
【AAAI 2021】Combining Reinforcement Learning and Constraint Programming for Combinatorial Optimization
- 链接:https://arxiv.org/abs/2006.01610
- 作者:Quentin Cappart, Thierry Moisan, Louis-Martin Rousseau, Isabeau Prémont-Schwarz, Andre Cire
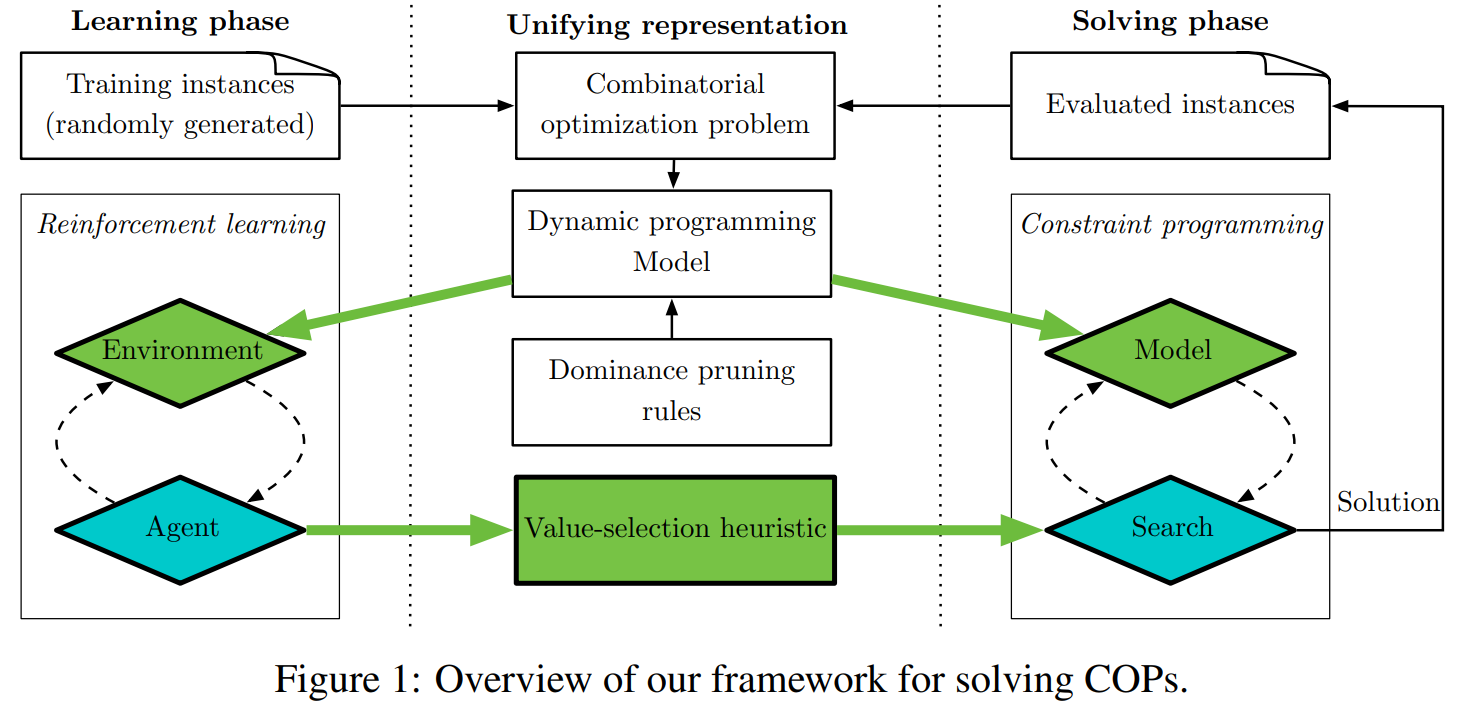
导读:组合优化的目标是在有限的一组可能性中找到最佳解决方案。它面临挑战是状态空间爆炸问题:可能性的数量随着问题的规模呈指数增长,这使得解决大型问题变得棘手。在过去的几年中,深度强化学习 (DRL) 已显示出其在设计专门用于解决 NP 难组合优化问题的良好启发式方法方面的前景。
然而,目前的方法有两个缺点:(1)它们主要关注标准的旅行商问题,不能轻易扩展到其他问题;(2)它们只提供了一个近似解,没有系统的方法来改进或证明最优性。在另一种情况下,约束规划 (CP) 是解决组合优化问题的通用工具。基于一个完整的搜索过程,如果允许足够的执行时间,它总是会找到最优解。一个关键的设计选择,使 CP 在实践中使用起来非常重要,是分支决策,指导如何探索搜索空间。
在这项工作中,作者提出了一种基于 DRL 和 CP 的通用混合方法,用于解决组合优化问题。我们方法的核心是基于动态规划公式,作为这两种技术之间的桥梁。实验表明结果,该求解器可以有效地解决两个具有挑战性的问题:具有时间窗的旅行商问题和 4 时刻投资组合优化问题。
【arXiv 2021】ScheduleNet: Learn to solve multi-agent scheduling problems with reinforcement learning
- 链接:https://arxiv.org/abs/2106.03051
- 作者:Junyoung Park, Sanjar Bakhtiyar, Jinkyoo Park
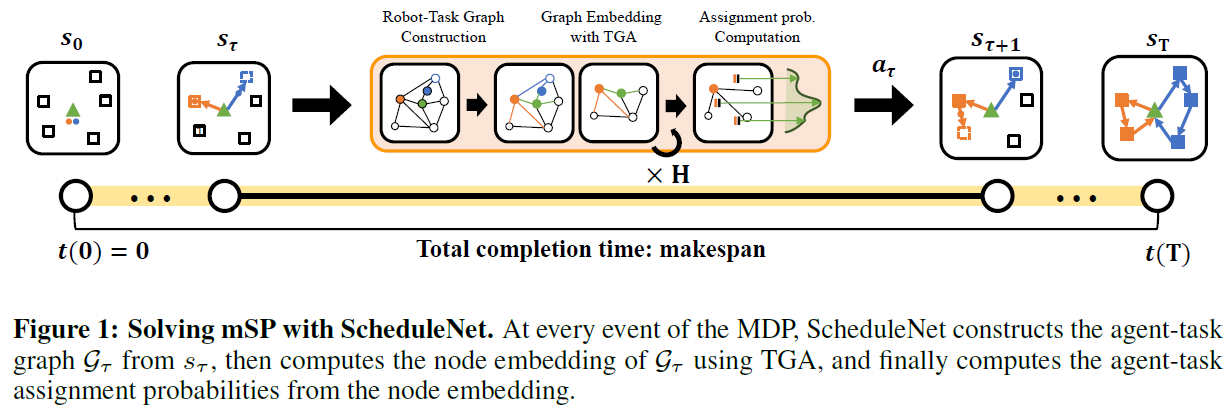
导读:该工作中提出了一种基于 RL 的实时调度器 ScheduleNet,可以解决各种类型的 multi-agent 调度问题。 作者将这些问题表述semi MDP 并学习 ScheduleNet,可以有效地协调多个代理完成任务。
ScheduleNet的决策过程包括:
- 用代理-任务图表示调度问题的状态
- 通过使用type-aware graph attention (TGA)提取代理和任务节点的节点嵌入,代理和任务之间的重要关系信息,
- 使用计算出的节点嵌入计算分配概率。
实验结果表明,ScheduleNet 作为通用基于学习的调度程序可用于用于解决各种类型的多代理调度任务,包括多销售员旅行问题 (mTSP) 和作业车间调度问题 (JSP),具有有效性和一定的泛化性。
【arXiv 2021】Efficient Active Search for Combinatorial Optimization Problems
- 链接:https://arxiv.org/abs/2106.05126
- 作者:André Hottung, Yeong-Dae Kwon, Kevin Tierney 分别为德国比勒费尔德大学和韩国首尔 三星SDS 的学者
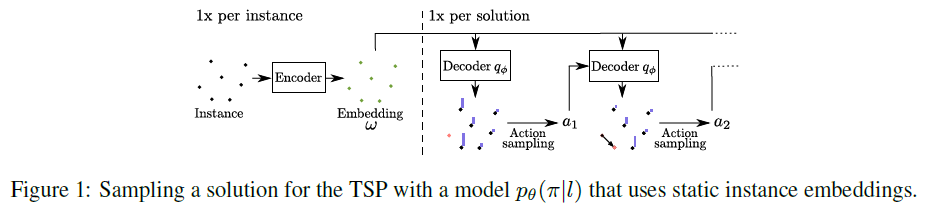
导读:许多基于机器学习的组合优化问题的方法通过强化学习学习在顺序决策过程中构造解决方案。这些方法可以很容易地与采样和射线搜索等搜索策略结合起来,但要将它们集成到一个高级搜索过程中提供强有力的搜索引导是不够直接的。Bello 等人(2016)提出主动搜索,在测试时间使用强化学习调整一个(训练过的)模型相对于单个实例的权重。虽然主动搜索易实现,但它不能与最先进的方法竞争,因为调整每个测试的所有模型权重需要很长的时间和内存。作者提出并评估了三种仅在搜索过程中更新一组参数的有效主动搜索策略,而不是更新所有的模型权重。提出的方法为显著提高给定模型的搜索性能和优于基于组合问题的最新机器学习方法提供了一个简单的途径,而不需要通过著名的启发式求解器 lkh3来求解车辆路径问题。最后,作者展示了(有效的)主动搜索使学习模型能够有效地解决比训练期间看到的更大的实例。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢