

这篇论文由Hugging Face牵头,如果用一连串数字来概括这篇论文,我们就会发现“大力真的可以创造奇迹”:
- 一共收集了171个多任务数据集,总共创建了1939个prompt,平均每个数据集有11.3个prompt;
- 共有来自8个国家、24家机构的36位人员贡献prompt;
- 基于包含prompt的数据集进行多任务学习(模型为11B的T5),Zero-Shot性能大幅超越大16倍的GPT-3模型;
- 与Google的同期工作Instruction Tuning(FLAN模型)[1]相比,Zero-Shot性能在各数据集上几乎均有提升或可比,而模型参数减少10倍(Google的FLAN模型为137B);
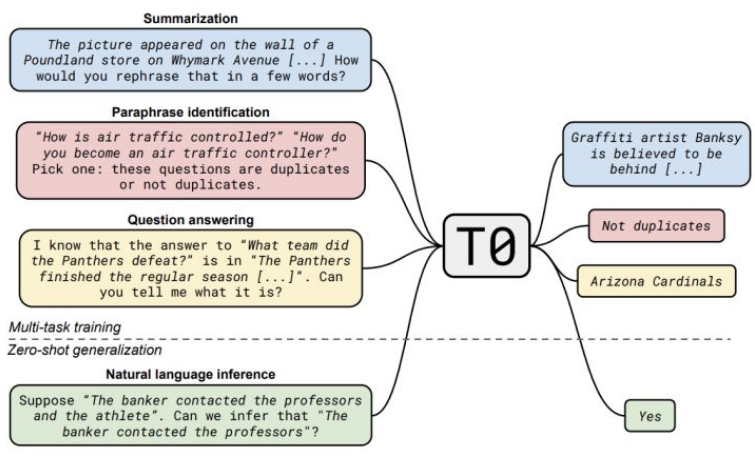
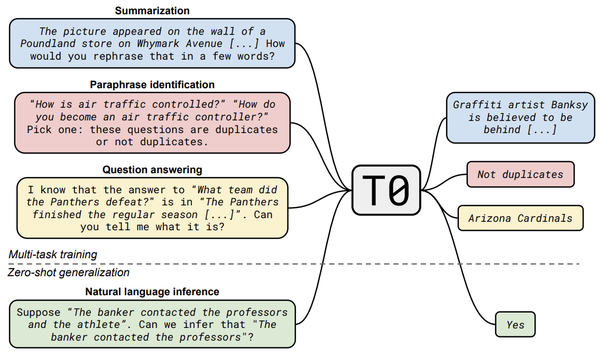
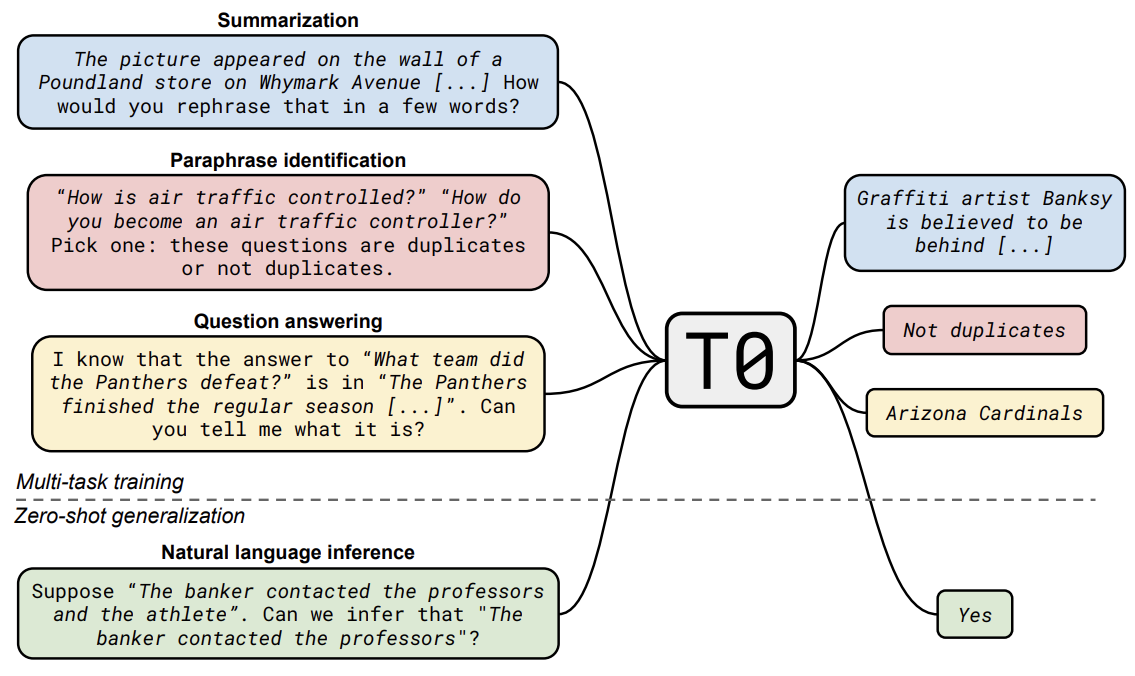 我们可以发现:如此“耗资巨大”的工程,将prompt+多任务学习紧密结合起来,也许是提升Zero-Shot性能的“完美配方”。
我们可以发现:如此“耗资巨大”的工程,将prompt+多任务学习紧密结合起来,也许是提升Zero-Shot性能的“完美配方”。此外,很多读者也许会发现,这篇论文不就是Instruction Tuning方法吗?
事实上,本篇论文与Google的Instruction Tuning思想相同,都是将包含prompt的数据集进行多任务学习,在下游未见任务进行Zero-Shot性能测试。不过,仍有很多细节和性能不相同,接下来就让我们一起一探究竟吧~
1、Instruction Tuning回顾
当前,NLP发展正进入第四范式[2]——prompting时代:预训练语言模型加持下的Prompt Learning。
CMU博士后研究员刘鹏飞在综述论文[3]中定义了Prompt的两种主要形式:
- 填充文本字符串空白的完形填空(Cloze)prompt;
- 用于延续字符串前缀的前缀 (Prefix) prompt;
而Google的Instruction Tuning中的Prompt形式更像是一种更明显的指令/指示(可以归为第三种Prompt形式):
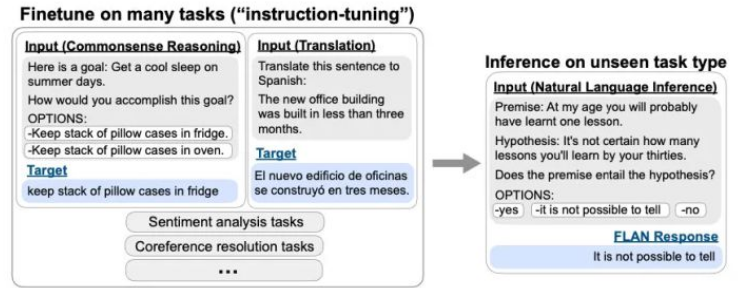
需要注意的是:Instruction Tuning采用多任务学习机制,整个LM模型参数是需要tuned的。构建了大量的多任务数据集;
- 为每个数据构建了“指令式”的prompt;
- 采用多任务学习机制进行训练;
- 更加关注下游任务的Zero-Shot性能;
本篇论文继承了Instruction Tuning思想,下面重点介绍本篇论文的数据集选择和Prompt设计。
2、多任务数据集选择
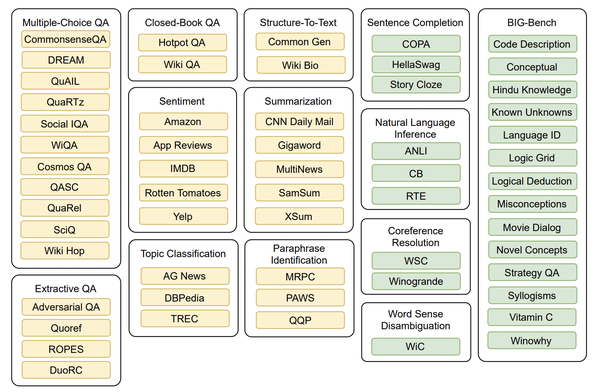
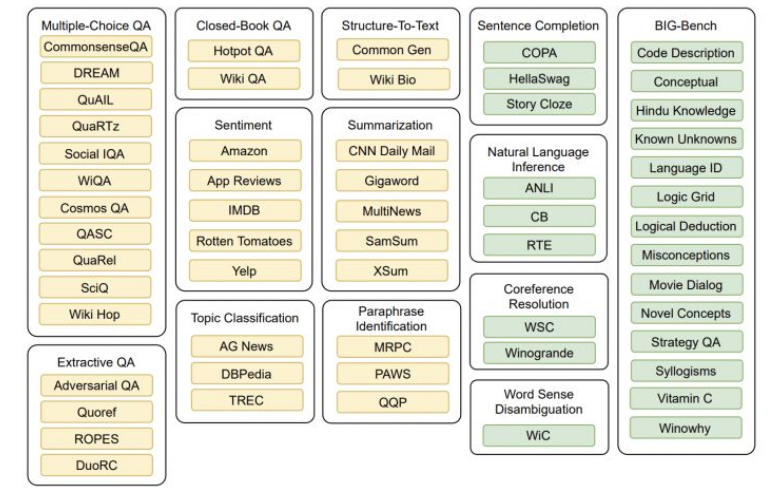
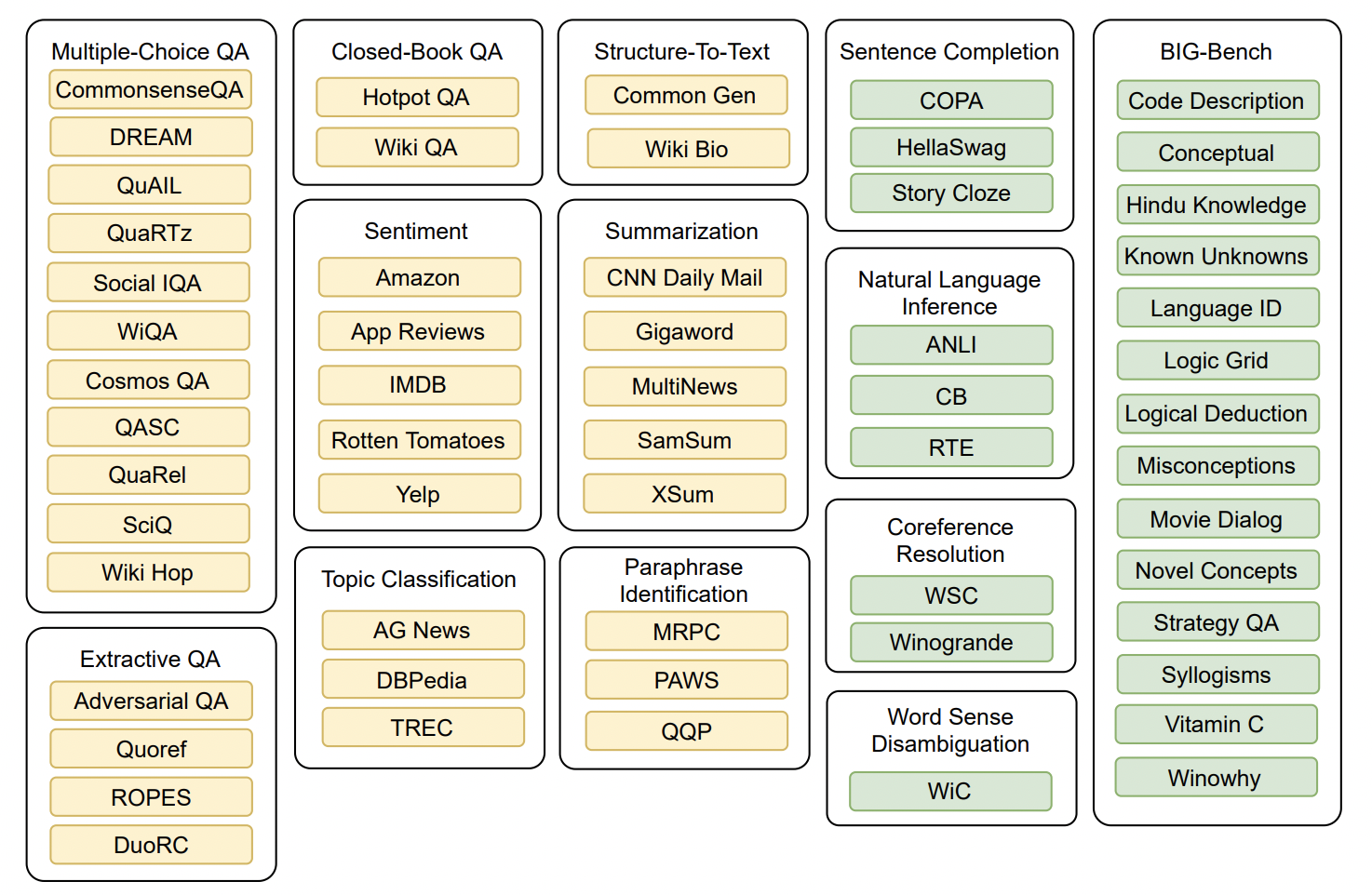
如上图所示,本篇论文在构造多任务数据集(共171个)时,将黄色部分的任务数据作为训练集,而绿色部分的任务数据作为Zero-Shot测试集。其中,BIG-Bench是一个新的基准评测,创建了多样化的困难任务集合来评测大型语言模型的能力。
数据构建的基本原则就是:Zero-Shot测试集中的数据未在训练集中出现。
3、Prompt设计
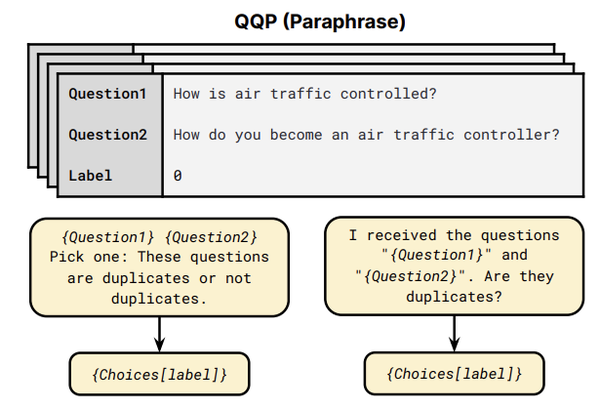
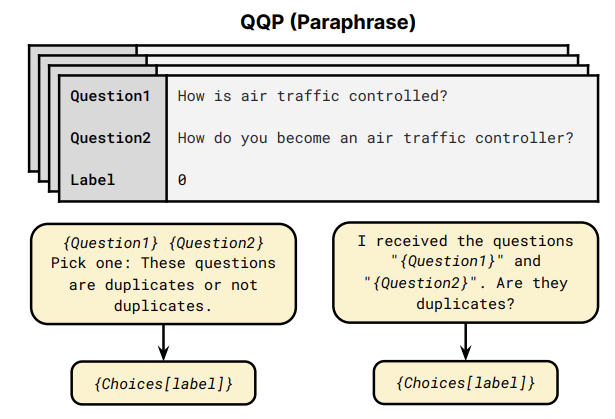
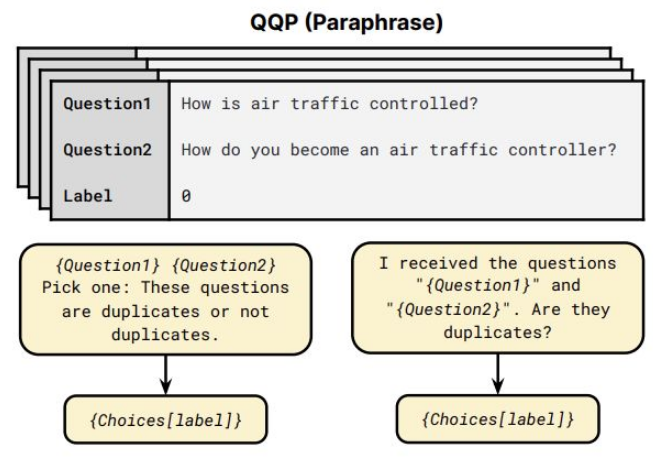 这里,JayJay以QQP任务为例(如上图所示),来介绍本篇论文的Prompt设计,共由两部分模板组成:
这里,JayJay以QQP任务为例(如上图所示),来介绍本篇论文的Prompt设计,共由两部分模板组成:- input template:{Question1}{Question2}Pick one:These questions are duplicates or not duplicates.
- output template:{Choices[label]} 当label=0时,输出为Not duplicates
Hugging Face开发了1个交互式程序用于编写Prompt。为了使模型更加鲁棒,鼓励用户以自己的风格开发创建更加多样化的prompt。共有来自8个国家、24家机构的36位人员参与了prompt贡献。
Prompt开发地址为:https://github.com/bigscience-workshop/promptsource ,感兴趣的小伙伴可以尝试下。本篇论文最终共收集了1939个prompt,所有构建的prompt集合P3(Public Pool of Prompts)也进行了开源(见论文附录G)。
4、实验结果
论文是基于T5+LM模型(基于T5进一步做LM训练)进行训练的,模型参数为11B。经过多任务prompt训练的模型为:
- T0:基于构建的171个多任务数据集进行训练;
- T0+:除T0数据集外,新增GPT3的验证集;
- T0++:除T0数据集外,新增GPT3和SuperGLUE的验证集;
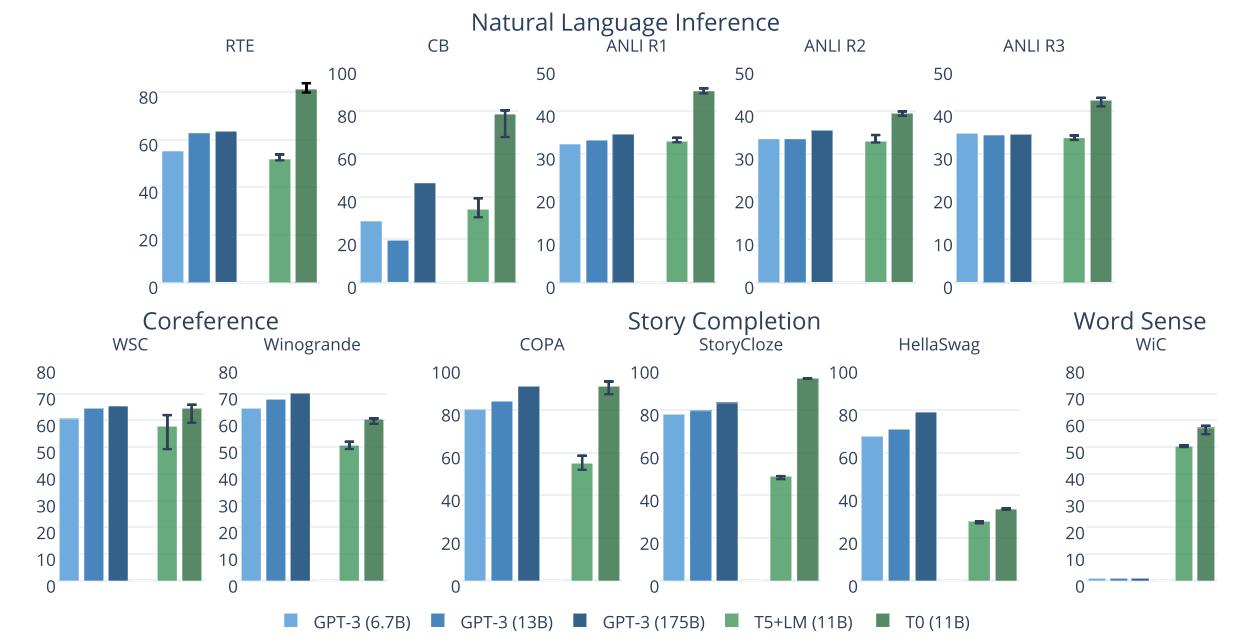
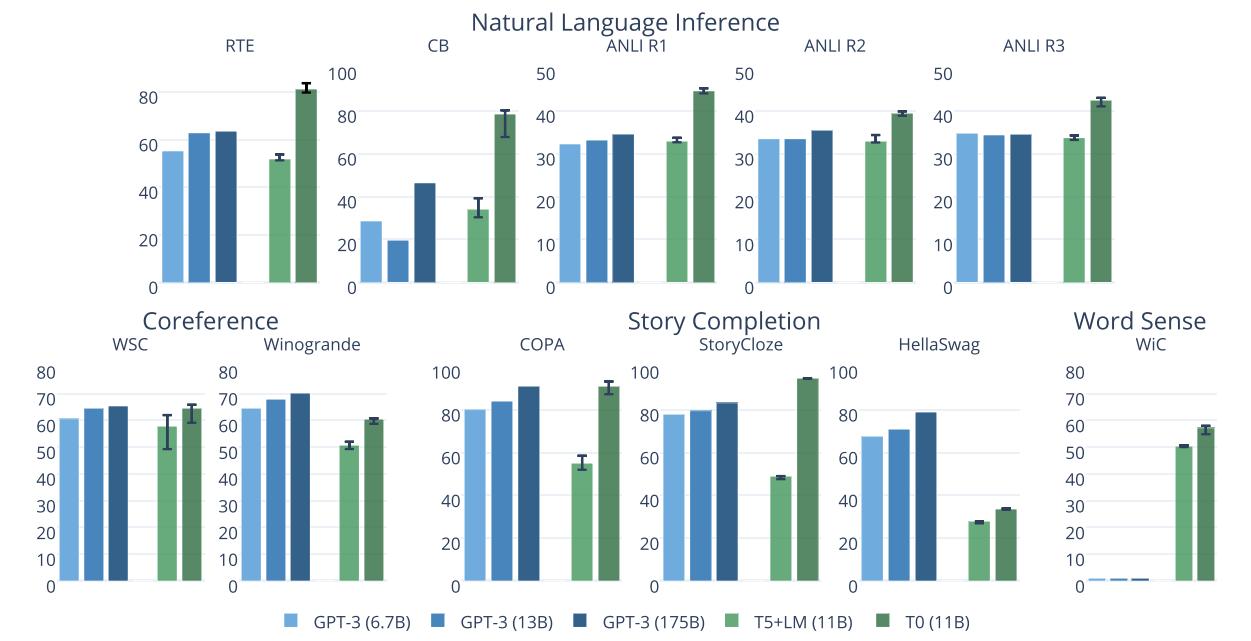
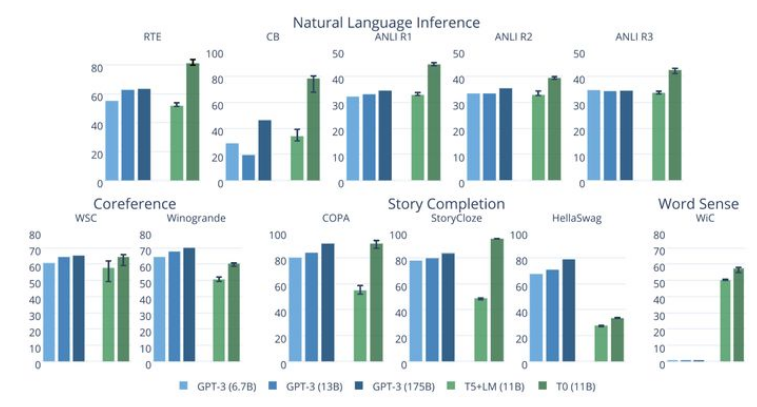 上图给出了T0与GPT-3的Zero-shot性能对比,T0模型在11个数据上中有8个超越了GPT-3。而T0模型比GPT-3比小16倍,GPT-3预训练过程也可看作是基于prompt进行多任务学习的。
上图给出了T0与GPT-3的Zero-shot性能对比,T0模型在11个数据上中有8个超越了GPT-3。而T0模型比GPT-3比小16倍,GPT-3预训练过程也可看作是基于prompt进行多任务学习的。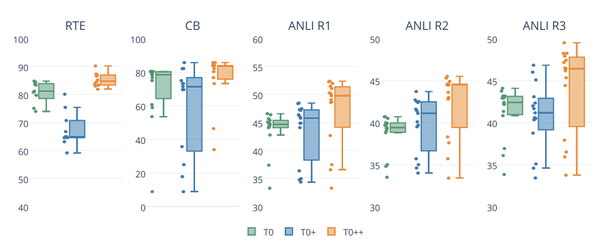
不过实验也发现:增加更多训练集数据会不会一致性提升Zero-Shot性能(如上图所示)。
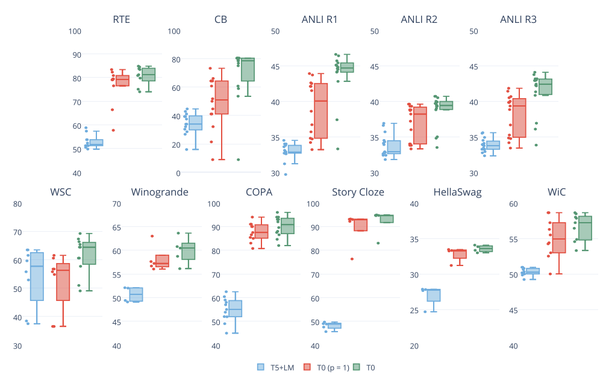
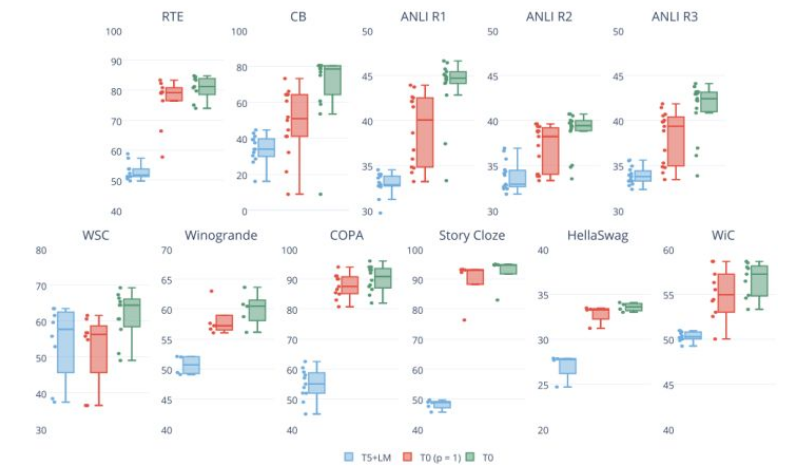
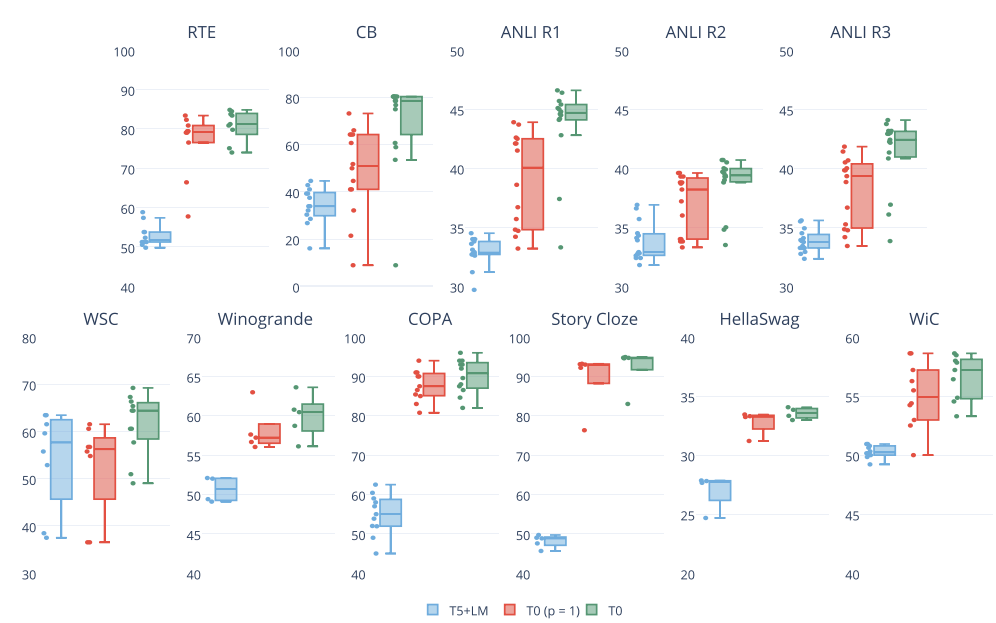
此外,实验也表明:增加更多的Prompt数量,会提升Zero-Shot泛化性能。
5、T0 vs FLAN
上文提到过,本文的T0模型与Google的FLAN模型均属于Instruction Tuning思想,但仍有一些细节区别:
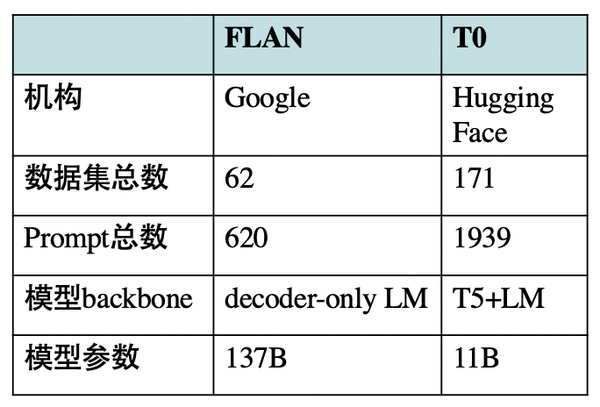
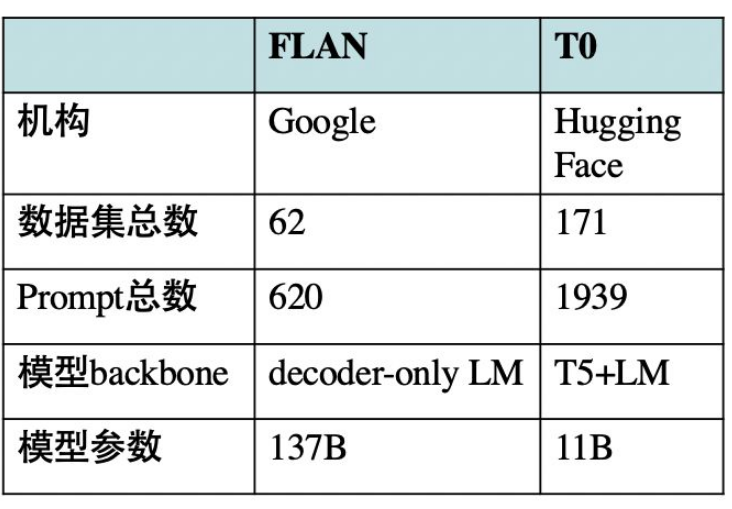
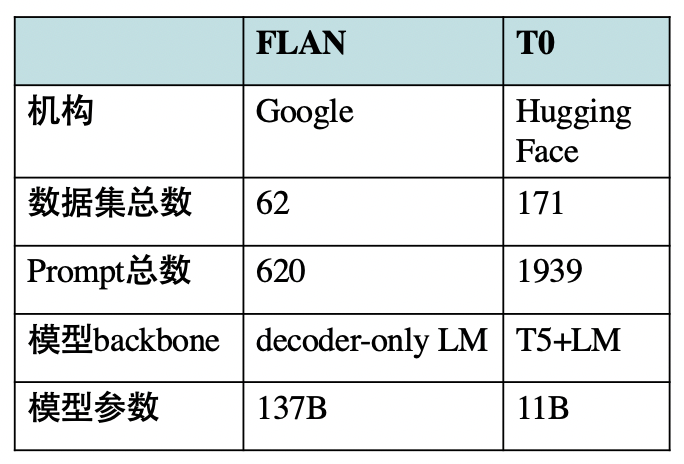
此外:
- T0++模型几乎在所有任务上超越或比肩FLAN模型,T0模型比FLAN模型小10倍。然而相同量级(8B)的FLAN模型,在多任务学习之后的Zero-Shot性能会下降。
- FLAN模型发现prompt个数增加反而会降低性能,而T0模型不会。这说明本篇论文构建的prompt更加多样化,从而使模型更加鲁棒、泛化能力更强。
6、总结与思考:
这篇论文构建的prompt数目多达1939个,虽然有程序界面进行设计,但仍然逃脱不了需要人工参与。
prompting时代或许更应该关注prompt的高效设计,比如:如何自动挖掘模板。而prompt-tuning怎样更好地融入多任务学习中,也值得进一步探讨。
此外,本文采用T5这种条件生成模型对所有不同任务进行了统一建模,JayJay更觉得:当前NLP发展正进入一个“大一统时代”:
- 框架统一:不同NLP任务可采用统一的模型框架建模,如Seq2Seq框架基本上可以建模所有NLP任务。
- 数据统一:不同NLP任务的数据可以融合prompt构建统一的数据形式,如指令式的prompt。
- 训练统一:训练方式可采取统一的多任务学习机制。
参考资料
[1] Finetuned Language Models Are Zero-Shot Learners: https://arxiv.org/pdf/2109.01652.pdf
[2] Fine-tune之后的NLP新范式:Prompt越来越火,CMU华人博士后出了篇综述文章: https://zhuanlan.zhihu.com/p/395795968
[3] Finetuned Language Models Are Zero-Shot Learners: https://arxiv.org/pdf/2107.13586.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢