
【论文标题】Pre-trained Language Models in Biomedical Domain: A Systematic Survey
【作者团队】Benyou Wang, Qianqian Xie, Jiahuan Pei, Prayag Tiwari, Zhao Li, Jie fu
【发表时间】2021/10/12
【机 构】曼彻斯特大学、Mila等
【论文链接】https://arxiv.org/abs/2110.05006v2
预训练语言模型已经成为大多数自然语言处理任务的事实范式。这也有利于生物医学领域:来自信息学、医学和计算机科学界的研究人员提出了各种在生物医学数据集上训练的预训练模型,如生物医学文本、电子健康记录、蛋白质和DNA序列,用于各种生物医学任务。然而,生物医学预训练的跨学科特点阻碍了它们在社区中的传播,一些现有的工作是相互孤立的,没有全面的比较和讨论。需要系统地回顾生物医学预训练模型的最新进展和它们的应用,而且规范术语和基准。本文总结了预训练语言模型在生物医学领域的最新进展以及它们在生物医学下游任务中的应用。特别是,本文讨论了动机,并提出了现有生物医学预训练的分类法。本文详尽地讨论了它们在生物医学下游任务中的应用。最后,本文说明了各种局限性和未来的趋势,希望这能为研究界的未来研究提供灵感。
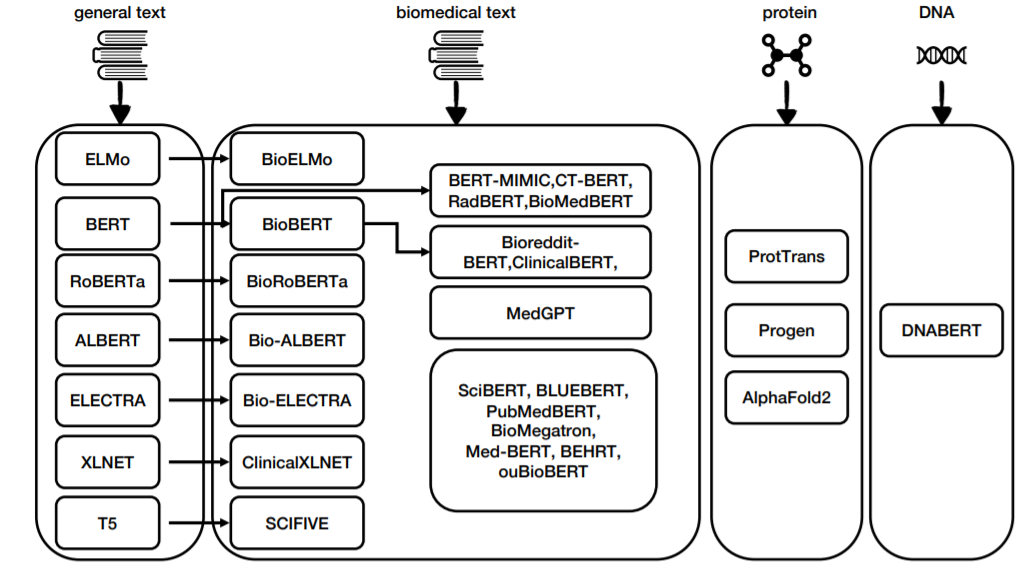
上图显示了生物医学预训练语言模型的概述。在AlphaFold2的整体架构中,也存在一个类似BERT的语言模型。AlphaFold 2可以提供精确的估计,它可以自信地用于蛋白质结构预测,而且可靠性很高。然而,包括AlphaFold 2在内的现有方法的预测更多的是针对家族的,而不是针对蛋白质的,并且依赖于多序列比对(MSA)中捕获的进化信息。为了解决这些问题,Weißenow提出使用预训练的蛋白质语言模型ProtT5的注意头,而不使用MSA。Sturmfels等人提出了一个新的具有生物信息的预训练任务:预测来自多序列比对的蛋白质轮廓,这可以改善下游的蛋白质结构预测任务。
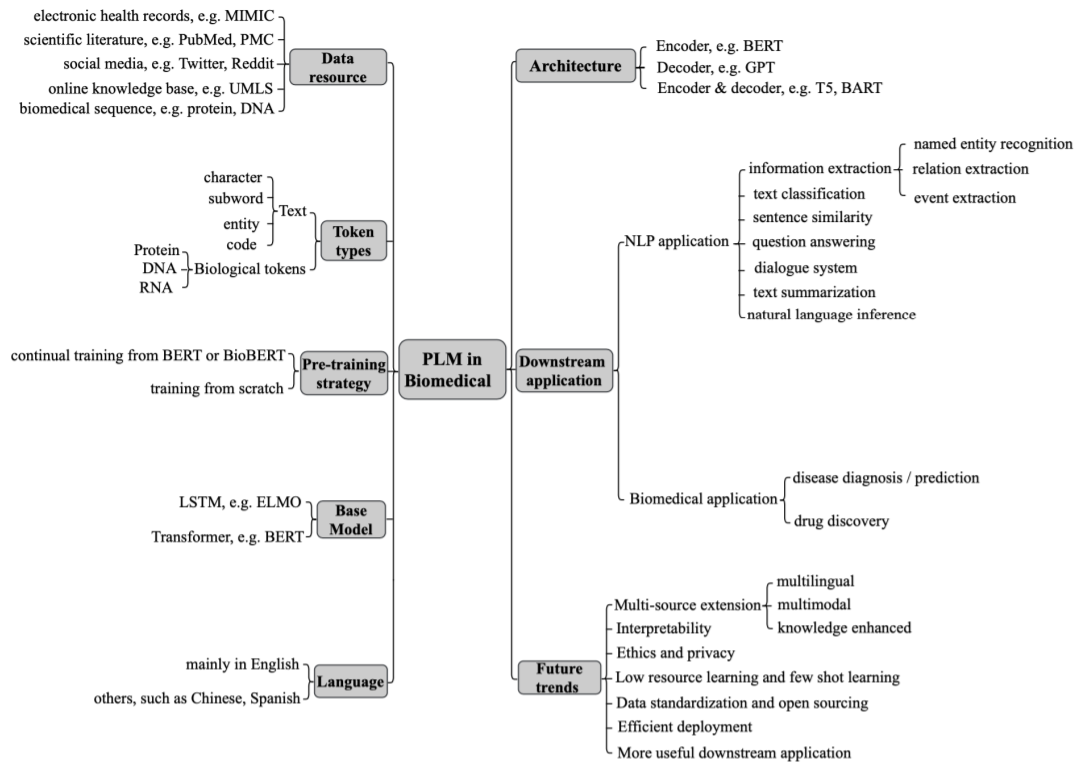
上图显示预训练语言模型的分类,在生物医学领域使用预训练的语言模型的琐碎方法是用领域数据对其进行微调。然而,通常会采取额外的适应措施,将学到的领域知识和任务特征转移到目标领域和任务中。其适应性基本上有两个方面:领域迁移或任务特征。前者指的是如何将一般的预训练语言模型迁移到特定的生物医学领域。
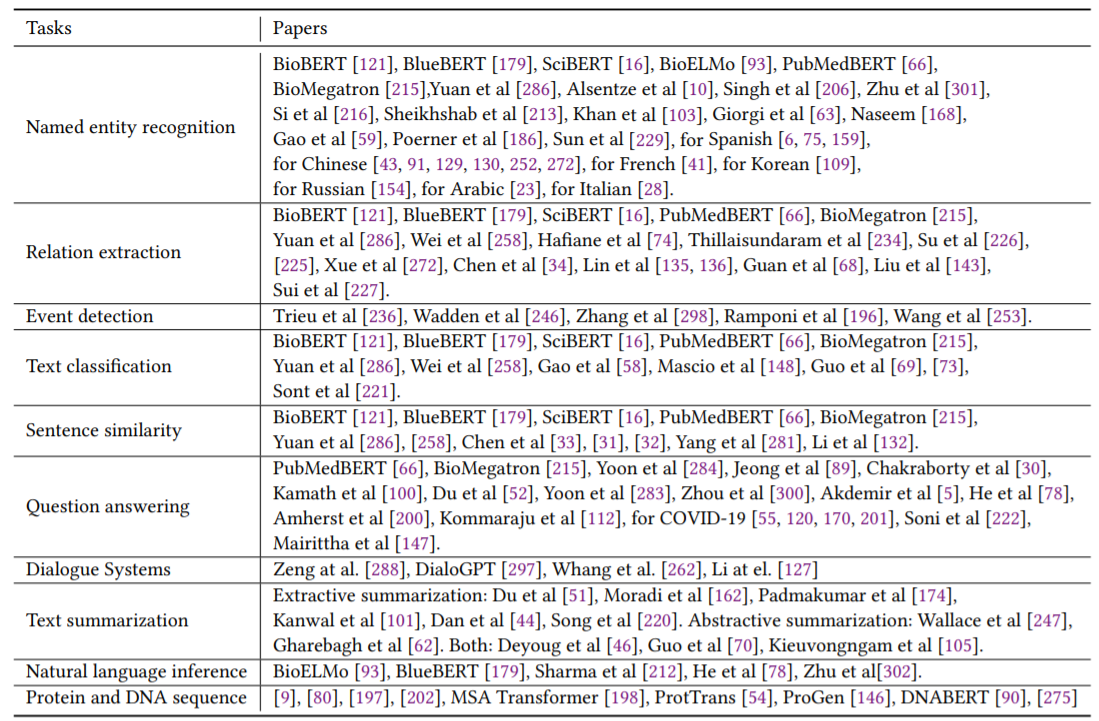
上图显示了生物医学领域的下游任务,本文也对为何使用预训练模型进行的回答。
- 首先,生物医学领域涉及许多通常缺乏注释的连续标记,如生物医学语料库和电子健康记录的历史。然而,这些序列数据以前被认为是难以建模的。由于有了预训练的语言模型,经验表明可以有效地以自监督的方式训练这些顺序数据。
- 其次,生物医学领域的注释数据通常规模有限。机器学习中的一些极端情况被称为 "零样本 "或 "小样本"。最近,GPT3显示,语言模型有可能进行小样本学习,甚至是零样本学习。因此,一个训练好的预训练语言模型对于提供更丰富的特征提取器更为关键,这可能会稍微减少对注释数据的依赖。
- 另外,生物医学领域比一般领域更需要知识,因为有些任务可能需要一些领域专家的知识,而预训练的语言模型可以作为一个容易使用的软知识库,从没有人类注释的大规模普通文档中捕获隐性知识。最近,GPT3已经被证明有可能 "记住 "许多复杂的常识。
- 最后,除文本外,生物医学领域还存在各种类型的生物序列数据,如蛋白质序列和DNA序列。使用这些数据来训练语言模型,在传统的生物任务中显示出巨大的成功,如蛋白质结构预测。因此,预计预训练的语言模型可以解决生物学中更多的挑战性问题。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢