
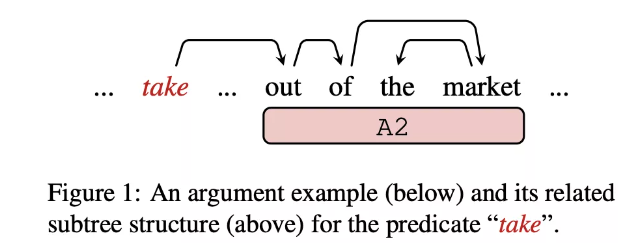
这种内部结构在直觉上对于 SRL 很有效,例如在上面的图中,谓词 take 对应的论元「out of the market」的标签为 A2,这种关系可以反映在 take 到论元中心词 out 的弧中,此外,该论元的边界也和相应的子树边界完美对应。如果捕捉到内部结构信息,可以有效引导角色标签分类以及论元识别这两个子任务。然而由于 SRL 是一个 shallow parsing task,缺乏层次化的结构标注,这种内部结构还很少被前人工作利用。
基于这些观察,我们提出将平坦论元结构建模为隐式(latent)依存子树。通过这种方式,我们可以方便地将 SRL 归纳成一个依存句法分析任务。基于这种归纳,我们可以无缝利用已有的一些成熟的依存句法分析技术,例如 TreeCRF、高阶建模等等,来进行全局概率推断。
论文标题:Semantic Role Labeling as Dependency Parsing: Exploring Latent Tree Structures Inside Arguments
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢