
【标题】A Workflow for Offline Model-Free Robotic Reinforcement Learning
【作者团队】Aviral Kumar, Anikait Singh, Stephen Tian, Chelsea Finn, Sergey Levine
【发表日期】2021.9.23
【论文链接】https://arxiv.org/pdf/2109.10813v2.pdf
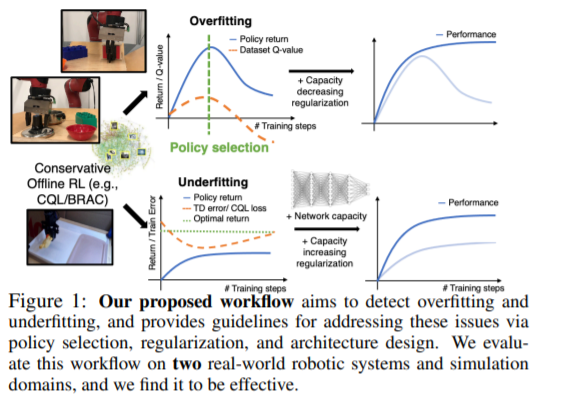
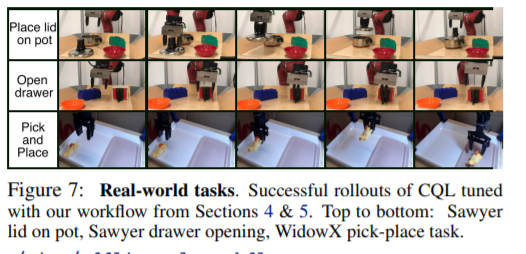
【推荐理由】离线强化学习(RL)仅利用先前的经验,无需任何在线交互,即可实现学习控制策略。这可以让机器人从庞大而多样化的数据集中获得通用技能,而无需任何昂贵或不安全的在线数据收集。虽然离线 RL 方法可以从先验数据中学习,但没有明确和易于理解的过程来做出各种设计选择,从模型架构到算法超参数,而无需实际在线评估学习到的策略。本文的目标是开发一个使用离线RL的实用工作流程,类似于相对容易理解的用于监督学习问题的工作流程。为此,其设计了一套可在离线训练过程中跟踪的指标和条件,并可告知实践者应如何调整算法和模型架构以提高最终性能。该工作流程来源于对保守离线RL算法行为的概念性理解和监督学习中的交叉验证。在几个模拟机器人学习场景和两个不同的真实机器人上的三个任务中展示了该工作流在无需任何在线调整的情况下产生有效策略的有效性,重点是使用稀疏二进制奖励的原始图像观察来学习操作技能,该方法可以告知从业者应该如何调整算法和模型架构以提高最终性能。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢