

近年来,很多轻量级的骨干网络问世,各种NAS搜索出的网络尤其亮眼。但这些算法的优化都脱离了产业最常用的Intel CPU设备环境,加速能力也往往不合预期。百度飞桨图像分类套件PaddleClas基于这样的产业现状,针对Intel CPU及其加速库MKLDNN定制了独特的高性能骨干网络PP-LCNet。比起其他的轻量级SOTA模型,该骨干网络可以在不增加推理时间的情况下,进一步提升模型的性能,最终大幅度超越现有的SOTA模型。
论文链接:https://arxiv.org/pdf/2109.15099.pdf
代码:https://github.com/PaddlePaddle/PaddleClas
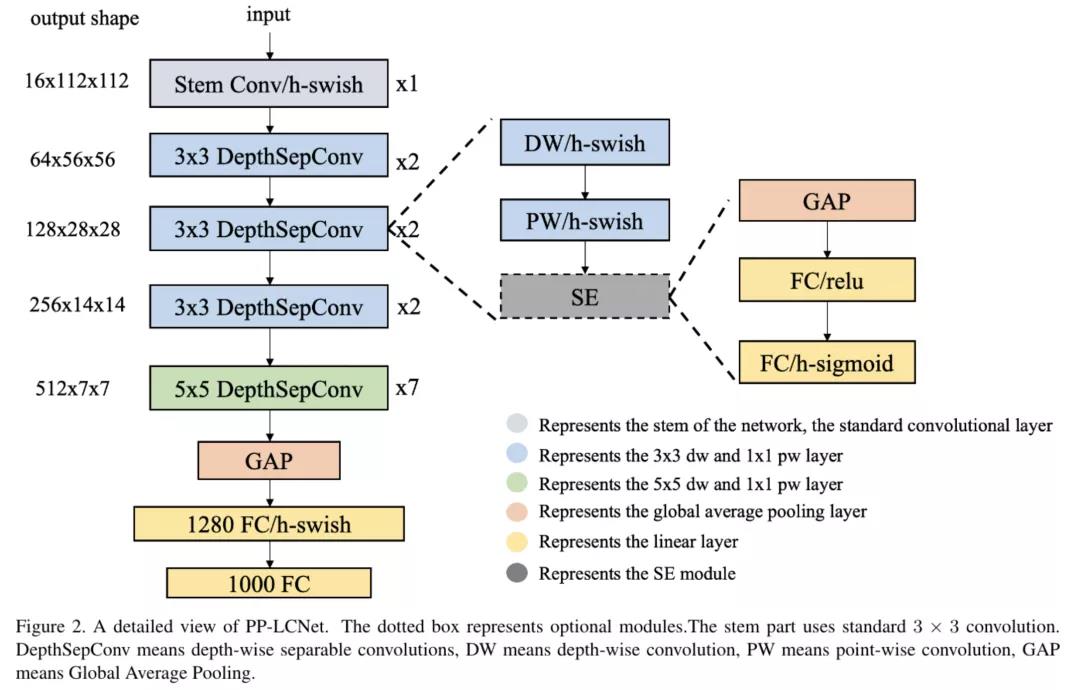 PP-LCNet的网络结构整体如上图所示。经过大量的实验发现,在基于Intel CPU的设备上,尤其当启用MKLDNN加速库后,很多看似不太耗时的操作反而会增加延时,比如elementwise-add操作、split-concat结构等。所以作者最终选用结构尽可能精简、速度尽可能快的block组成BaseNet(类似MobileNetV1)。基于BaseNet,通过实验,作者总结出四条几乎不增加延时但又能够提升模型精度的方法:
PP-LCNet的网络结构整体如上图所示。经过大量的实验发现,在基于Intel CPU的设备上,尤其当启用MKLDNN加速库后,很多看似不太耗时的操作反而会增加延时,比如elementwise-add操作、split-concat结构等。所以作者最终选用结构尽可能精简、速度尽可能快的block组成BaseNet(类似MobileNetV1)。基于BaseNet,通过实验,作者总结出四条几乎不增加延时但又能够提升模型精度的方法:
-
更好的激活函数:H-Swish;
-
合适的位置添加SE模块:SE模块越靠近网络的尾部对模型精度的提升越大;
-
更大的卷积核:更大的卷积核放在网络的中后部即可达到放在所有位置的精度,与此同时,获得更快的推理速度;
-
GAP后使用更大的1x1卷积层:GAP后的特征便不会直接经过分类层,而是先进行了融合,并将融合的特征进行分类。这样可以在不影响模型推理速度的同时大大提升准确率。
PP-LCNet并不是追求极致的FLOPs与Params,而是着眼于深入技术细节,耐心分析如何添加对Intel CPU友好的模块来提升模型的性能来更好地进行准确率和推理时间的平衡,其中的实验结论也很适合其他网络结构设计的研究者,同时也为NAS搜索研究者提供了更小的搜索空间和一般结论。
本论文工作的总体研究思路由飞桨PaddleClas团队提出并实施。PaddleClas提供全球首个开源通用图像识别系统,并力求为工业界和学术界提供更高效便捷的开发工具,为开发者带来更流畅优质的使用体验,训练出更好的飞桨视觉模型,实现行业场景实现落地应用。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢