
今天分享阿里的一篇将「目标蒸馏-logits方法」应用到推荐系统领域的论文, 其提出的蒸馏技术是工业界知识蒸馏用在推荐系统领域最广泛的技术之一,整篇文章思路比较朴素,对于工业应用具有非常大的借鉴意义。

论文链接:https://arxiv.org/pdf/1907.05171.pdf
有关知识蒸馏,请先阅读2015年Hinton的开山之作,讲解如下:Knowledge Distillation | 知识蒸馏经典解读
1. 背景
为了得到线上和线下特征的一致性(consistency), 我们通常只能选择那些线上和线下都能够获得的feature。但是,有的非常重要的特征只能在线下得到,在线上预测serving的时候是不能得到的。
比如,「用户停留时长」这个指标对于「CVR(用户点击之后购买的概率)」 的预测非常重要,但是在线上预测的时候我们根本拿不到这个特征,因为在线上需要在用户点击之前就预测CTR,CVR, 用户还没有点击怎么去获得用户停留时长?那为了保持线上线下特征的一致性,只能忍痛割爱,不用这个特征。
「这种信号强,但只能离线获取的特征,就叫优势特征(privileged features)」。
自然的想到,使用「多任务」学习来预测优势特征是一个可行的选择,同时预测这些优势特征和CVR、CTR。然而,在多任务学习中,每个子任务往往很难满足对其他任务的无害准则(No-harm Guarantee),换句话说,预测优势特征的任务可能会对原始的预测任务造成负面影响。而且,预测优势特征的任务甚至比原始任务来得更有挑战性!从实践的角度来看,如果同时预测非常多的优势特征,如何平衡各个任务的权重也会非常困难。
为了更优雅地利用优势特征,本论文提出优势特征蒸馏(「Privileged Features Distillation」,简称PFD)。
在离线环境下,我们会训练两个模型:一个Student模型以及一个Teacher模型。其中Student模型和原始模型完全相同,只使用那些线上线下都有的特征;而教师模型额外利用了优势特征, 其准确率也因此更高。通过将教师模型蒸馏出的知识 (Knowledge,论文中特指教师模型中最后一层的logit输出, 是软标签/平滑标签) 传递给学生模型,可以辅助其训练并进一步提升准确率。在线上服务时,我们部署学生模型,因为输入不依赖于优势特征,离线、在线的一致性也得以保证。
本文提出的PFD和普通的模型蒸馏(model distillation, MD)的区别在于,普通Model Distillation的Student和Teacher的输入相同,而Teacher的模型capacity明显大于Student,所以蒸馏的效果是降低模型参数。而PFD的Student和Teacher模型capacity一样,只是Teacher多加了优势特征。所以,这里的知识蒸馏并没有起到让模型轻量级的效果,而只是试图把Teacher学到的加入了优势特征的预测模型“教给”Student:

本模型在手淘的信息流推荐场景,运用在了粗排阶段的CTR预估、和精排阶段的CVR预估两个阶段上。在AB测试下,粗排阶段的CTR有5%的提升,精排阶段的CVR有2.3%的提升。
2. 淘宝推荐中的优势特征
手淘推荐的流程框架图如下。所有的商品从会经历三个阶段:召回、粗排、精排。这三个阶段待打分的商品数会逐渐减少,模型会越来越复杂。
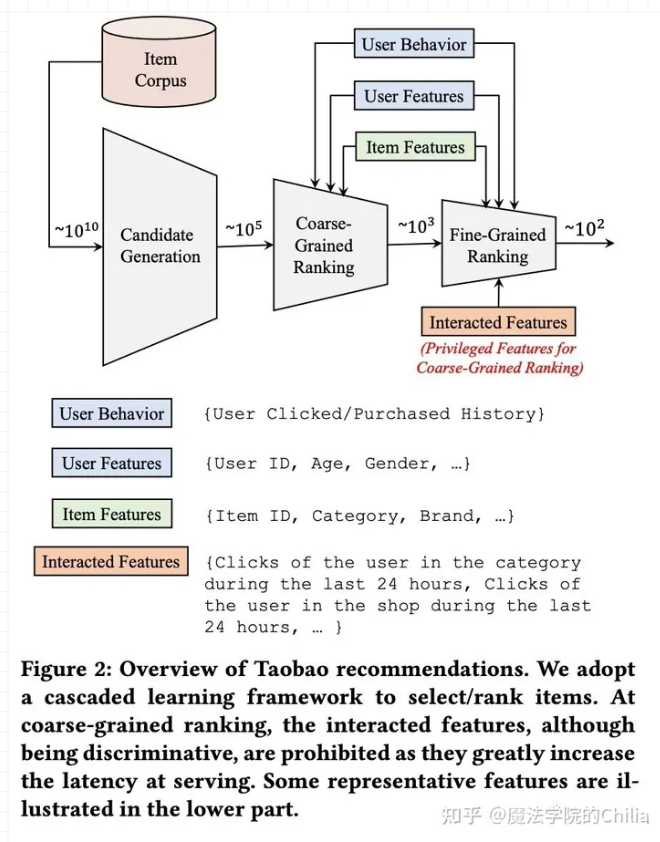
在粗排阶段,主要的任务是预估召回阶段返回的候选集中每个物品的CTR,然后选择排序分最高的一些物品进入精排阶段。粗排阶段输入的特征主要有用户的行为特征(如用户的历史点击/购买行为)、用户属性特征(如用户id、性别、年龄等)、物品特征(如物品id、类别、品牌等)。在粗排阶段,由于要在毫秒内给成千上万的候选物品打分,因此模型的复杂度受到了很大的限制,工业界传统的做法是使用「内积模型」,把用户侧和物品侧作为双塔。离线算好候选商品向量,在请求时,把用户向量和候选商品向量进行内积运算,从而对物品池做粗筛。
有一些「交叉特征」对粗排效果有明显的提升,比如用户在过去24小时内在待预估商品类目下的点击次数、用户过去24小时内在待预估商品所在店铺中的点击次数等。对于这些交叉特征,如果放到用户侧,那么针对每个物品都需要计算一次用户侧的塔;如果放到物品侧,同样针对每个物品都需要计算一次物品侧的塔,这会大大加大计算复杂度,增加线上的推理延时。因此,这些「交叉特征」对于粗排阶段的模型来说,通常在线上无法应用,我们就称它们为粗排CTR预估中的Privileged Features。
在精排阶段,我们不仅要预估CTR,还要预估CVR,即用户点击跳转到商品页后购买该商品的概率。在电商领域的推荐,主要目标是最大化GMV,即 GMV = CTR * CVR * Price 。一旦预估了所有商品的CTR和CVR,我们就可以根据预期的GMV对它们进行排名,使得GMV最大化。
在CVR的定义下,很明显「用户在商品页的行为特征」对于CVR预估会非常有帮助,比如说「用户在商品页停留的时长、是否查看评论、是否与商家沟通」等。但是,这些特征在线上预估阶段是无法获取的,因为商品在被用户点击之前就需要估计CVR以进行排序。所以对于CVR预估来说,用户在点击后进入到商品页的一些特征(比如停留时长、是否查看评论、是否与商家沟通等)同样是Privileged Features。
再比如,在短视频粗排或精排阶段要做多目标预估,即不仅要预估点击率还要预估该视频的点赞、评论、分享转发、进入个人主页、收藏、下载等互动目标。如果此时,用户点击该视频,并对该视频进行了观看。那么,用户的视频观看时长特征,对于互动目标的预估显的很重要,但是在线上推理时,我们需要在预估点击率之前就要估计互动目标,并不能获取到视频观看时长这一重要特征。因此,我们可以把用户观看视频时长特征作为Privileged Features。
3. 优势特征蒸馏
令X表示普通特征,X*表示优势特征,y表示标签,L表示损失函数,则特征蒸馏的目标函数抽象如下:
上面的损失函数被分为两部分,两部分都是计算交叉熵。损失的第一部分是可以称为hard loss,其label是0或者1;第二部分可以称为soft loss或distillation loss,其label是Teacher网络的Softmax输出,是概率值。
如上述公式中所示,教师模型的参数需要预先学好,这直接导致模型的训练时间加倍。所以,能不能同步更新学生和教师模型呢?同步更新的目标函数变成如下形式:
尽管同步更新能显著缩短训练时间,但也会导致训练不稳定的问题。尤其在训练初期,教师模型还处于欠拟合的情况下,学生模型直接学习教师模型的输出会导致训练偏离正常。解决这个问题的方法也非常简单,只需要在开始阶段将 设定为0,不让Student跟Teacher学;然后在预设的迭代步将 设为固定值。值得一提的是,我们让「蒸馏误差项(distillation loss)」 只影响学生网络的参数的更新,而对教师网络的参数不做梯度回传,从而避免学生网络和教师网络相互适应(co-adaption)而损失精度。也就是说,只能学生向老师学,而不能老师向学生学。
4. 优势特征蒸馏+模型蒸馏 (PFD+MD)
在上文中,我们比较了模型蒸馏(MD)和优势特征蒸馏(PFD)的异同,既然两者都能提升学生模型的效果且互补,一个直观的想法就是将这两种技巧结合在一起以进一步提升效果。
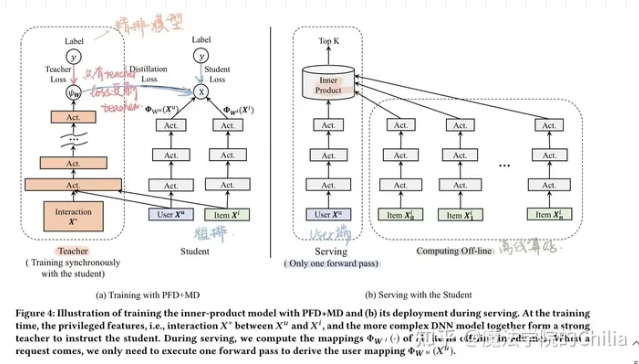
这里我们尝试在「粗排CTR」模型中使用这种PFD+MD技巧。在粗排中,我们使用「内积运算」对候选商品集合进行打分。事实上,无论采用何种映射表征用户或者商品,模型最终都会受限于顶层双线性(Bi-Linear)内积运算的表达能力。因为内积粗排模型可以看成是广义的矩阵分解。按照神经网络的万有逼近定理,非线性(Non-Linear)MLP,有着比双线性内积运算更强的表达能力,在这里很自然地被选为更强的教师模型。下图给出了粗排PFD+MD蒸馏框架示意图。事实上,图中加了优势特征的教师模型就是我们「线上精排CTR模型」,所以这里的蒸馏技巧也可以看成粗排反向学习精排的打分结果。
5. 实验
在手淘信息流的两个基础预测任务上PFD实验。在「粗排CTR」模型中,通过蒸馏「交叉特征」(在线构造特征以及模型推理延时过高,在粗排上无法直接使用)以及蒸馏表达能力更强的MLP模型,即通过MD+PFD可以在线提升CTR(同时保证CVR指标不降)。在「精排CVR」模型上,通过蒸馏停留时长等「后验特征」,只对PFD做测试,对比Baseline提升CVR(并且CTR不降)。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢