
在之前的介绍中,我们对自监督学习(SSL)中的对比学习(CL)进行了简单介绍,然后针对对比学习中的采样方式进行详细的分析。由于对比学习的核心思想是在向量表征空间中将正样本(positive example)与锚点样本(anchor example)之间的距离拉近,将负样本(negative example)与锚点样本(anchor example)之间的距离拉远,因此,所选取的正负样本的质量直接决定了整个方法的效果。为此,有很多研究工作集中在对比学习的采样方法中,本文针对这些方法继续进行深挖,希望能够让大家对对比学习有更深入的认识,为大家带来一些微小的启发。
-
通过分析指出原生的 BERT 模型在句子语义表征中存在“坍缩”现象,即倾向于编码到一个较小的空间区域内,使大多数的句子对都具有较高的相似度分数,影响表征结果在具体下游任务中的表现
-
基于 BERT 模型提出了一种更好的对比学习方法,用于句子语义的表征 -
在监督实验,无监督实验,小样本实验中进行了充分的模型验证
1.2 方法
整体的模型框架图如下,相对于 BERT 模型而言思路非常简单,就是在输入到 encoder 的时候加了一个数据增强层。但作者进行了非常全面的考虑,例如为了避免直接从文本层面进行数据增强导致的语义变化问题,以及效率问题。作者提出直接在 embedding 层隐式生成数据增强样本,从而一方面避免以上问题,另一方面能够生成高质量的数据增强样本。
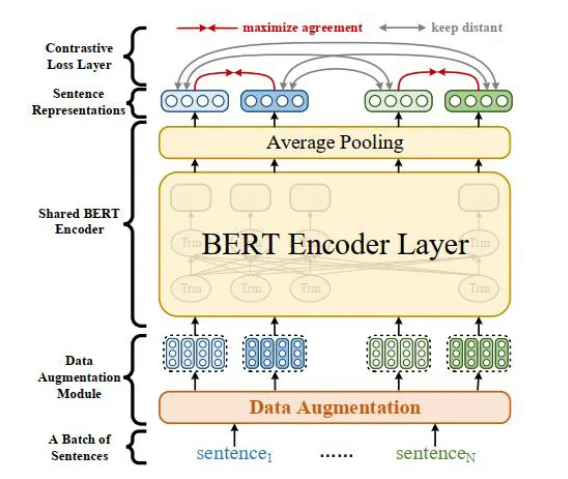
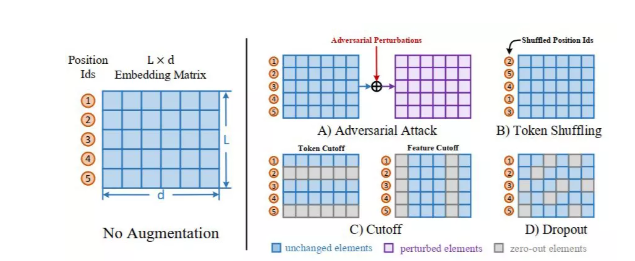
而在数据增强上,由于是在 embedding 层直接进行数据增强的,因此在这里作者选择了以下四种增强方式:
-
对抗攻击:通过梯度回传生成对抗扰动,将该扰动加到原本的 embedding 矩阵上
-
词序打乱:这个非常有意思,由于在 BERT 中是通过 position embedding 的方式显式指定位置的,因此直接将 position id 进行 shuffle 即可
-
裁剪:这部分分为两个粒度:a. 对某个 token 进行裁剪,直接将对应的 embedding 置为 0 即可,b. 对某些特征进行裁剪,即将 embedding 矩阵中对应列置为 0
-
dropout:这个就是非常简单有效的方法了,直接利用 BERT 的结构进行 dropout 操作即可
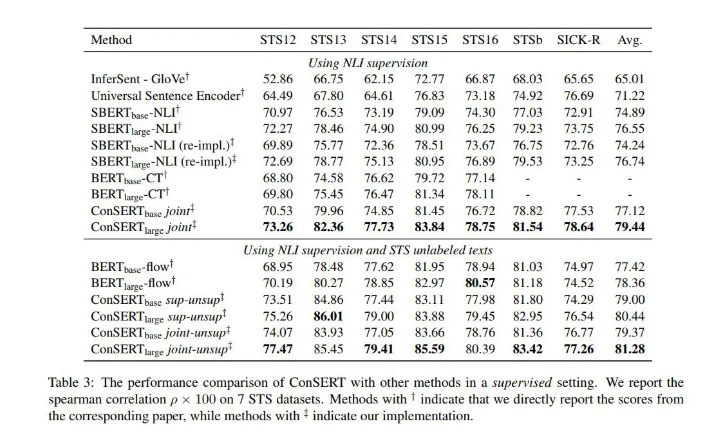
本文的实验也是非常充分的,作者处理利用对比学习框架进行无监督训练之外,还考虑了融合监督信号进行的增强训练,并提出了联合训练:有监督损失和无监督损失进行加权联合训练;现有监督在无监督:先用有监督损失训练模型,在利用无监督方法进行表示迁移;联合训练再无监督:先用联合损失训练模型,在无监督迁移。
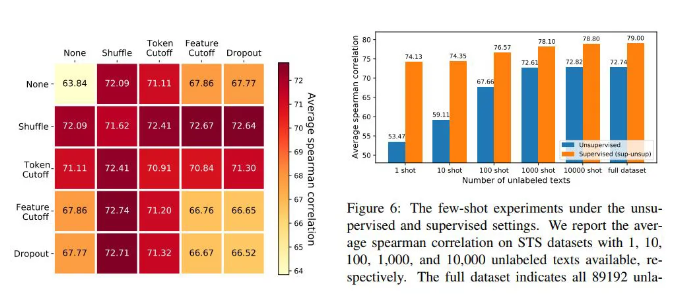
个人认为本文最大的亮点就是对数据增强方法的利用,相对于 CV 领域的增强方法,NLP 领域的数据增强一直存在高质量的数据增强与原始语义的保证之间的矛盾。
本文通过直接在 embedding 矩阵上进行处理,一方面能够缓解以上矛盾,另一方面能够以一种更高效的方法进行,从而实现了 NLP 中更好的对比学习。这部分还可以参考 Mixup 这个工作,能够为这种方法提供更好的数据增强操作。
在传统对比学习中,我们主要是通过以下方式进行对比,输入样本为锚点样本,数据增强样本为正样本,同一个 batch 中的其他样本默认为负样本。这种方法的好处是能够简单实现 1 个正样本 v.s. 多个负样本的学习,但问题也同样存在,这种方法本质上是一种实例级别的对比学习(Contrastive instance discrimination,或者 Instance-level contrastive learning),即每个样本都单独的一类。
2.1 亮点
-
作者通过实验证明现有的对比学习方法效率低的原因有两个,under-clustering 和 over-clustering,前者是说在负样本数量不充足的时候很难学习到类别之间的不相似性;后者是说在实例级别的对比学习很难实现同一类样本的类内特征学习。 -
为了解决这种问题,作者提出了一种新的损失函数,将 infoNCE 替换为 triplet loss,以实现更多的负样本学习以及类内公共特征学习
2.2 方法
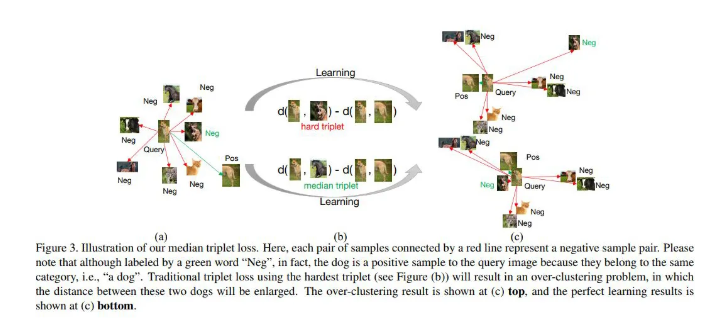
最主要的,作者提出了一种 Median Triplet Loss,在 triplet loss 的基础上进行了修正,以提升对比学习的效率和性能。以下是 median triplet loss 的一个直观图示:
首先普通的 triplet loss 可以表示为如下形式:
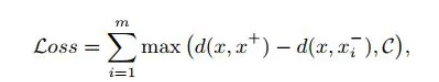
而为了提升 triplet loss 的效果,在实际应用中,一般会借鉴 SVM 的思想,直接选择最难的样本作为负样本进行损失计算,也即可以用如下形式表示:
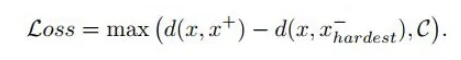
也就是说将 InfoNCE 损失替换为 triplet loss,并使用最难的样本进行计算的话,就可以解决 under-clustering 问题,因为最难的负样本都已经满足这个条件了,那其他所有的负样本也都会满足这个条件。
但这又会引出另一个问题,over-clustering 问题并没有得到解决,因为最难的样本是和锚点样本具有最大的语义相似度(负样本中),那么就有可能是假负样本,而这个假负样本性又是因为现在做的是实例级别的对比造成的。为了解决这个问题,作者想出来一个非常简单的方法,相对于对最难的样本做一个退化。
具体而言,既然最难的样本会造成 over-clustering 问题,但又想尽可能大的是使用决策边界,那是否可以降低一下难度呢?作者没有去解决假负样本的问题,而是说通过计算所有的负样本的难度,然后进行排序,选择中间的作为 triplet loss 的计算目标,这样一方面尽可能提升了负样本的难度(增大决策边界),另一方面缓解了 over-clustering 问题,因为使用的不是最难的负样本,这样,损失函数就变成了如下形式:
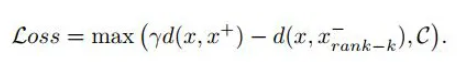
同样的,该方法也是一种通用的对比学习方法,为了验证其效果,作者在多个对比学习框架上进行了效果的验证,同时还对模型的效率进行了对比实验,从而验证模型提出的方法的有效性。部分实验结果如下图所示:
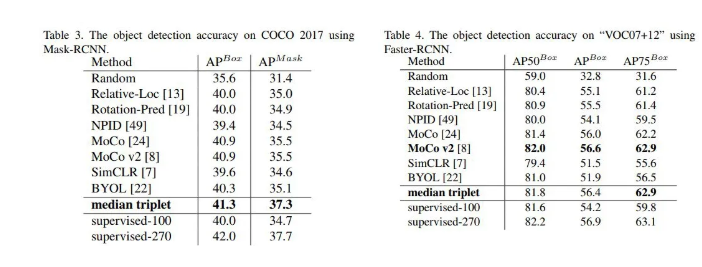
-
作者通过实验分析证明假负样本对整个对比学习的影响还是很大的,尤其是在大规模数据集上(数据量大,标签数量多) -
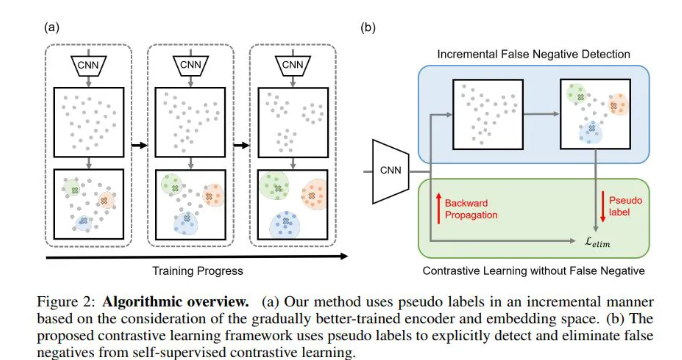
本文提出了一种增量式的假负样本检测方法,按照置信度从高到低逐步移出假负样本,缓解假负样本对整个对比学习模型的影响。
3.2 方法
下图是整个模型的算法框架图,作者通过以一种增量学习的方式识别负样本采样中的假负样本,首先删除简单的假负样本,然后随着模型性能的提升,逐步删除难的假负样本,从而实现模型效果的提升
首先回顾一下传统对比学习的损失函数:
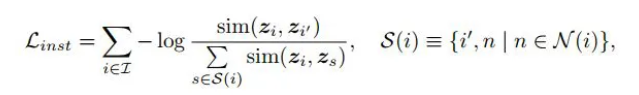
其中最主要的就是如何得到正确的正样本和负样本。在这里,作者主要关注于假负样本的检测。之前的方法,例如 DeepCluster,PCL 等大多是通过一次性的聚类得到伪标签,而这种方式是有些粗糙的。因为在刚开始的时候模型的建模能力是比较弱的,得到的输入表征的可信度也没有那么高。如果将这点考虑进来,就能够实现更好的假负样本检测。
为此,作者认为样本的标签应该满足一下条件:将样本赋予某一类别应该满足对应的表征不仅与对应的类别中心点近,而且应该和其他类别的中心点远。为此,作者提出了如下的置信度计算方法用于确定输入数据的伪标签:
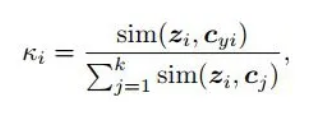
利用该计算公式,就能够为每一个负样本的伪标签添加上置信度,这样就可以设定接受阈值,当大于阈值时才会认为是真负样本,而且该置信度是利用学习到的表征进行计算的,因此它是和模型的性能直接相关的。因此能够动态的进行选择。
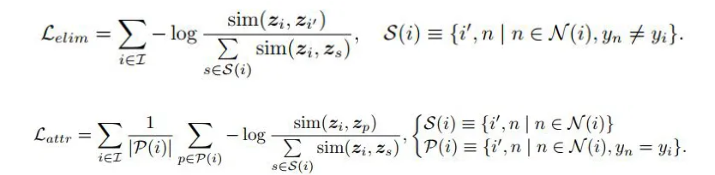
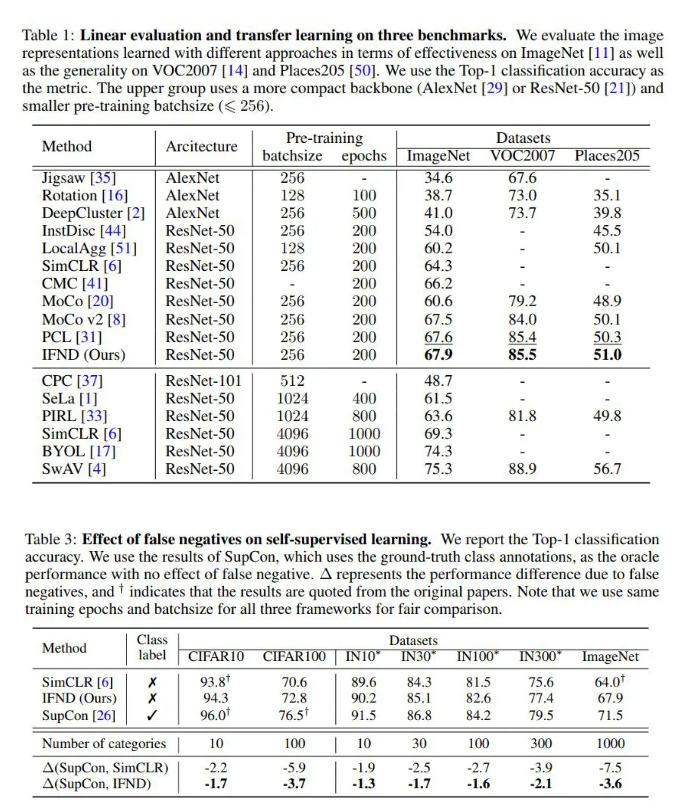
由于作者提出的方法是一种通用的采样和对比学习方法, 作者在多个方法上进行了模型效果的验证,同时还验证了假负样本对整个模型的影响,相关实验结果如下:
除此之外,作者还进行了不同删除策略的效果对比,进一步说明作者所提出的方法的有效性。
负样本质量分析(are all negative equal)[4]
4.2 方法
由于这是一个定量分析的工作,本文作者并没有提出具体的方法,而是直接以 Moco v2 为基准模型,然后分析在不同难度的条件下模型的表现,最后总结出相关的结论。
作者首先定义了负样本难度的计算方式:锚点样本和负样本在隐式对比空间中的表征向量的点积。在此基础上,作者对负样本进行排序,然后在相同条件下进行 Moco v2 的训练。并通过删除模型中特定难度范围的样本来分析这些样本对整个模型性能的影响。最后作者发现了一些有意思的结论。首先,作者将整个结果总结成了一个图:
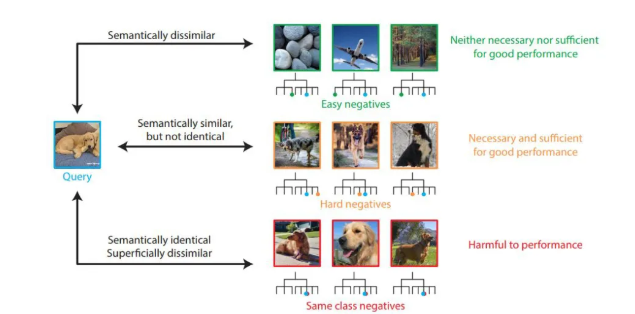
从图中可以得到以下结论:
-
最简单的 95% 的负样本是不必须的,对整个模型的影响非常小。最难的5%的负样本对整个模型的影响是巨大的,因此这些样本是必须的,而且这样的负样本数量也是足够的。仅在这些样本上进行训练就能够提升非常高。
-
最难的 0.1% 的负样本是不必要的,有时候甚至会对模型造成损害 -
通过对负样本的分析,难的负样本在类别上和锚点样本之间更相似(和简单样本相比),因此,在抽象语义上拥有更多的相似度对模型的影响更大一些。
作者还展示了一些具体的实验结果,如下图:
本文对对比学习中的采样策略进行了进一步的介绍,不再是如何选择更难的样本。而是考虑更全面的内容,如何解决 NLP 中的增强数据质量问题,如何提升对比学习的效率,如何在合适的时机选择恰当难度的样本提升对比学习的性能以及针对样本难度对模型性能整体定量分析。
参考文献
[1] Yan Y, Li R, Wang S, et al. ConSERT: A Contrastive Framework for Self-Supervised Sentence Representation Transfer[J]. arXiv preprint arXiv:2105.11741, 2021.
[2] Wang G, Wang K, Wang G, et al. Towards Solving Inefficiency of Self-supervised Representation Learning[J]. arXiv preprint arXiv:2104.08760, 2021.
[3] Chen T S, Hung W C, Tseng H Y, et al. Incremental False Negative Detection for Contrastive Learning[J]. arXiv preprint arXiv:2106.03719, 2021..
[4] Cai T T, Frankle J, Schwab D J, et al. Are all negatives created equal in contrastive instance discrimination?[J]. arXiv preprint arXiv:2010.06682, 2020.
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢