTrack。首次在单台V100 GPU上以30 FPS的运行速度在MOT17的测试集上取得了80.3 MOTA、77.3 IDF1和63.1 HOTA,在所有跟踪器中排名第一。由于其准确的检测性能和关联低分检测框的帮助,ByteTrack对遮挡非常鲁棒。
Multi-object tracking (MOT) aims at estimating bounding boxes and identities of objects in videos. Most methods obtain identities by associating detection boxes whose scores are higher than a threshold. The objects with low detection scores, e.g. occluded objects, are simply thrown away, which brings non-negligible true object missing and fragmented trajectories. To solve this problem, we present a simple, effective and generic association method, called BYTE, tracking BY associaTing Every detection box instead of only the high score ones. For the low score detection boxes, we utilize their similarities with tracklets to recover true objects and filter out the background detections. We apply BYTE to 9 different state-of-the-art trackers and achieve consistent improvement on IDF1 score ranging from 1 to 10 points. To put forwards the state-of-theart performance of MOT, we design a simple and strong tracker, named ByteTrack. For the first time, we achieve 80.3 MOTA, 77.3 IDF1 and 63.1 HOTA on the test set of MOT17 with 30 FPS running speed on a single V100 GPU. The source code, pre-trained models with deploy versions and tutorials of applying to other trackers are released at https://github.com/ifzhang/ByteTrack.
https://weibo.com/1402400261/KCMucyjZj

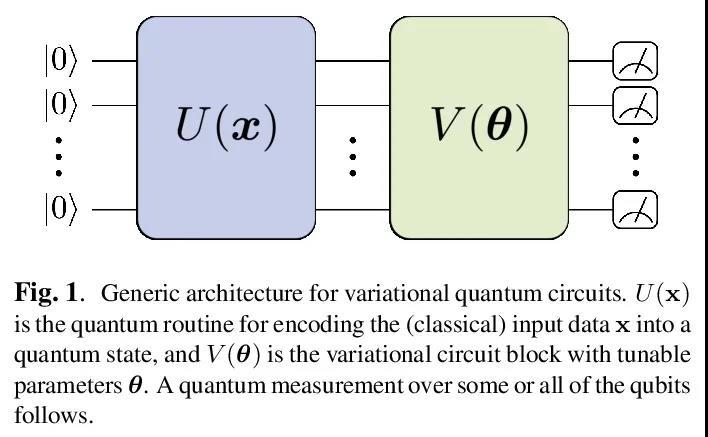
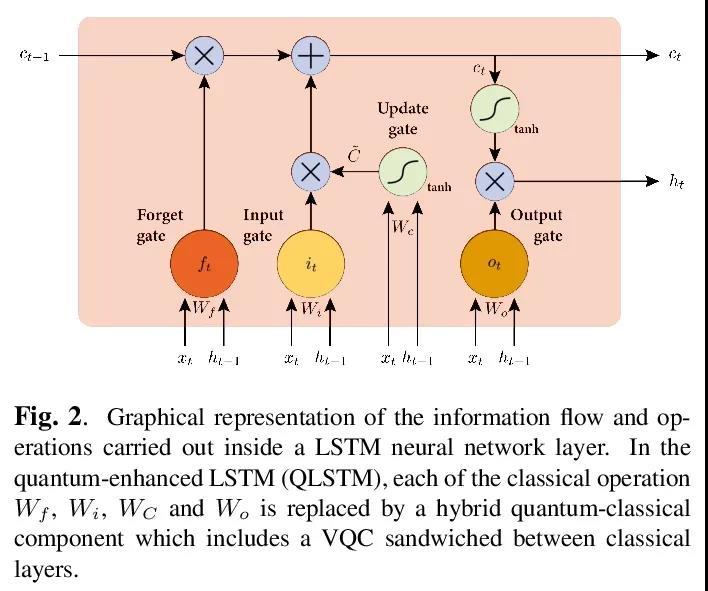
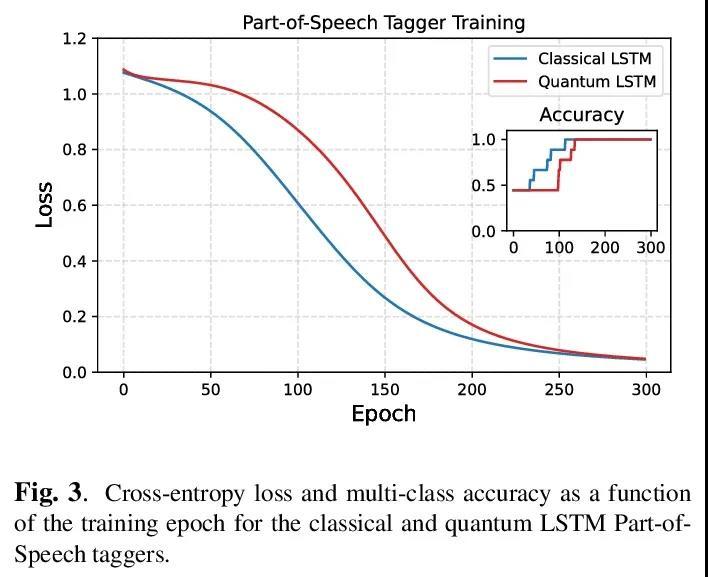
3、[CL] The Dawn of Quantum Natural Language Processing
R D Sipio, J Huang, S Y Chen, S Mangini, M Worring
[Ceridian HCM Inc & University of Amsterdam & Brookhaven National Laboratory & University of Pavia]
量子自然语言处理的曙光。本文讨论了用量子计算提升基于深度学习模型的人类语言理解的初步尝试。通过数值模拟成功训练了一个量子增强的长短时记忆网络,来执行词性标记任务。此外,还提出了一个量子增强的Transformer来执行基于现有数据集的情感分析。
In this paper, we discuss the initial attempts at boosting understanding human language based on deep-learning models with quantum computing. We successfully train a quantumenhanced Long Short-Term Memory network to perform the parts-of-speech tagging task via numerical simulations. Moreover, a quantum-enhanced Transformer is proposed to perform the sentiment analysis based on the existing dataset.
https://weibo.com/1402400261/KCMyzqOcs

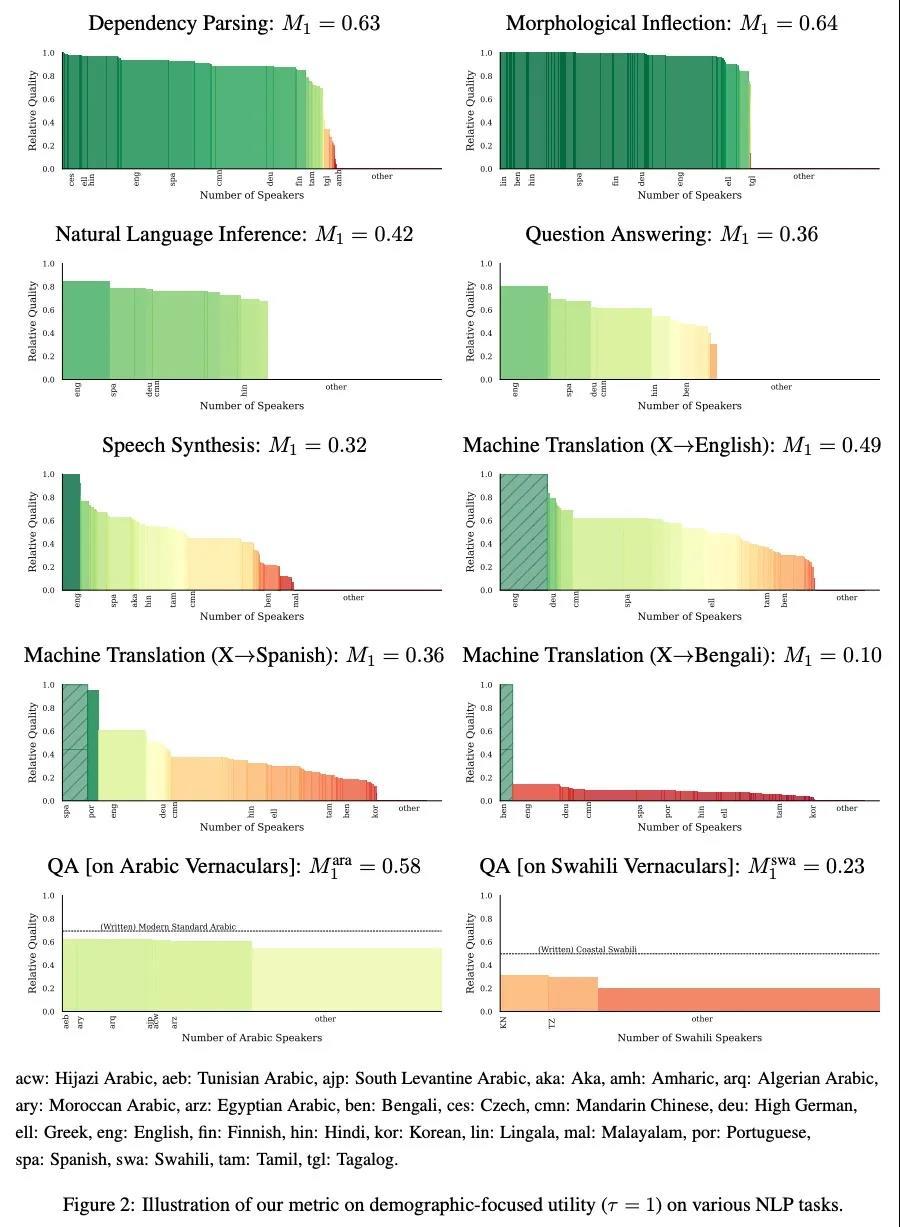
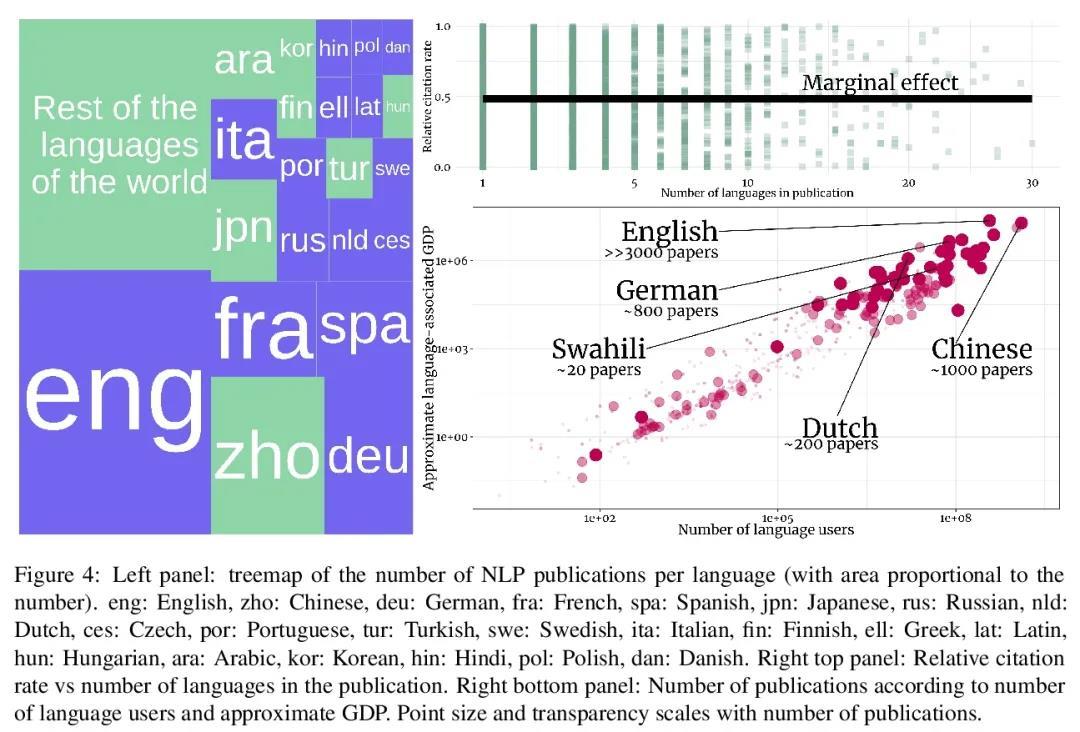
4、[CL] Systematic Inequalities in Language Technology Performance across the World's Languages
D Blasi, A Anastasopoulos, G Neubig
[Harvard University & George Mason University & CMU]
世界上各种语言的语言技术性能存在系统性的不平等。自然语言处理(NLP)系统已经成为通信、教育、医学、人工智能和许多其他研究和发展领域的核心技术。虽然NLP方法的性能在过去的十年里有了很大的提高,但这种进步只限于世界上6500种语言中的一个小部分。本文引入一个框架来估计语言技术的全球效用,体现在最近NLP出版物的综合快照中。本分析不仅涉及整个领域,还包括对面向用户的技术(机器翻译、语言理解、问题回答、文本到语音合成)以及更多的语言学NLP任务(依存分析、形态学还原)的深入研究。在此过程中,(1)量化了NLP研究现状的差异,(2)探讨了一些相关的社会和学术因素,以及(3)为基于证据的政策制定提出了有针对性的建议,旨在促进更加全球化和公平的语言技术。
Natural language processing (NLP) systems have become a central technology in communication, education, medicine, artificial intelligence, and many other domains of research and development. While the performance of NLP methods has grown enormously over the last decade, this progress has been restricted to a minuscule subset of the world’s 6,500 languages. We introduce a framework for estimating the global utility of language technologies as revealed in a comprehensive snapshot of recent publications in NLP. Our analyses involve the field at large, but also more in-depth studies on both user-facing technologies (machine translation, language understanding, question answering, text-to-speech synthesis) as well as more linguistic NLP tasks (dependency parsing, morphological inflection). In the process, we (1) quantify disparities in the current state of NLP research, (2) explore some of its associated societal and academic factors, and (3) produce tailored recommendations for evidencebased policy making aimed at promoting more global and equitable language technologies.1
https://weibo.com/1402400261/KCMFib5TD



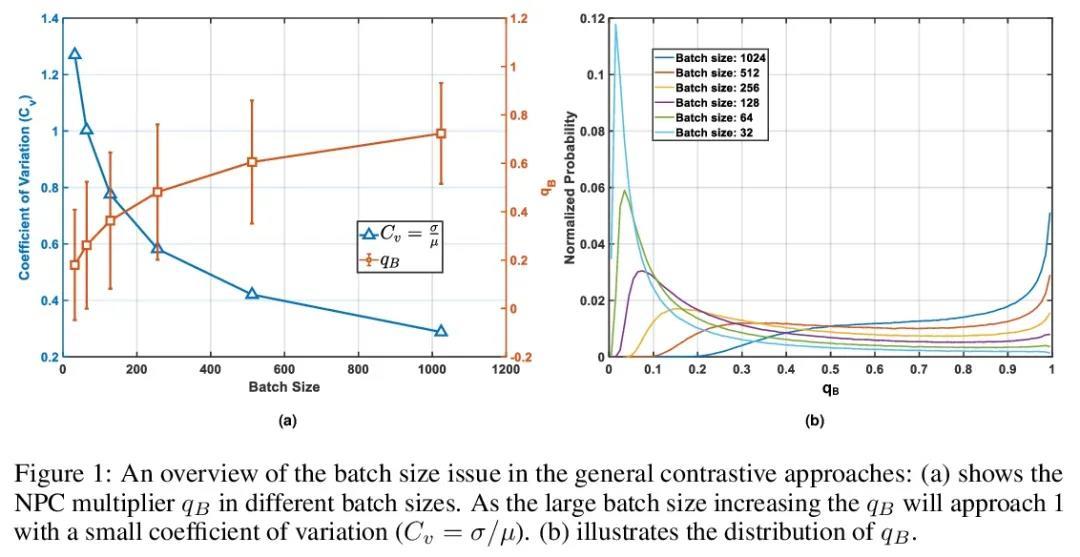
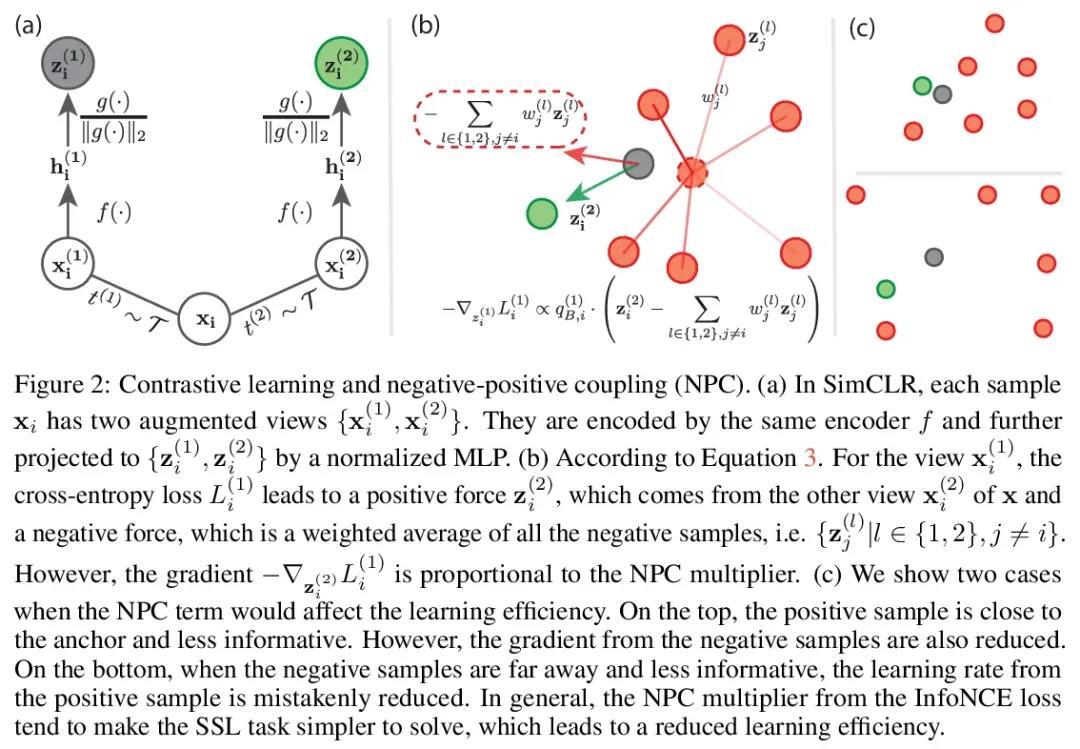
5、[LG] Decoupled Contrastive Learning
C Yeh, C Hong, Y Hsu, T Liu, Y Chen, Y LeCun
[Academia Sinica & Facebook AI Research]
解耦对比学习。对比学习(CL)是自监督学习(SSL)最成功的范式之一。以一种原则性的方式,认为同一图像的两个增强的"视图 "是正面的,可以拉近,而所有其他图像是负面的,可以进一步推开。然而,在基于对比学习的技术取得令人印象深刻的成功背后,其表述往往依赖于繁重的计算设置,包括大批量的样本、大量的训练历时等。本文旨在建立一个简单、高效且有竞争力的对比学习基线,从理论和实证研究中发现,在广泛使用的交叉熵(InfoNCE)损失中存在明显的负-正-耦合(NPC)效应,导致学习效率与批量大小不相适应。事实上,这一现象往往被忽视,因为用小规模的批量优化infoNCE损失对解决较容易的自监督学习任务是有效的。通过适当处理NPC效应,本文得到了一个解耦对比学习(DCL)的目标函数,显著提高了SSL的效率。解耦对比学习可以实现有竞争力的性能,既不需要SimCLR中的大批量,也不需要MoCo中的动量编码,更不需要大的历时。在各种基准中证明了DCL的有用性,同时体现了它的鲁棒性,对次优超参数不那么敏感。值得注意的是,所提出方法在200轮次的预训练中使用批量大小为256的方法达到了66.9%的ImageNet top-1准确率,比其基准SimCLR高出5.1%。通过进一步优化超参数,DCL可以将准确性提高到68.2%。
Contrastive learning (CL) is one of the most successful paradigms for selfsupervised learning (SSL). In a principled way, it considers two augmented “views” of the same image as positive to be pulled closer, and all other images negative to be pushed further apart. However, behind the impressive success of CL-based techniques, their formulation often relies on heavy-computation settings, including large sample batches, extensive training epochs, etc. We are thus motivated to tackle these issues and aim at establishing a simple, efficient, and yet competitive baseline of contrastive learning. Specifically, we identify, from theoretical and empirical studies, a noticeable negative-positive-coupling (NPC) effect in the widely used cross-entropy (InfoNCE) loss, leading to unsuitable learning efficiency with respect to the batch size. Indeed the phenomenon tends to be neglected in that optimizing infoNCE loss with a small-size batch is effective in solving easier SSL tasks. By properly addressing the NPC effect, we reach a decoupled contrastive learning (DCL) objective function, significantly improving SSL efficiency. DCL can achieve competitive performance, requiring neither large batches in SimCLR, momentum encoding in MoCo, or large epochs. We demonstrate the usefulness of DCL in various benchmarks, while manifesting its robustness being much less sensitive to suboptimal hyperparameters. Notably, our approach achieves 66.9% ImageNet top-1 accuracy using batch size 256 within 200 epochs pre-training, outperforming its baseline SimCLR by 5.1%. With further optimized hyperparameters, DCL can improve the accuracy to 68.2%. We believe DCL provides a valuable baseline for future contrastive learning-based SSL studies.
https://weibo.com/1402400261/KCMIuqnJZ


另外几篇值得关注的论文:
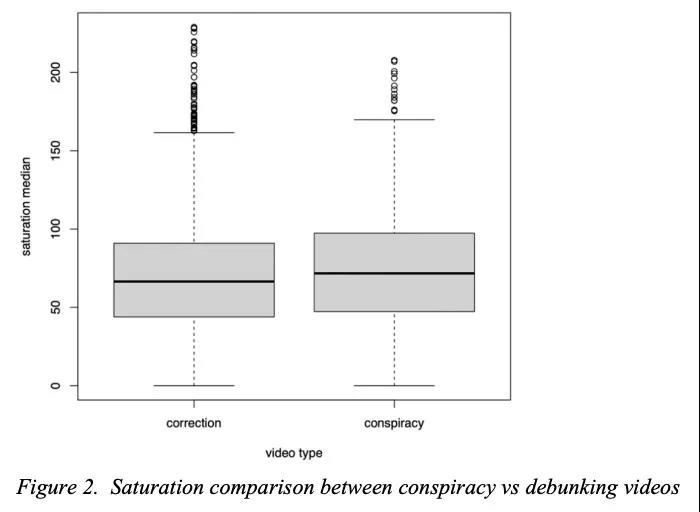
[CV] Visual Framing of Science Conspiracy Videos: Integrating Machine Learning with Communication Theories to Study the Use of Color and Brightness
科学阴谋论视频的视觉框架:将机器学习与传播理论相结合,研究颜色和亮度的使用
K Chen, S J Kim, Q Gao, S Raschka
[University of Wisconsin-Madison]
Recent years have witnessed an explosion of science conspiracy videos on the Internet, challenging science epistemology and public understanding of science. Scholars have started to examine the persuasion techniques used in conspiracy messages such as uncertainty and fear yet, little is understood about the visual narratives, especially how visual narratives differ in videos that debunk conspiracies versus those that propagate conspiracies. This paper addresses this gap in understanding visual framing in conspiracy videos through analyzing millions of frames from conspiracy and counter-conspiracy YouTube videos using computational methods. We found that conspiracy videos tended to use lower color variance and brightness, especially in thumbnails and earlier parts of the videos. This paper also demonstrates how researchers can integrate textual and visual features in machine learning models to study conspiracies on social media and discusses the implications of computational modeling for scholars interested in studying visual manipulation in the digital era. The analysis of visual and textual features presented in this paper could be useful for future studies focused on designing systems to identify conspiracy content on the Internet.
https://weibo.com/1402400261/KCMBmBl7V

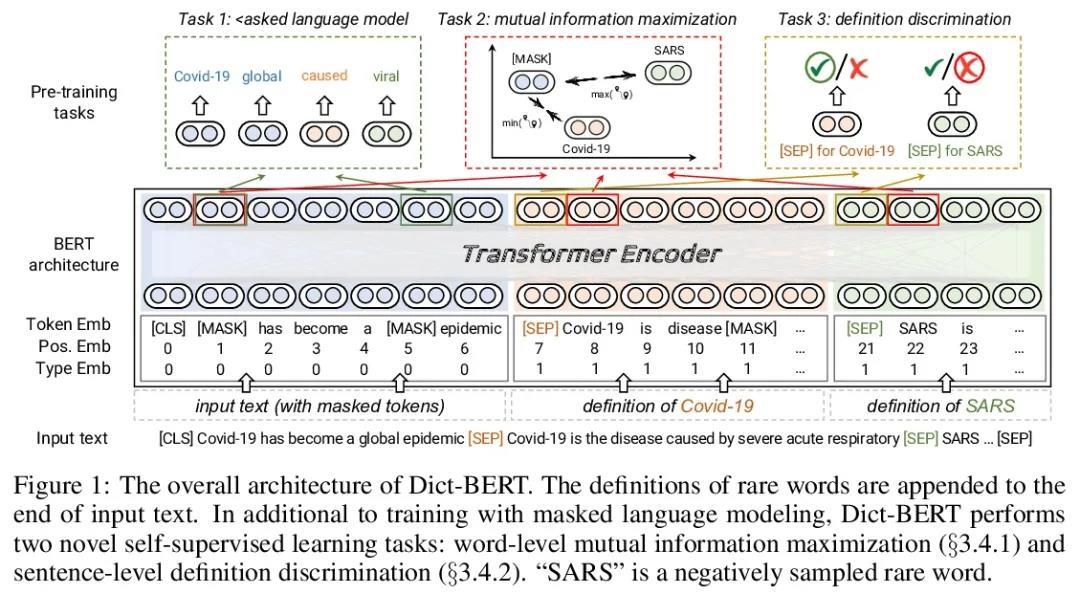
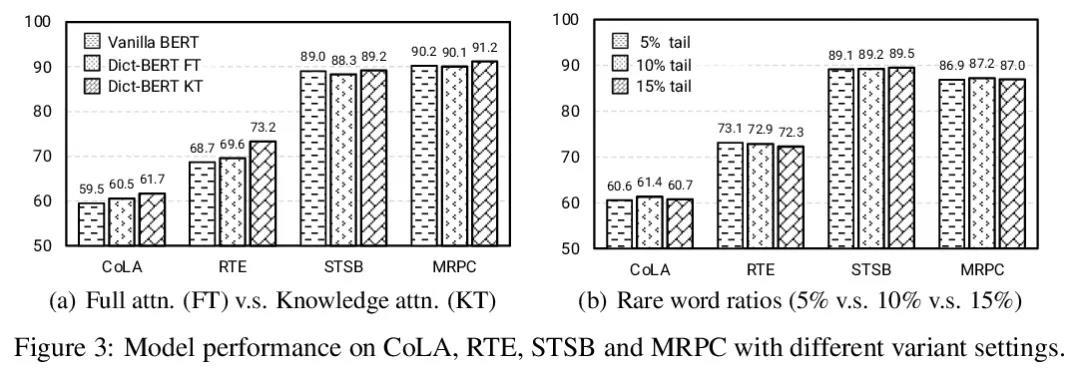
[CL] Dict-BERT: Enhancing Language Model Pre-training with Dictionary
Dict-BERT:用字典增强语言模型预训练
W Yu, C Zhu, Y Fang, D Yu, S Wang, Y Xu, M Zeng, M Jiang
[University of Notre Dame & Microsoft Cognitive Services Research]
https://weibo.com/1402400261/KCMLEzozU


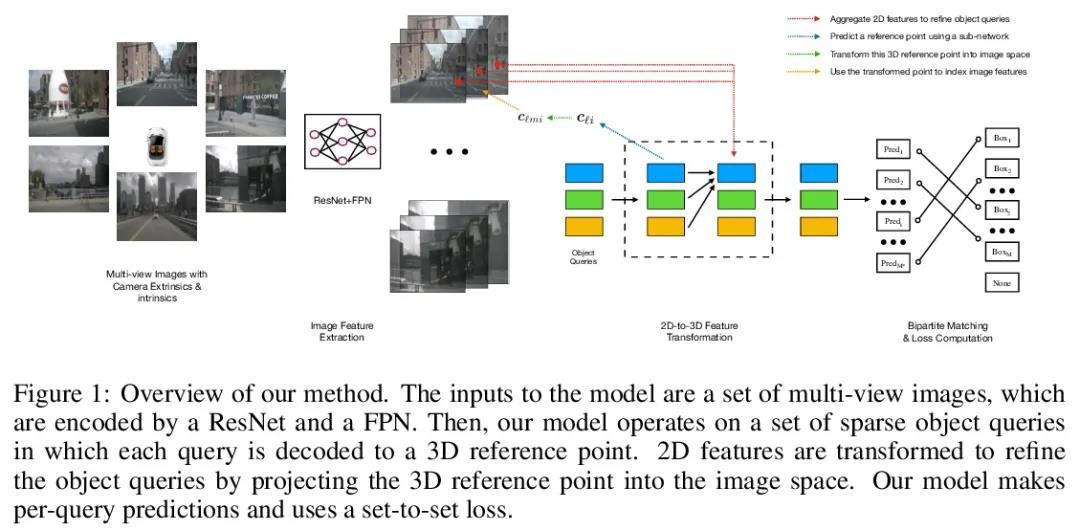
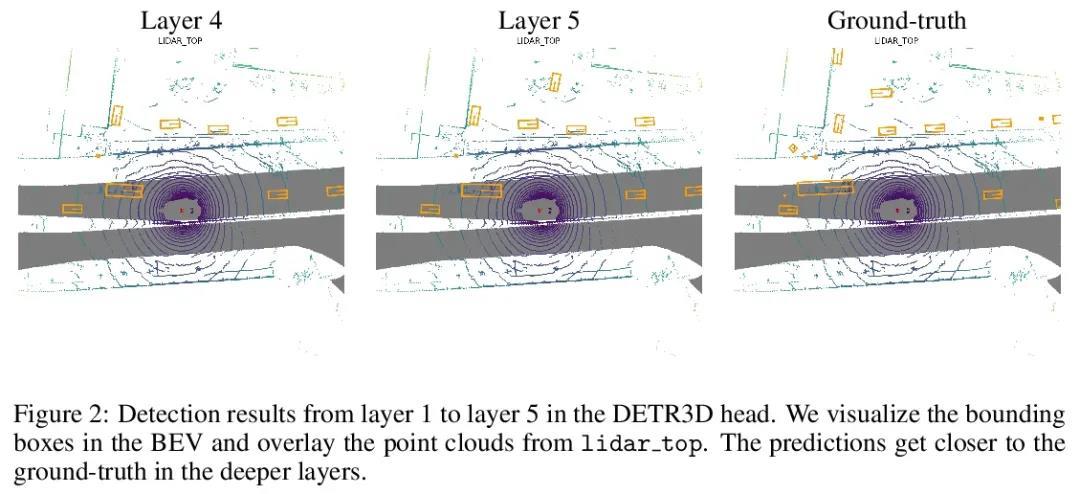
[CV] DETR3D: 3D Object Detection from Multi-view Images via 3D-to-2D Queries
DETR3D:基于3D到2D查询的多视图图像3D目标检测
Y Wang, V Guizilini, T Zhang, Y Wang, H Zhao, J Solomon
[MIT & Toyota Research Institute & Li Auto & Tsinghua University]
https://weibo.com/1402400261/KCMNFDnZy


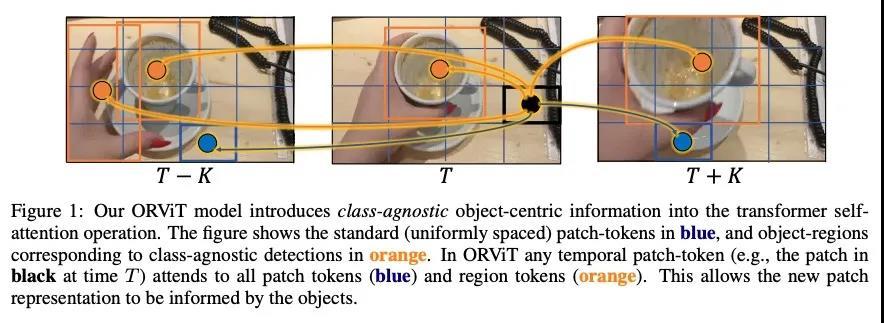
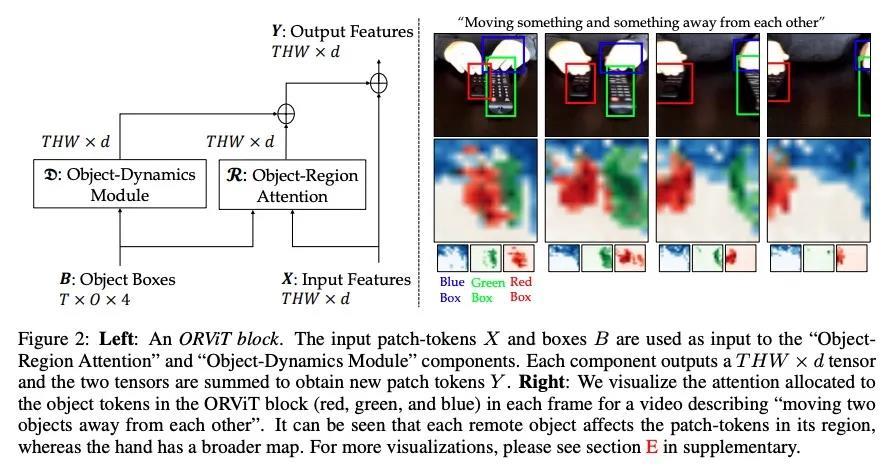
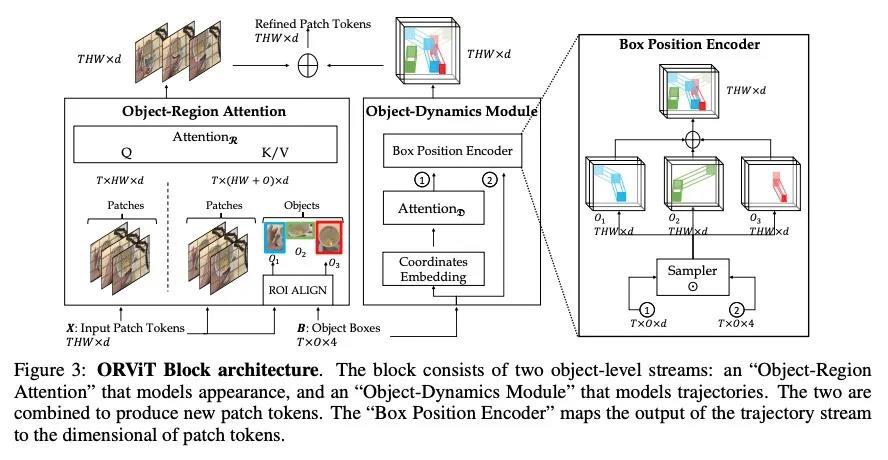
[CV] Object-Region Video Transformers
目标区域视频Transformer
R Herzig, E Ben-Avraham, K Mangalam, A Bar, G Chechik, A Rohrbach, T Darrell, A Globerson
[Tel Aviv University & UC Berkeley & Bar-Ilan University]
https://weibo.com/1402400261/KCMPMxBG4

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢