
论文题目:Contrastive Information Extraction with Generative Transformer
作者单位:浙江大学 & 阿里巴巴
论文链接:https://ieeexplore.ieee.org/document/9537684
作者提出了基于对比学习的生成式信息抽取模型(CGT)。该框架基于一个共享的Transformer模块,采用编码器-解码器的生成式N元组抽取和对比学习的多任务学习模式。我们首先使用分隔符和部分因果掩码机制将输入序列与目标序列连接起来,以区分编码器-解码器表示形式。然后,我们提出一个N元组对比优化目标来约束模型,其中真实的N元组作为正样本,随机采样的N元组构作为负样本。为了同时优化N元组生成目标和对比学习目标,我们引入了分批的动态注意掩码机制,该机制允许我们动态选择不同的掩码机制并优化任务。最后,我们采用了一种N元组校准算法,在推理阶段过滤掉违背事实的N元组。
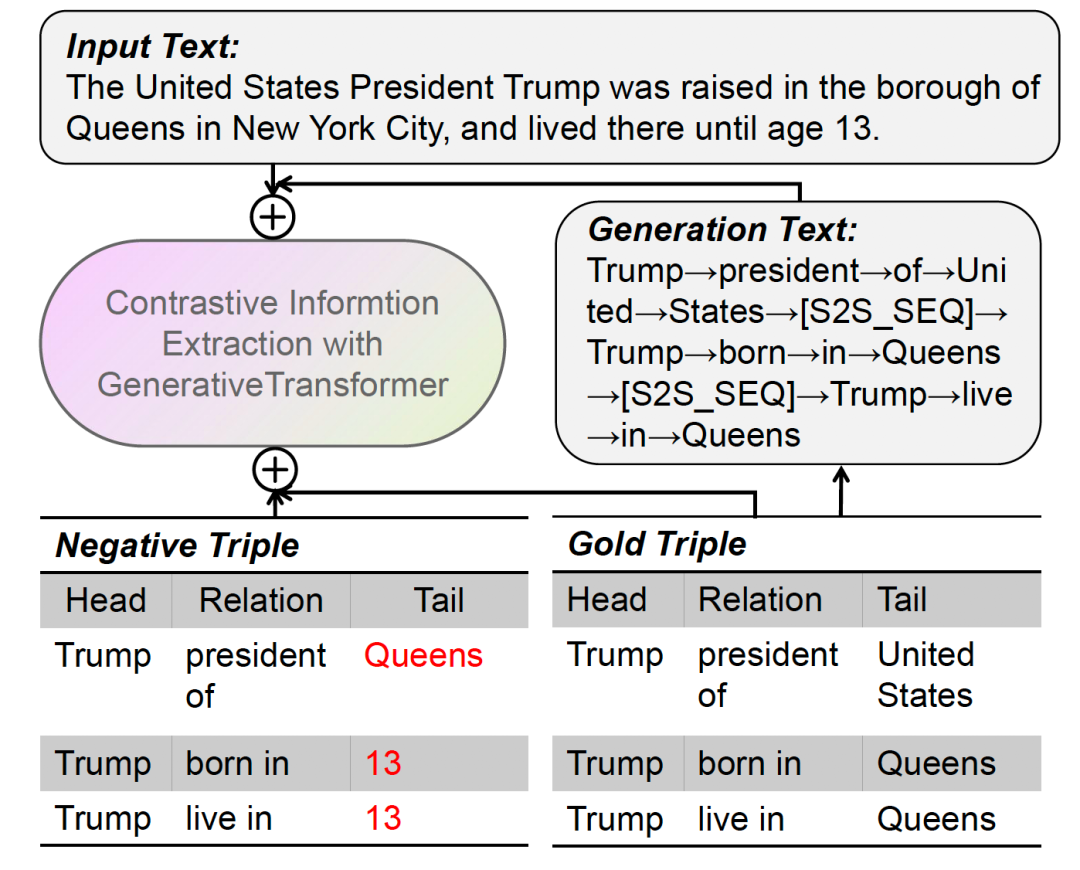
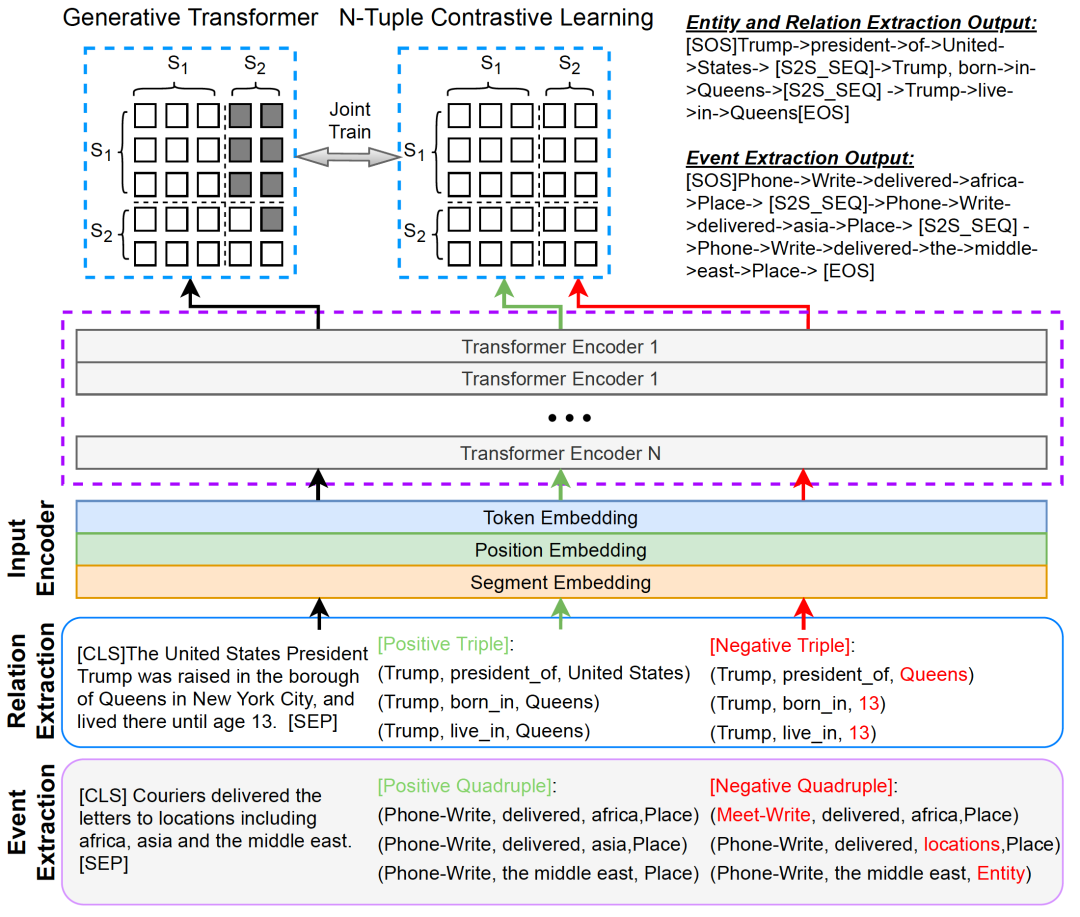
下图是我们模型的总体架构。其中,右上部分表示Transformer生成模块,右下部分表示N元组对比学习模块。这两个部分训练时共同优化。生成模块依靠部分因果掩码机制建模成序列生成任务,如右图中的示例所示,对于N元组序列生成,其中右上部分设置为-∞以阻止从源段到目标段的注意力;左侧部分设置为全0,表示令牌能够看到输入的文本。我们采用交叉熵损失生成来优化N元组生成过程。对比学习模块将输入文本与正确的N元组实例或者伪造的N元组进行拼接,依靠部分因果掩码机制建模成文本分类任务,其中mask矩阵的元素全为0,利用经过MLP多层感知机层的特殊token[CLS]表示来计算分类打分函数,以鉴别是否为正确实例。我们同样利用交叉熵优化对比损失。生成损失与对比学习损失通过一个超参数权衡构成了我们最终的总体损失。在解码过程中,我们采用基于启发式规则的beam search来生成N元组知识。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢