
ICCV全称International Conference on Computer Vision(国际计算机视觉大会),为计算机视觉的国际顶级学术会议之一。ICCV 2021线上会议在近日召开,据统计,今年ICCV有效投稿量达6152篇,共接收论文1612篇,接收率约为26%。
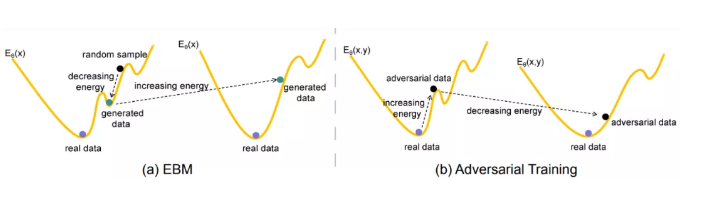
1、Towards Understanding the Generative Capability of Adversarially Robust Classifiers (Oral)
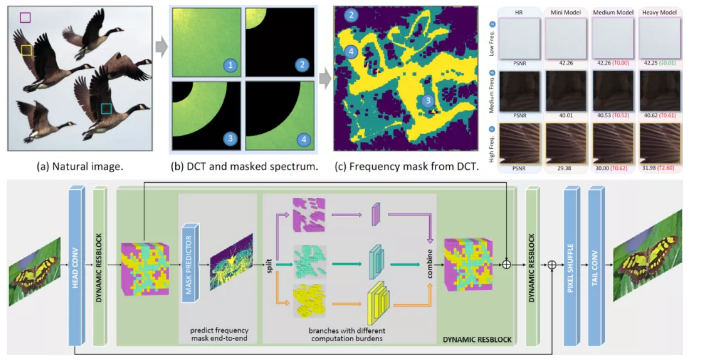
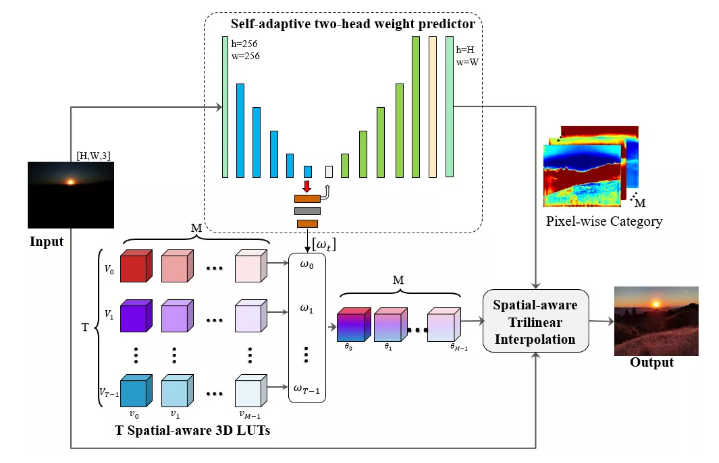
3、Real-time Image Enhancer via Learnable Spatial-aware 3D Lookup Tables
4、Active Learning for Lane Detection: A Knowledge Distillation Approach
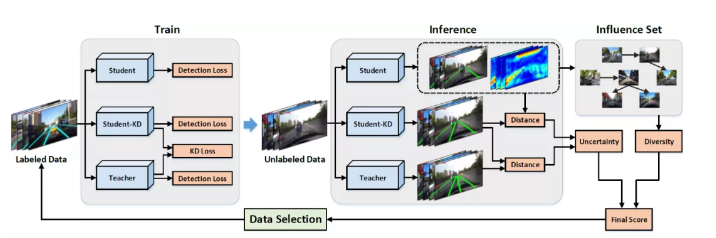
车道线检测是自动驾驶领域的一项关键任务,它依赖大量的人工标注数据来训练模型。主动学习是一种有效的数据挑选策略,用于降低数据标注的成本。但是现有的主动学习方法对于车道线检测任务收益甚微。我们发现,它们倾向于选择车道线较少的样本,并且无法有效地区分由于遮挡、车道线污损等因素导致的标注噪声。本文提出一种基于知识蒸馏的主动学习新架构,基于多个不同模型对样本的识别差异来评价样本的不确定性,有效地解决了上述两个问题。同时,本文提出了一种基于影响集的多样性评价方法,可降低数据冗余度,选出最具代表性的样本。结合不确定性和多样性评价指标,可以从未标注样本集中选择出最有价值的样本,达到降低数据标注成本的目的。本方法在公开数据集上进行试验,性能达到SOTA。此外,本方法可扩展到2D检测任务,实验也证明了它的有效性。
5、Self-Motivated Communication Agent for Real-World Vision-Dialog Navigation

现有的视觉对话导航代理只能在预先指定的位置和人类进行沟通,并且依赖大量的自然语言对话标注,这极大地限制了其在真实环境中的应用和部署。我们提出Self-Motivated Communication Agent (SCoA)可以根据实际情况自发地选择是否要提问以及提问的内容。SCoA包含一个 whether-to-ask策略学习模块和一个what-to-ask策略学习模块。前者根据当前动作预测的不确定性来决定是否要向人类提问以寻求帮助, 后者从候选的问题集合中挑选最富信息量的问题向人类求助。在获取关于下一步的提示信息后,我们的where-to-go策略学习将基于提问得到的回答更新当前代理状态,从而预测当前步应该采取什么样的动作才能更加接近最终的目标地点。SCoA的人机沟通模块和动作预测模块在统一的强化学习框架下结合模仿学习进行联合优化,实现自适应地沟通,并且以较小的沟通代价向人类获取关键的指示信息以完成导航任务。在CVDN数据集上,我们的方法的导航成功率高于现有方法,并且接近使用了昂贵的对话标注的方法。
6、PyramidR-CNN: Towards Better Performance and Adaptability for 3D Object Detection

当前3D目标检测模型在二阶段依赖于RoI中的关键点/体素的特征提取,但并未很好地处理点云稀疏性与分布不均匀的问题,导致模型对远处物体检测性能的减弱。为此,本文提出了一个灵活高效的二阶段3D目标检测框架Pyramid R-CNN来自适应地学习稀疏点云特征:1.通过RoI-grid Pyramid以金字塔结构对点云进行多层采样解决稀疏性问题;2.提出新算子RoI-grid Attention从稀疏点云中高效提取特征;3.提出Density-Aware Radius Prediction模块根据点云密度自适应调整RoI grid的采样半径。在KITTI和Waymo数据集上,Pyramid R-CNN 网络取得了超过最新的方法,显示了模型的优异性能。
7、C^3-SemiSeg: Contrastive Semi-supervised Segmentation via Cross-set Learning and Dynamic Class-balancing
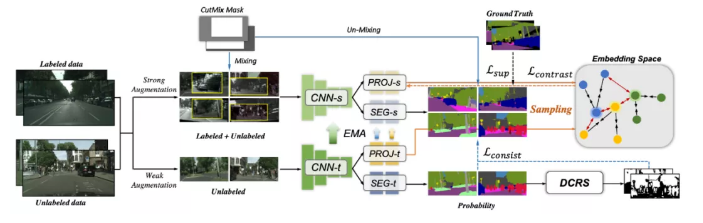
半监督语义分割方法利用未标记数据来增加特征判别能力,以减轻标注数据的负担。然而,主流的半监督一致性学习方法受到以下限制:来自标注和未标注数据的特征之间的错位;单独处理每个图像和区域不考虑类之间的关键语义依赖性。我们引入了一种新颖的 C3-SemiSeg,通过在扰动下利用更好的特征对齐和增强判别特征交叉图像的能力来改进基于一致性的半监督学习。我们引入了一种跨集区域级数据增强策略,以减少标记数据和未标记数据之间的特征差异。交叉逐像素对比学习进一步特征表示能力。为了稳定来自噪声的训练,我们提出了一种动态置信区域选择策略。我们在 Cityscapes 和 BDD100K 数据集上验证了所提出的方法,该方法明显优于其他最先进的半监督语义分割方法。
8、Voxel Transformer for 3D Object Detection
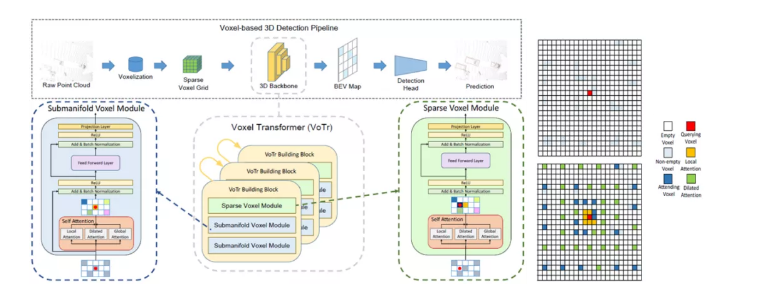
传统基于体素的3D目标检测模型骨干网络由于感受野大小的限制,无法有效的捕捉大范围的上下文信息,影响目标的识别与定位。在本文中,我们提出一个基于转换器的网络结构Voxel Transformer,通过对长程体素间进行自注意力计算来解决上述问题。针对3D点云场景中非空体素的稀疏性,我们提出了稀疏版本的转换器模块sparse voxel module和submanifold voxel module,有效区分空体素与非空体素来进行加速计算。在这两个模块中,我们提出了局部、膨胀自注意力机制,针对不同范围的体素进行计算。Voxel Transformer包含了一系列的sparse voxel module和submanifold voxel module,可用于目前大多数基于体素的检测模型中。相比于原版使用卷积骨干网络的模型,Voxel Transformer模型保持了计算效率,在KITTI和Waymo数据集上的检测性能均有稳定的提升。
9、NASOA: Towards Faster Task-oriented Online Fine-tuning with a Zoo of Models
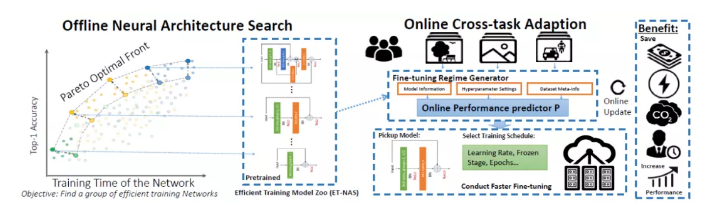
从预训练的 ImageNet 模型进行微调一直是一种用于各种 CV 任务的简单、有效的方法。微调的常见做法是采用带有固定模型以及默认超参数设置,而两者都没有针对特定任务和时间限制进行优化。此外,的云计算或 GPU 集群中,更快的在线微调是节省资金、能源消耗和碳排放的更理想的策略。在本文中,我们提出了一个名为 NASOA 的神经架构搜索在线适应框架,以根据用户的要求进行更快的面向任务的微调。NASOA首先采用离线 NAS 来得到一组训练高效的网络,形成一个预训练模型model zoo。然后,通过从过去的学习任务中积累经验,通过自适应模型估计微调性能,提出了一种在线调度生成器,以选择最合适的模型,并针对每个所需任务一次性生成个性化的训练机制。我们的model zoo比 SOTA 模型训练效率更高,比 RegNetY-16GF 快 6 倍,比 EfficientNetB3 快 1.7 倍。在多个数据集上的实验还表明,NASOA 实现了更好的微调结果,即在各种约束和任务下,比 RegNet 系列中的最佳性能提高了约 2.1% 的准确率;与 BOHB 相比快 40 倍。
10、G-DetKD: Towards General Distillation Framework for Object Detectors via Contrastive and Semantic-guided Feature Imitation
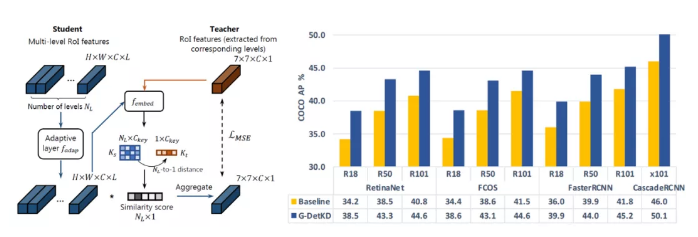
我们研究了针对目标检测的知识蒸馏 (KD) 策略,并提出了一个适用于同构和异构师生对的有效蒸馏框架。我们提出了一种新颖的语义引导的特征模仿技术,该技术在所有特征金字塔(FPN)的特征对之间自动执行软匹配,为学生模型提供最佳指导。我们还引入了对比蒸馏来有效地捕获在不同特征区域之间关系中的信息。最后,我们提出了一个广义检测 KD的框架,它能够提取同构和异构检测器对。我们的方法始终优于现有的检测 KD 技术。以强大的 X101-FasterRCNN-Instaboost 检测器为老师模型,R50-FasterRCNN能达到 44.0% AP,R50-RetinaNet 达到 43.3% AP,R50-FCOS 达到 43.1% AP。
11、Exploring Geometry-aware Contrast and Clustering Harmonization for Self-supervised 3D Object Detection
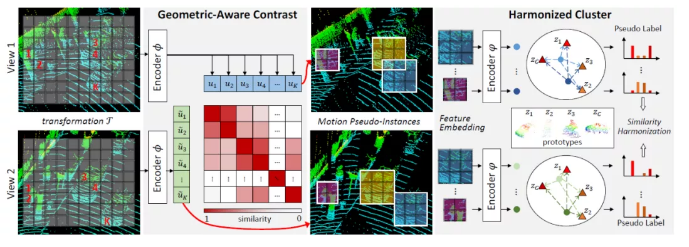
为了缓解严重的3D标注负担问题,本文提出了一种面向自动驾驶场景的LiDAR点云自监督训练框架,由两个主要部分组成:1) 通过引入几何约束发掘高信息量的正样本对,并构建距离连续的对比损失; 2) 语义信息合谐的聚类模块:根据场景流初始化伪目标,通过约束不同视图的伪目标特征聚类保持一致引入语义信息。实验表明自监督预训练能加速收敛,比半监督预训练的鲁棒性更强,在多个数据集上均明显优于随机初始化
12、Adversarial Robustness for Unsupervised Domain Adaptation
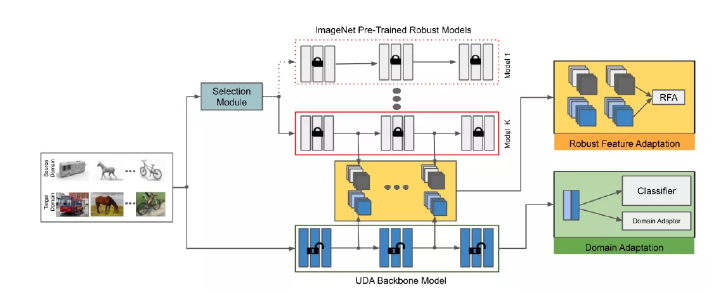
现有Unsupervised Domain Adaptation(UDA)方法只专注于模型在正常样本上的准确率,而忽视了模型的对抗鲁棒性。在实际应用中,模型的对抗鲁棒性同样非常重要。现有提升模型对抗鲁棒性的对抗学习方法主要是针对单域训练样本,基于样本标签计算损失函数,从而利用梯度产生对抗样本训练模型。因此,无法直接应用于UDA任务。我们的工作提出了一种高效提升UDA模型对抗鲁棒性的方法。首先,我们做了大量的实验验证了使用一个预训练的鲁棒模型在UDA任务上进行跨域学习可以有效提升模型对抗鲁棒性,但会大大降低在正常样本上的准确率。于是,我们提出了Robust Feature Adaptation (RFA):基于知识蒸馏的方式提升UDA模型的对抗鲁棒性。我们的方法使用多个不同强度对抗预训练的模型作为老师模型,使用以较弱强度对抗预训练的模型作为学生模型,蒸馏训练样本特征之间的相似度,可以在基本保持正常样本准确率不变的情况下,大幅提升模型的对抗鲁棒性。
13、NAS-OoD: Neural Architecture Search for Out-of-Distribution Generalization
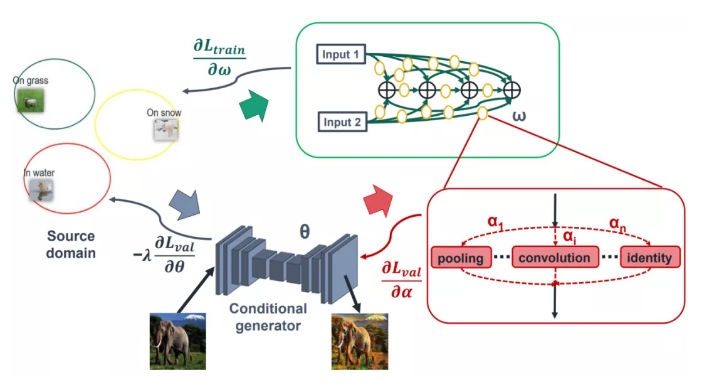
本工作从网络结构的角度理解和探究Out-of-Distribution(OoD)问题,迈出系统地理解神经网络架构OoD泛化性能的第一步。我们的初步实践表明,网络结构确实会影响OoD泛化性能。传统的机器学习算法,通常假设训练和测试样本来自同一概率分布Independent and Identically Distributed (i.i.d.)。但是对于OoD场景,即训练样本的概率分布和测试样本的概率分布不同的情况,训练出的模型很难在目标域取得良好的表现。现有的工作专注于OoD算法,没有考虑深度模型架构对OoD泛化的影响,这可能导致次优性能。本工作提出了针对OoD泛化的鲁棒神经网络架构搜索(NAS-OoD),通过最大化不同网络架构计算的损失函数来训练生成OoD样本,同时通过最小化生成OoD数据的损失函数来优化架构搜索过程。NAS-OoD在不同数据集上均取得最优表现,这为探究OoD泛化问题提供了更深入的研究基础。
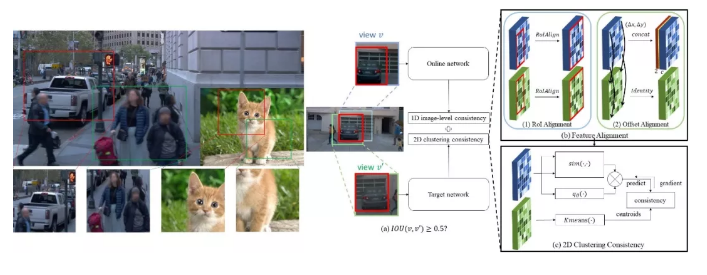
现有自监督对比学习基于单实例假设,即认为每张图像仅有一个实例,相同图像切得图像块为正样本而不同图像切得图像块为负样本;但在自动驾驶场景中,街景图像往往包含行人和车辆等多个物体,并不符合上述单实例假设,因此现有方法很难充分利用更贴近现实的多实例自动驾驶数据集。基于以上观察,一方面我们讨论多实例场景下正样本的定义方式,使用交并比阈值将全局不一致性转化为局部一致性,并提出感兴趣区域对齐和位移对齐两种方式解决由数据增强带来的特征不对齐;另一方面我们使用图像内聚类以捕捉二维特征结构信息来衡量多实例正样本的相似度。我们提出全新自监督学习框架MultiSiam,基于Waymo以及ImageNet数据集进行预训练,在多个下游自动驾驶和自然图像基准上达到SOTA结果;同时通过在大规模自动驾驶数据集SODA10M上预训练,MultiSiam成功超过ImageNet预训练的MoCov2,展现了域内预训练的有效性。
15、Boostingthe Generalization Capability in Cross-Domain Few-shot Learning via Noise-enhanced Supervised Autoencoder

针对跨领域的小样本学习问题,我们利用auto-encoder的结构同时解决提升模型泛化性和domain adaption的问题。Domain generalization 对于跨领域小样本学习非常重要。一个在源数据集表现非常好的分类器,在迁移到目标数据集的时候泛化性比较差;然而一个在源数据表现一般的分类器,可能有更强的domain 泛化性,在目标数据集上面表现优异。我们研发了noise-enhanced supervised autoencoder (NSAE)的框架来训练模型获取更多样更广泛的特征分布类型。在源数据集的预训练过程中,我们训练NSAE同时预测源数据的类别且同时重构输入数据,此外我们把重构的数据作为noisyinputs 再次输入到网络中做分类任务。基于Inter-class correlation 的统计分析表明这种训练方法获得的特征空间有更好的泛化性和判别性。在目标数据集的finetune的过程中,我们继续利用NSAE的结构,在训练模型做分类任务之前,首先用auto-encoder 在目标数据集做重构任务来实现对目标数据集的domain adaption。我们在多个benchmark数据集上利用多种损失函数组合,进行了充足的实验和ablation study,结果证实了NASE各种设计的有效性,并且获得了SOTA的结果.
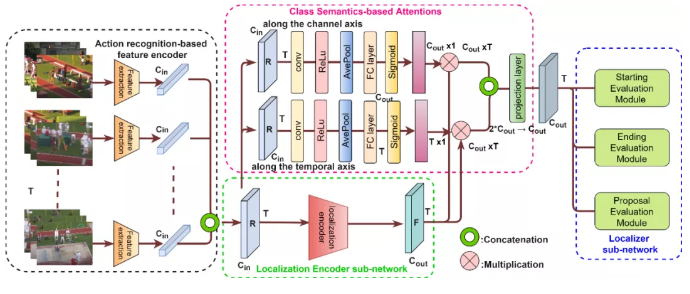
时序动作定位网络由一个用于学习动作定位表征的编码器子网络和一个用于计算候选的proposal的定位子网络组成。先前的时序定位方法在其编码器中没有包含任何注意机制。所以在这项工作中,我们提出了基于类语义的注意力机制(CSA)。这是一种专门为时序动作定位而设计的新型注意力机制,它从输入类语义特征中学习时序定位编码器输出的注意力权重,沿并且同时在通道和时间轴独立的应用注意力权重。通过比较我们发现我们提出的类语义的注意力机制CSA在时序动作定位中优于其他的注意力方法,比如Squeeze-and-Exciteattention、Convolutional Block Attention Module 和 Transformer,并且也为这些方法提供了一些补充信息。我们的CSA模型展现了非常好的实验效果,在ActivityNetv1.3 数据集上实现了当前最优的结果36.25 mAP。并且与baseline BMN模型相比,在 THUMOS-14数据集上获得了 6.2% 的改进,实现了47.5 mAP。我们利用包括BMN-CSA在内的各种衍生模型系列拿到了国际权威的CVPR 2021 ActivityNet 时序动作定位挑战赛的第二名, 整体精度和第一名只差了0.56% (尽管我们使用了一个更低精度的视频分类器)。这个是挑战赛总结的视频链接:https://www.bilibili.com/video/BV1gb4y1o7JN/
附录:华为诺亚方舟实验室ICCV 2021论文列表
1. Learning Frequency-aware Dynamic Network for Efficient Super-Resolution
2. Real-time Image Enhancer via Learnable Spatial-aware 3D Lookup Tables
3. Active Learning for Lane Detection: A Knowledge Distillation Approach
4. Self-Motivated Communication Agent for Real-World Vision-Dialog Navigation
5. Pyramid R-CNN: Towards Better Performance and Adaptability for 3D Object Detection
6. C^3-SemiSeg: Contrastive Semi-supervised Segmentation via Cross-set Learning and Dynamic Class-balancing
7. Voxel Transformer for 3D Object Detection
8. NASOA: Towards Faster Task-oriented Online Fine-tuning with a Zoo of Models
9. DetCo: Unsupervised Contrastive Learning for Object Detection
10. G-DetKD: Towards General Distillation Framework for Object Detectors via Contrastive and Semantic-guided Feature Imitation
11. Exploring Geometry-aware Contrast and Clustering Harmonization for Self-supervised 3D Object Detection
12. Adversarial Robustness for Unsupervised Domain Adaptation
13. NAS-OoD: Neural Architecture Search for Out-of-Distribution Generalization
14. MultiSiam: Self-supervised Multi-instance Siamese Representation Learning for Autonomous Driving
15. Towards Understanding the Generative Capability o fAdversarially Robust Classifiers
16. Poly-NL: Linear Complexity Non-local Layers With 3rd Order Polynomials
17. GP-S3Net: Graph-based Panoptic Sparse Semantic Segmentation Network
18. Boosting the Generalization Capability in Cross-Domain Few-shot Learning via Noise-enhanced Supervised Autoencoder
19. Class Semantics-based Attention for Action Detection
20. Bifold and Semantic Reasoning for Pedestrian Behavior Prediction
21. Prediction by Anticipation: An Action-Conditional Prediction Method based on Interaction Learning
22. Multi-Scale Separable Network for Ultra-High-Definition Video Deblurring
23. UHD Image HDR Reconstruction via Collaborative Bilateral Learning
24. Hyperspectral Image Denoising with Realistic Data
25. ReCU: Reviving the Dead Weights in Binary Neural Networks
27. TRAR: Routing the Attention Spans in Transformers for Visual Question Answering
28. Occlude Them All: Occlusion-Aware Mask Network for Person Re-identification
29. DualPoseNet: Category-level 6D Object Pose and Size Estimation using Dual Pose Network with Refined Learning of Pose Consistency
30. Instance Segmentation in 3D Scenes using Semantic Superpoint Tree Networks
31. Learning Causal Representation for Training Cross-Domain Pose Estimator via Generative Interventions
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢