
前言 本文介绍了什么是增量学习:增量式学习模型;它的挑战是什么:避免为了新类的好处而忘记以前的类;以及解决该领域的三大策略。
人类智能的标志是学习能力。我们每天都在学习新概念,更重要的是我们能够记住所学。没有这种能力,我们很难提高自己。我们的算法能做到吗?
最近的深度学习炒作旨在达到通用人工智能(Artificial General Intelligence, AGI):一种可以表达(超)类人智能的人工智能。不幸的是,当前的深度学习模型在很多方面都存在缺陷:其中之一是它们无法像人类一样通过多年的学校教育持续学习。
为什么希望模型不断学习?
不管 AGI 的远期目标如何,我们希望模型不断学习有几个实际原因。在描述其中一些之前,我将提到两个约束:
-
模型无法在每次需要学习新事实时回顾所有以前的知识。
-
模型需要不断学习,而不会忘记任何先前学到的知识。
这两个约束的一个实际应用是机器人技术:野外的机器人应该不断地学习它的环境。此外,由于硬件限制,它既不能存储所有以前的数据,也不能花费太多的计算资源。
另一个应用是我在 Heuritech 所做的:我们检测时尚趋势。然而,全球每天都可能出现新的趋势。每次我们需要学习一个新的数据库时,都要查看我们的大型趋势数据库是不切实际的。
既然已经解释了持续学习的必要性,让我们区分三种情况:
-
学习已知类的新数据--在线学习
-
学习新类--类增量学习(class-incremental learning)
-
前两个场景的结合
在本文中,我将只关注第二种情况。但是请注意,场景之间使用的方法非常相似。
更实际地,本文将介绍逐步学习新类的模型。该模型将只看到新类的数据,因为我们的目标是记住旧类。在每个任务之后,使用单独的测试集在所有可见的类上训练模型:

增量学习的几个步骤。
如上图所示,每一步都会产生一个新的准确度分数。遵循 (Rebuffi et al, 2017) 的最终得分是之前所有任务准确率得分的平均值。它被称为平均增量精度。
原始的解决方案:迁移学习
迁移学习允许将在一项任务(例如 ImageNet 及其 1000 个类别)中获得的知识转移到另一项任务(例如对猫和狗进行分类)。通常保留主干网络,同时在其上插入新的分类器。在迁移过程中,我们训练新分类器并微调主干网络。
微调主干对于在目标任务上达到良好的性能至关重要。但是,我们无法再访问原始任务数据。因此,我们的模型现在仅针对新任务进行了优化。而在训练结束时,我们会在这个新任务上有很好的表现,而旧任务的性能会大幅下降。
(French, 1995) 将这种现象描述为灾难性的遗忘。为了解决这个问题,我们必须在刚性(擅长旧任务)和可塑性(擅长新任务)之间找到最佳平衡点。
三大策略
(Parisi 等人,2018 年)定义了 3 种减少遗忘的广泛策略:
-
存储少量先前任务数据的外部存储器
-
基于约束的方法避免忘记以前的任务
-
模型可塑性扩展能力
1. 外部存储器
如前所述,由于多种原因,我们无法保留所有以前的数据。但是,我们可以通过限制对先前数据的访问限制来放松此约束。
排练学习( Rehearsal learning ) 的 iCaRL 假设我们处理了有限的空间来存储以前的数据。我们的外部存储器可以有 2,000 张图像的容量。学习新类后,其中一些类数据可以保留在其中,而其余的将被丢弃。

使用存储先前数据子集的内存进行增量学习的几个步骤。
伪排练学习( Pseudo-Rehearsal learning )假设我们不能保留以前的数据,如图像,但我们可以存储类分布统计数据。有了这个,生成模型可以生成即时的旧类数据。然而,这种方法非常依赖于生成模型的质量;生成的数据仍然低于真实数据。此外,避免在生成器中遗忘仍然很重要。

使用生成器生成先前数据的增量学习的几个步骤。
通常,基于(伪)排练的方法优于仅使用新类数据的方法。然后分别比较它们的性能是公平的。
2. 基于约束的方法
直观地说,强制当前模型与其以前的版本相似将避免遗忘。有大量方法旨在做到这一点。然而,它们都必须平衡刚性(鼓励两个模型版本之间的相似性)和可塑性(让新模型有足够的松弛来学习新的类)。
我们可以将这些方法分为三大类:
-
强制执行相似性的激活
-
强制权重相似
-
强制梯度相似
2.1.约束激活
(Li and Hoiem, 2016) 的 LwF 引入了知识蒸馏:给定相同的图像,当前模型的基本概率应该与旧模型的概率相似:

基础概率从以前的模型提炼到新模型。
蒸馏损失可以简单地是新旧概率之间的二元交叉熵。
模型输出概率只是其中的一种激活。(Hou et al, 2019) 的 UCIR 在新旧模型的提取特征 h 之间使用了基于相似性的方法:
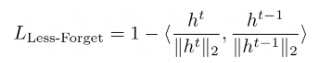
把它想象成放置“锚点”来避免新嵌入的漂移:

新模型嵌入必须与旧模型相似。
总而言之,鼓励新模型模仿其先前版本的激活可以减少对旧类的遗忘。
2.2.约束权重
一种不同但相似的方法是减少新旧模型权重之间的差异。
![]()
我们将简单地最小化 L2 距离,如左侧所示。
然而,正如 (Kirkpatrick et al, 2016) 的 EWC 所评论的那样,由此产生的新权重对于新旧类都表现不佳。然后,作者建议根据神经元重要性调整正则化。
任务 T-1 的重要神经元在新模型中不得改变。另一方面,可以更自由地修改不重要的神经元,以有效地学习新任务 T:
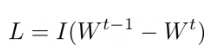
其中 I 是根据任务 T-1 的旧权重定义的神经元重要性矩阵。
在 EWC 中,神经元的重要性是用由梯度方差近似的 Fisher 信息定义的。后续研究(Zenke 等人,2017 年;Chaudhry 等人,2018 年)基于相同的想法,并改进了神经元重要性的定义。
2.3.约束梯度
最后存在第三类约束:约束梯度。由 (Lopez-Paz and Ranzato, 2017) 的 GEM 引入,关键思想是新模型的损失应该低于或等于旧模型在内存中存储的旧样本的损失(参见排练学习)。
![]()
鉴于 M 是旧模型之前见过的样本内存。
作者将此约束重新表述为梯度上的角度约束:
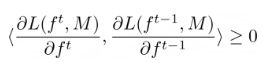
更简单地说,我们希望新模型的梯度与之前模型的梯度“同向”。
如果遵守此约束,则新模型很可能不会忘记旧类。否则传入的梯度 g 必须是“固定的”:通过最小化这个二次程序,将它们重新投影到最接近的有效替代 g-波浪号:
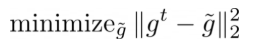
固定梯度必须与当前的——坏的——接近。
![]()
但固定梯度也必须与旧梯度方向相同。
这个过程可以更简单地示意如下:

梯度必须保持同一个方向,否则它们的方向是固定的。
正如您可能猜到的那样,在更新模型权重之前为每个违反梯度求解该程序的时间成本非常高。(Chaudhry 等人,2018 年;Aljundi 等人,2019 年)通过不同方式提高算法速度,包括对梯度约束的代表性子集进行采样。
3. 可塑性
其他算法修改网络结构以减少灾难性遗忘。第一个策略是向当前模型添加新的神经元。(Yoon et al, 2017) 的 DEN 首先训练新任务。如果它的损失不够好,就会在几层添加新的神经元,它们将专门用于学习新任务。此外,作者选择冻结一些已经存在的神经元。那些对旧任务特别重要的神经元不能为了减少遗忘而改变。

DEN 为新任务添加新神经元,并选择性地微调现有神经元。
虽然在我们的模型无限学习的增量设置中扩展网络容量是有意义的,但值得注意的是现有的深度学习模型被过度参数化。如果使用得当,初始容量足以学习许多任务。正如(Frankle 和 Carbin,2019 年)的彩票假说形式化的那样,大型网络由非常高效的子网络组成。
每个子网络只能专用于一项任务:

在一个大型单一网络中,可以发现多个子网络,每个子网络专门用于一项任务。
有几种方法可以发现这些子网络:PathNet 使用进化算法,(Golkar 等人,2019 年)使用 L1 正则化稀疏化整个网络,以及(Hung 等人,2019 年)的CPG 学习二进制掩码激活和停用连接以生成子网络。
值得注意的是,基于子网络的方法假设知道它们在哪个任务上进行评估,以便它们可以选择正确的子网络。这种称为多头的设置具有挑战性,但从根本上比单头评估更容易,单头评估在同一时间对所有任务进行评估。
处理类别不平衡
我们之前看到了三种避免遗忘的策略(排练、约束和可塑性)。这些方法可以一起使用。除了约束之外,还经常使用排练学习( Rehearsal learning )。
此外,增量学习的另一个挑战是新旧类之间的大类不平衡。例如,在某些基准测试中,新类可以由每个 500 张图像组成,而旧类每个只存储 20 张图像在内存中。
这种类别不平衡进一步错误地鼓励模型对新类别过度自信,而对旧类别缺乏自信。灾难性遗忘进一步加剧。
(Castro 等人,2018 年)在此类不平衡下为每个任务训练他们的模型,然后通过欠采样对其进行微调:对旧类和新类进行采样以获得尽可能多的图像。
(Wu 等人,2019)考虑使用重新校准:在验证中学习一个小的线性模型来“修复”对新类的过度自信。它仅适用于新类 logits。( Belouadah 和 Popescu,2019 年)同时提出了一个类似的解决方案来修复新的类 logits,但使用类统计数据。
(Hou et al, 2019) 评论说,分类器层的权重和偏差对于新类比旧类具有更大的幅度。为了减少这种影响,他们用一个余弦分类器代替了通常的分类器,其中权重和特征是 L2 归一化的。此外,他们冻结了与旧类别相关的分类器权重。
结论
在这篇文章中,我们看到了什么是增量学习:增量式学习模型;它的挑战是什么:避免为了新类的好处而忘记以前的类;以及解决该领域的三大策略。
这个领域远未得到解决。上限是在所有数据上一步训练的模型。当前的解决方案比这要糟糕得多。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢