转自知乎:https://www.zhihu.com/question/490962362/answer/2183731284
看了几篇Contrastive Learning的工作,分析和观点百花齐放,很有意思。
Decoupled Contrastive Learning
Yann组的最新工作,一开始以为是简单的去掉了一项做了个加权,仔细阅读后发现不简单,竟然去掉了分母里Push Away View2后,就能解决对比学习Large Batch-Size的问题。
论文先通过分析了对比学习对各项的梯度,发现batch size影响最大的是一个NPC mulplier的估计,也就下面这一项,它会出现在几个梯度的分项中,过小的batch size会造成该项的distribution shift,从而影响训练,
怎么做呢?我们可以在Contrastive Loss中去掉分母中的第二个view就可以了。也就是说,不要push增广得样本即可:
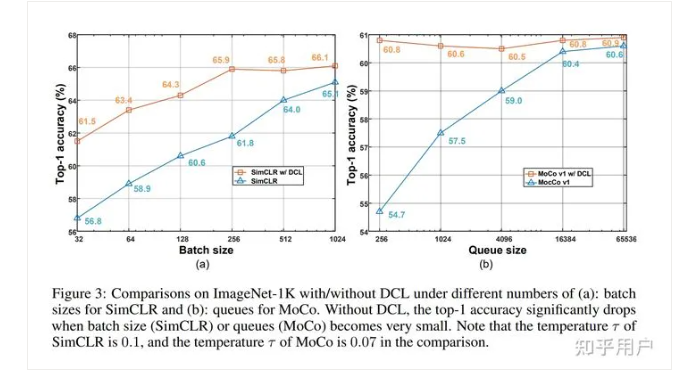
效果有点离谱,基本上比较小的batch-size也有非常大的提升:
Chaos is a Ladder: A New Understanding of Contrastive Learning
这是一篇做理论分析的工作,证明了在Alignment之外,我们还需要引入其他的约束。和这篇比较相关的两篇工作,分别是A theoretical analysis of contrastive unsupervised representation learning和Understanding contrastive representation learning through alignment and uniformity on the hypersphere。前者是证明对比学习情况下,mean classifier的泛化误差界与Intraclass deviation有关。后者则是将损失进行分解,证明了NCE loss的由alignment和uniformity两个性质构成。
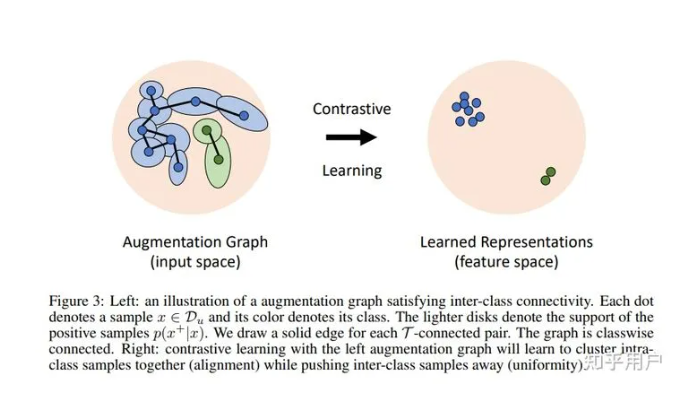
具体来说,这篇文章首先分析了alignment和uniformity是不充分的,因为如果我们学习到的表征把每个样本都分的很开,而且完全随机分布,这时候alignment和uniformity不能保证一个紧致的泛化误差上界。所以说,我们需要的是一种Expansion的性质(参考马腾宇组ICLR 2021证明Self-Training的工作),也就是通过augmentation以后,对于(A,A+)和(B,B+)两对样本,如果增广后A+和B+变成非常相似,由于我们进行alignment,这三个样本可能都会变成同一个,那就出现了类似连通图的感觉,所有的样本都能够出于同一个生成集,类似于Spanning tree。由此我们可以得到易于分类的结果。
从理论上,作者改进了Sajeev Arora的工作,给出的上界和class conditional variance息息相关。这篇文章和马腾宇组NIPS 2021的工作Provable guarantees for self-supervised deep learning with spectral contrastive loss也有比较强的联系,大家还可以延伸阅读一下。
Contrastive Label Disambiguation for Partial Label Learning
这篇论文把对比学习应用到了弱监督学习问题中,在这个PLL的问题里一个样本的标签是一个候选集合,而不是单个的Ground-truth标签。作者提出的方法同时训练了Classifier和对比学习,然后用Classifier挑选Positive Set,用对比学习的Emebeddings得到一个原型,对弱监督标签进行Disambiguation。近期有多篇对比学习和半监督学习、噪声标签学习的工作,这篇也是在一个新的问题上有很成功的应用。
这篇文章比较有意思的是把方法解释成了EM聚类的过程,推导中把对比学习的Alignment这一项解释成了Class Variance的最小化,这样一来,Alignment这一项可以看作是一个球面上进行von Mises-Fisher聚类的过程。
这里聚类的观点是比较有意思的,由于是弱监督学习的工作,所以这篇文章是从Supervised Contrastive Learning的损失出发的,可以证明此时Alignment性质优化的恰巧就是聚类or线性判别分析的目标函数。文章没有显式地在对比学习的目标里加prototype,却推到了和PCL一样的形式——尽管对比学习尝试最小化pairwise点对距离,但其实和直接优化聚类中心(或者说mean classifier)在数学上是等价的。
Contrastive Learning is Just Meta-Learning
这篇文章把对比学习解释成了meta-learning,因为每个instance可以看作不同的任务,而augmented images则是能够看作每个task关联的样本。在Meta-learning中,我们会提供每个任务的support set和query set,但是在对比学习中,我们的样本都是混合在一起的。这种情况更加接近于Prototypical Networks,这时元学习的观点依然十分接近。作者进行了多组实验,发现元学习的效果和SimCLR确实比较接近。基于此,作者提出了一个新的预测旋转损失的目标函数,引入更多的不变性(Invariance)。
MAML is a Noisy Contrastive Learner
这两篇文章实在是太有意思了,第一篇把对比学习解释成MAML,另一篇则把MAML解释成对比学习。作者推到了MAML的损失的梯度,发现展开以后可以看作某种version的对比学习损失,具体可以直接看论文。
其他论文(没细看or还没看):
-
f-Mutual Information Contrastive Learning
-
Self-Contrastive Learning
-
Incremental False Negative Detection for Contrastive Learning
-
Sharp Learning Bounds for Contrastive Unsupervised Representation Learning
-
Rethinking Temperature in Graph Contrastive Learning
-
Tackling Oversmoothing of GNNs with Contrastive Learning
-
m-mix: Generating hard negatives via multiple samples mixing for contrastive learning
-
Semantic-aware Representation Learning Via Probability Contrastive Loss
-
What Makes for Good Representations for Contrastive Learning
-
...太多了
其实很多篇文章都提到了intraclass covariance/deviation,以及mean classifier, prototypes等概念,本质上来说是殊途同归的,原因就是在于alignment这一项其实就是完成了类似线性判别分析的过程,不管有没有prototype,都会把样本往mean classifier上靠,数学上具有一定的等价性。内容中包含的图片若涉及版权问题,请及时与我们联系删除

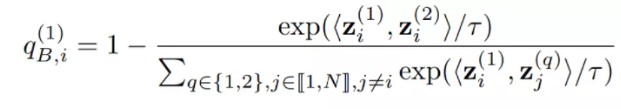
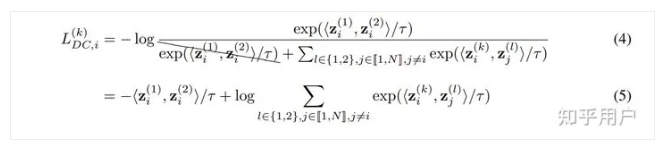
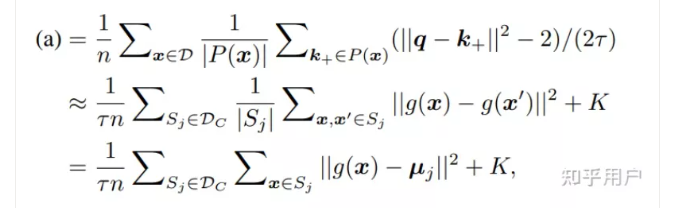

评论
沙发等你来抢