
本文分享 NeurIPS 2021 论文『Augmented Shortcuts for Vision Transformers』,由北大&华为联合提出用于 Vision Transformer 的Augmented Shortcuts,涨点显著!

论文链接:https://arxiv.org/abs/2106.15941
近年来,Transformer模型在计算机视觉领域取得了很大的进展。视觉Transformer的快速发展主要得益于其从输入图像中提取信息特征的能力。然而,主流Transformer模型采用深层架构设计,随着深度的增加,特性多样性将不断减少,即特征崩溃(feature collapse)。
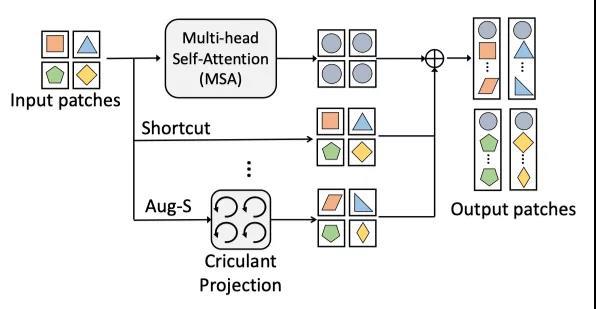
在本文中,作者从理论上分析了特征崩溃现象,并研究了这些Transformer模型中的shortcuts和特征多样性之间的关系。然后,作者提出了一个增强的shortcuts方案(如下图所示),该方案在原始shortcuts上并行插入具有可学习参数的附加路径。为了节省计算成本,作者进一步探索了一种有效的方法,使用块循环投影(block-circulant projection)来实现增强的shortcuts。作者在ImageNet数据集上使用ViT模型及其SOTA变体对增强shortcut的有效性进行了评估。结果表明,配备增强shortcut后,这些模型的性能可提高约1%,且计算成本相当。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢