
 自主导航需要道路网络的结构化表示和其他交通智体的实例识别。由于交通场景是地平面定义,即鸟瞰图 (BEV) 的场景理解。这项工作研究从单个车载摄像头图像中提取BEV坐标表示的当地道路网络有向图问题。此外,该方法可扩展到检测 在BEV 平面的动态目标。检测目标的语义、位置和方向以及道路图有助于对场景的全面理解。这种理解成为下游任务的基础,即路径规划和导航。
自主导航需要道路网络的结构化表示和其他交通智体的实例识别。由于交通场景是地平面定义,即鸟瞰图 (BEV) 的场景理解。这项工作研究从单个车载摄像头图像中提取BEV坐标表示的当地道路网络有向图问题。此外,该方法可扩展到检测 在BEV 平面的动态目标。检测目标的语义、位置和方向以及道路图有助于对场景的全面理解。这种理解成为下游任务的基础,即路径规划和导航。
代码将公开:https://github.com/ybarancan/STSU
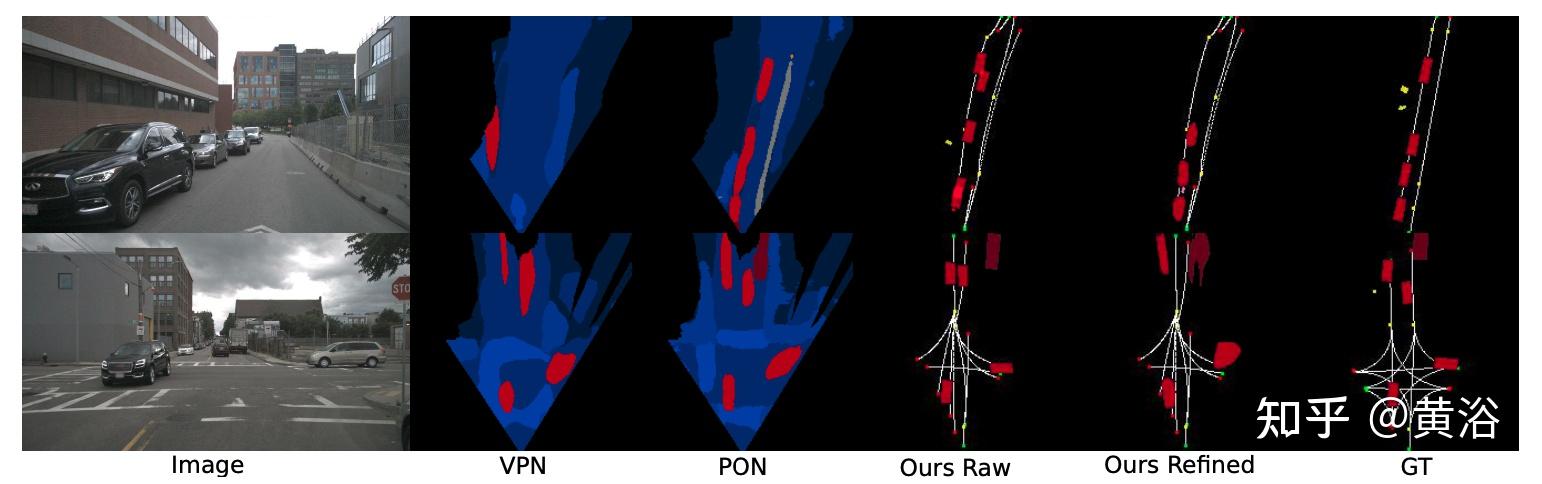
如图所示是道路网络的图结构估计示意图,即从单目前向图像提取表示当地道路网络的有向图:首先,道路中心线与有向图一起估计,其中顶点是道路中心线,边显示连通性;然后估计边的存在和方向,绿点表示起点,红点表示中心线的终点,交通从绿色流向红色。该方法也处理复杂的交叉路场景以及多目标实例,如图所示: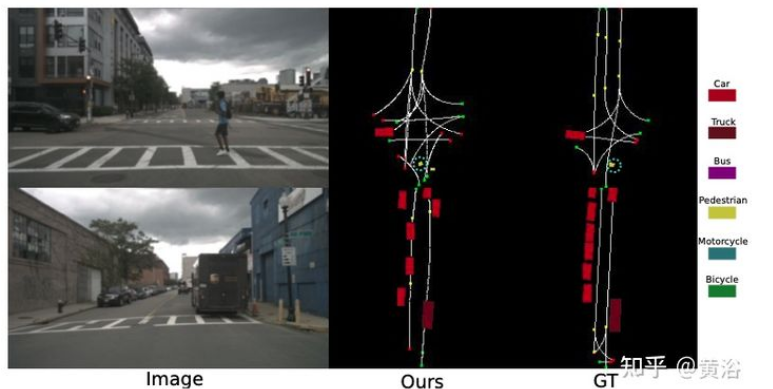 为了对本地道路网络进行结构化表示,构建车道中心线的有向图,通常称为车道图(lane graph)。没有硬性要求生成非循环图,但由于专注于有限视野 (FOV) 的单目图像,很少出现循环情况。 因此,关联矩阵通常具有无环图结构,其中主对角线为零且对称项总和至多为 1。 发生率矩阵还包含有关交通流方向的关键信息,这是理解车道网络的基础。
为了对本地道路网络进行结构化表示,构建车道中心线的有向图,通常称为车道图(lane graph)。没有硬性要求生成非循环图,但由于专注于有限视野 (FOV) 的单目图像,很少出现循环情况。 因此,关联矩阵通常具有无环图结构,其中主对角线为零且对称项总和至多为 1。 发生率矩阵还包含有关交通流方向的关键信息,这是理解车道网络的基础。
Bezier 曲线非常适合中心线,它用固定数量2D 点对任意长度的曲线进行建模。因此,给定这个图和中心线表示,整个车道图有固定大小的可学习表征,其中网络可以根据Bezier 控制点和图连通性学习车道中心线。
将每个实例表示为BEV 坐标中标准2D 框,包括五个参数:中心点位置、短边和长边的长度以及航向角。 除了实例的定位和方向之外,用one-hot表征生成语义/目标类,这样一个实例被完全识别。
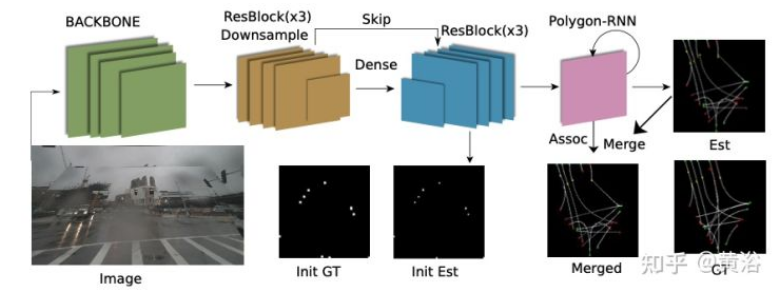
如图即是提出的总体架构图:网络的核心架构是转换器,将学习的道路中心线和目标查询一起处理;处理后的线查询用于输出检测概率、控制点和道路中心线关联特征;目标查询用于计算类概率和定向目标框参数。

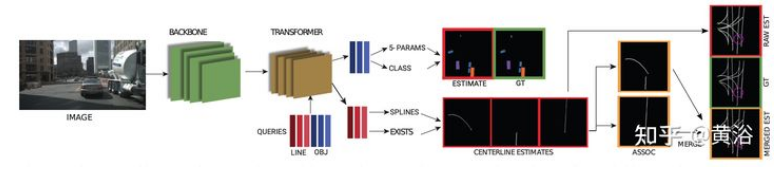
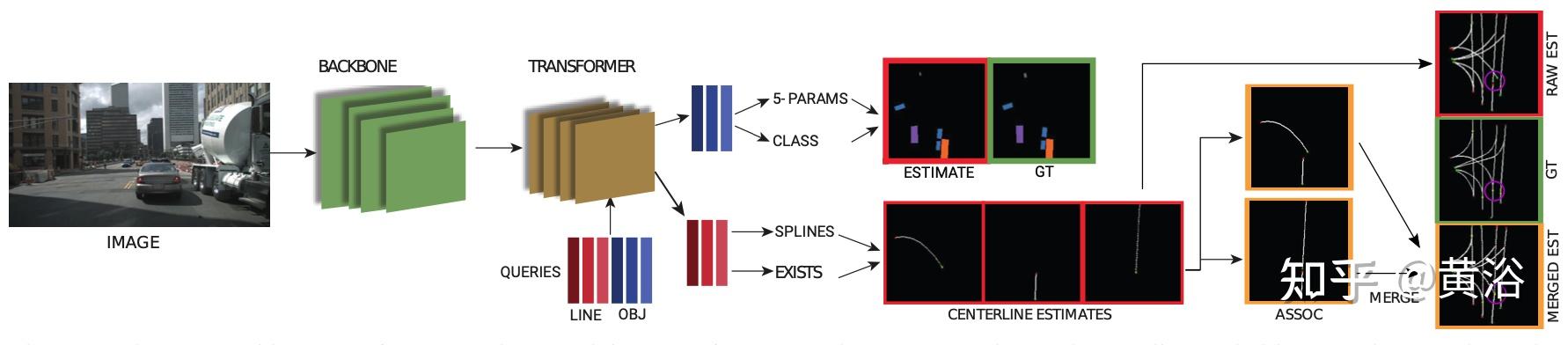
处理transformer 输出有两个分支:
第一个是车道分支,它有四个部分: 检测头(中心线存在概率)、控制头(Bezier 控制点)、关联头(关联特征向量)和关联分类器(关联中心线概率)。在训练期间,首先输出中心线控制点和检测概率,并在估计中心线和GT中心线之间用匈牙利匹配算法。 关联步骤是在匹配估计上执行的。 在推理中,对中心线的检测概率进行阈值处理,并对活跃的中心线执行关联步骤。
第二个是目标分支,处理transformer提议向量,包括两个模块和一个可选的后处理网络。第一个模块是检测头:对transformer 输出处理产生类概率分布,包括“无检测”类;第二个是5-params head:一个 MLP + sigmoid 层,产生定向目标框的归一化参数;后处理网络是Refinement net:细化网络将实例估计转换为语义分割。细化网络的结构类似于 BEV 解码器,其中较低分辨率的输入被放大以提供细粒度的分割图。
由于transformer没有位置概念,采用位置嵌入(PE)。系统用了两种不同的位置嵌入,第一个编码图像域空间信息,在归一化累积位置使用正弦函数;第二个位置嵌入对给定像素相应 BEV 位置进行编码。
设计了两个位置嵌入(图像和 BEV),使得它们是输入特征图通道大小的一半。因此,将图像位置嵌入添加到一半通道中,将 BEV 位置嵌入添加到另一半。这种双重位置嵌入称为分开位置编码(split positional encoding)。
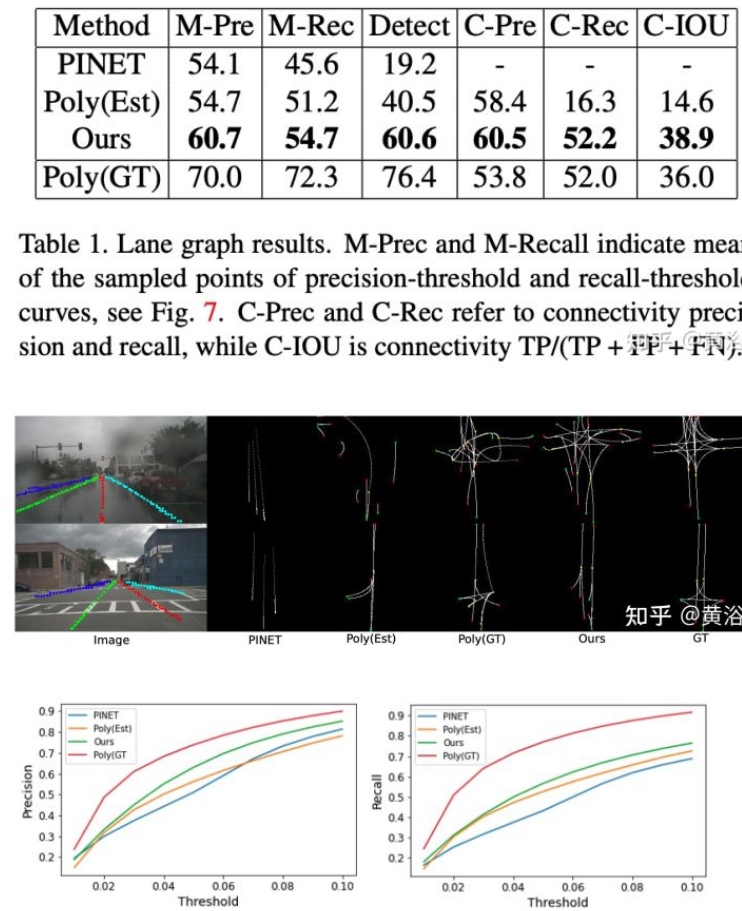
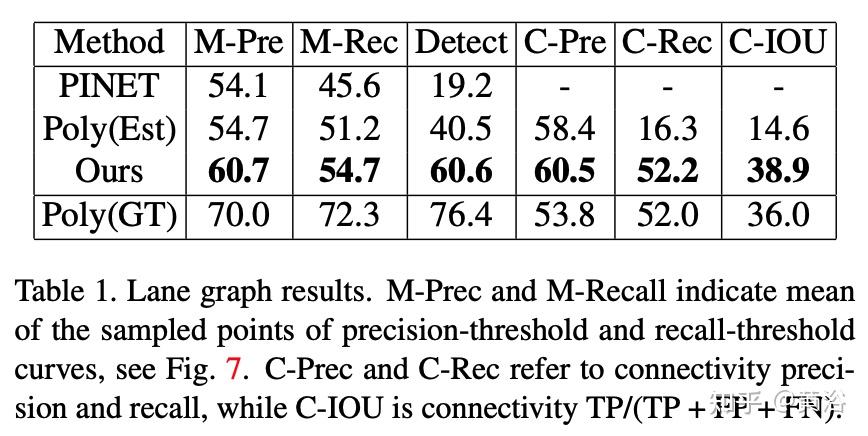
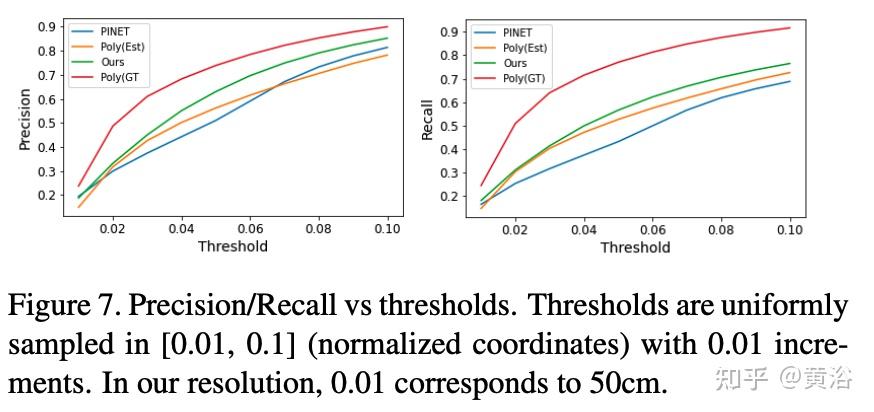
测度包括三种:precision-recall、detection ratio和connectivity。如图所示:

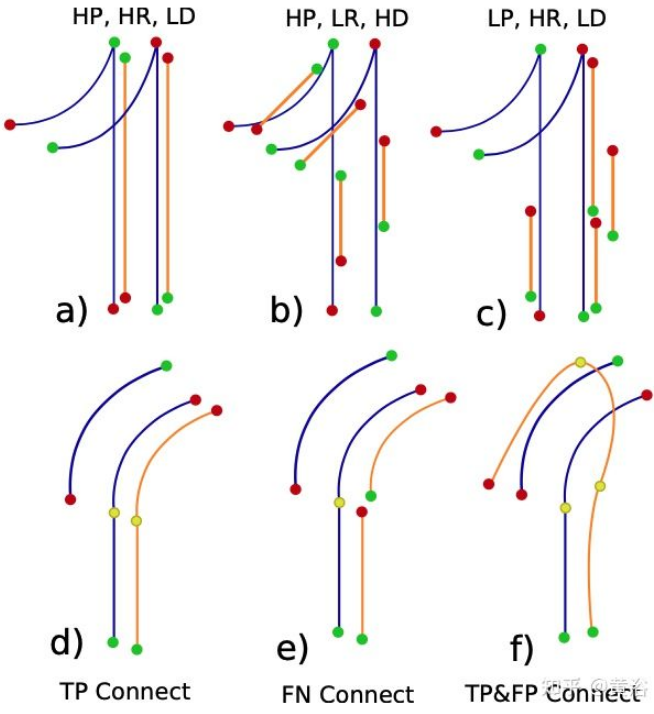
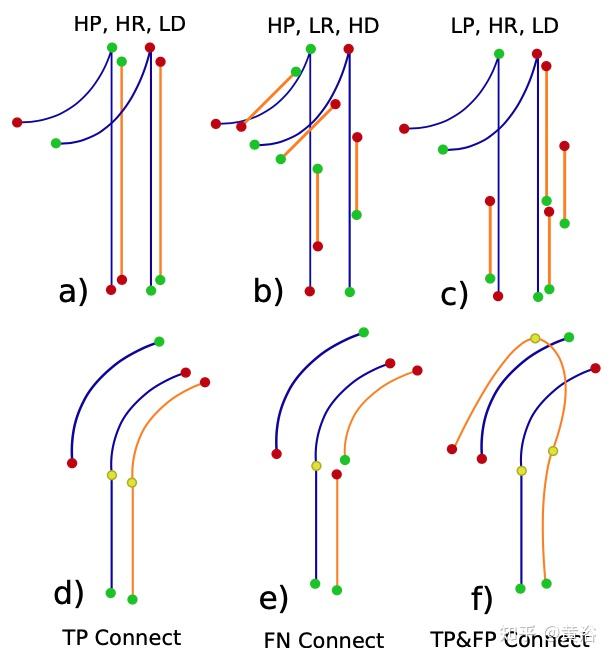
蓝线是GT中心线,橙色是估计值。 绿/红点分别代表起点和终点。 黄点表示连接,仅在从绿色到红色的方向有效。 H/L 是指高/低,而 P=Precision,R=Recall 和 D=Detection。 a) 4 线中有 2 线丢失,但匹配的线是准确的。 b) 匹配的GT线比估计长,造成FN。 c) 所有估计都与一条GT线相匹配(注意最左边估计的终点颜色),在产生FP的同时没有留下 FN的空间。 d) 和 e) 分别显示TP和 FN连通性。 f) 一个连接是TP,但最上面的连接是FP。
实验的基线方法,一个是基于CVPR‘18 论文“Hierarchical recurrent attention networks for structured online maps“,记做Polyline-RNN;另一个是arXiv2020 论文“Key points estimation and point instance segmentation approach for lane detection“,记做PINET。
如图是第一个方法中Polyline-RNN提取初始的点估计构建中心线曲线:

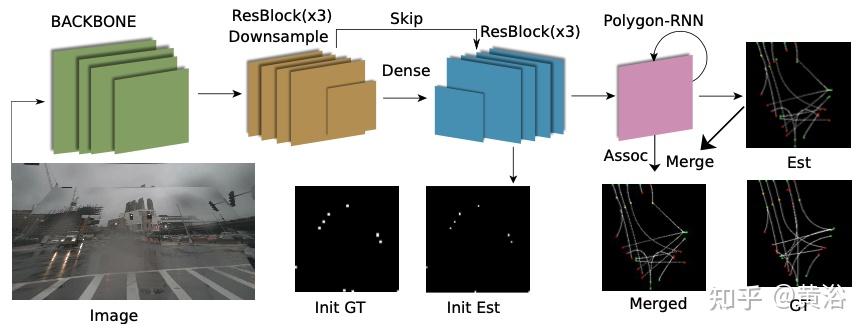
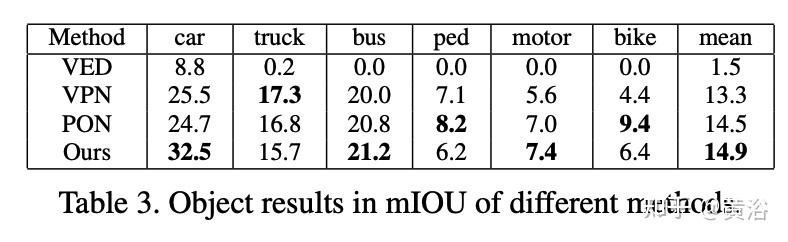
单做实例估计的基准方法还有:
- VED(“Monocular semantic occupancy grid mapping with convolutional variational encoder-decoder networks“. IEEE Robotics Autom. Lett., 2019),
- VPN (“Cross-view semantic segmenta- tion for sensing surroundings”. IEEE Robotics Autom. Lett., 2020)
- PON(“Predicting seman- tic map representations from images using pyramid occupancy networks“. CVPR 2020)
结果如下:







内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢