
Domain adaptation(DA: 域自适应),Domain generalization(DG: 域泛化)一直以来都是各大顶会的热门研究方向。DA 假设我们有有一个带标签的训练集(源域),这时候我们想让模型在另一个数据集上同样表现很好(目标域),利用目标域的无标签数据,提升模型在域间的适应能力是 DA 所强调的。

论文标题:
CrossNorm and SelfNorm for Generalization under Distribution Shifts
论文链接:
https://arxiv.org/abs/2102.02811
代码链接:
https://github.com/amazon-research/crossnorm-selfnorm
文章的两个方法分别对应两个目标:


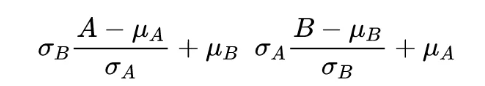
更详细的说,对于单个样本,作者可以交换他每个 channel 之间的均值和方差,对多个样本作者可以交换 instance level 的均值和方差。
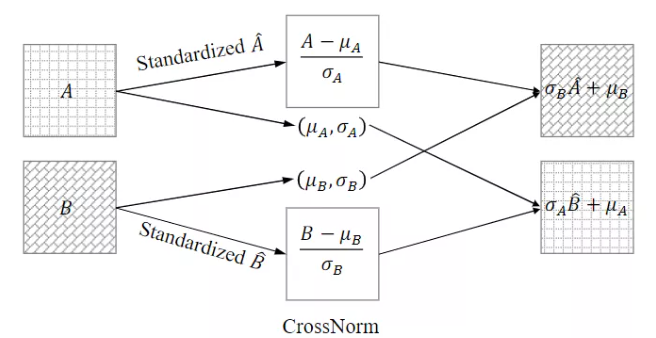
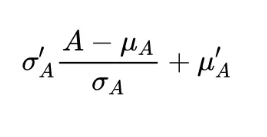
在实验过程中,一个重要的问题是在哪里?以及放置多少 crossnorm 或者 selfnorm 层。这个问题本身是非常难搜索的,因为每个位置都可以放。为了简化问题,作者转向模块化设计,将它们嵌入到一个网络单元中。比如在 resnet 中,作者将它放在 residual module 里。
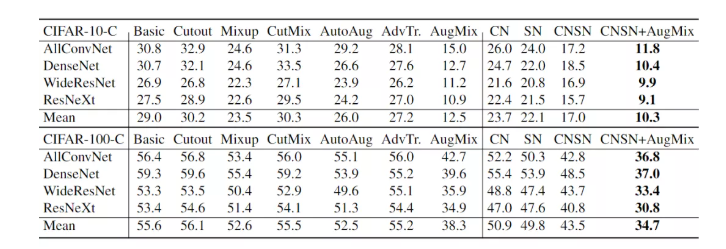
CN+SN 的方法在绝大多数 backbone上的效果好于现有的数据增强的方法,而且 CNSN 和他们是正交的,CNSN 不依赖于任何形式的图像操作,将 CNSN 与 augmix 结合之后效果来到了目前的 SOTA。文中还有更多数据集以及 numerical 的实验,这里不再赘述。
我们来看看文章的可视化结果。随着 CN 在网络中的深入,风格的变化变得更加局部和微妙。

对于 SN 而言,随着 SN 的深入,重新校准效应变得微妙,因为高级特征的统计数据并不直接与低级视觉线索联系在一起。


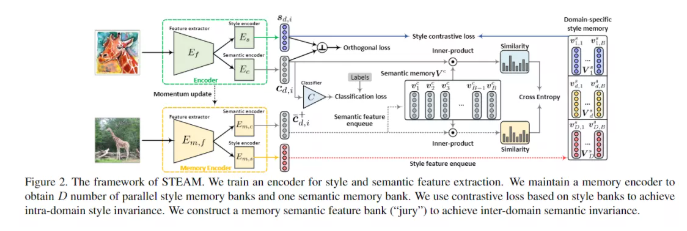
2、STEAM

论文标题:
A Style and Semantic Memory Mechanism for Domain Generalization
论文链接:
https://openaccess.thecvf.com/content/ICCV2021/papers/Chen_A_Style_and_Semantic_Memory_Mechanism_for_Domain_Generalization_ICCV_2021_paper.pdf
2.1 Motivation and Insights
2.2 Methodology
文章的框架很复杂,虽然 intuition 是好的,但是设计着实不敢恭维,很难 follow,因此这里简单讲一下思路。首先每个 image 提特征,然后分两个 encoder (style 和 semantic)分别提取风格信息和语义信息。
1. 语义信息提取出来后自然要做一个分类,除此之外文章设计上的一个亮点(看着实在过于复杂)的 memory bank,依靠当前语义信息和 memory bank 中的语义信息计算一个相似度。
2. 重点在于风格信息的处理。首先和语义分类计算一个正交的 loss,然后每个 domain 维护一个 memory bank,分别对每个 domain 的风格相似度计算一个 contrastive loss 来保证同一 domain 风格信息接近。
如下表所示,本文的方法明显优于现有的先进方法。而且该模型在比较有挑战的 DGsetting上(例如 MNIST-MandSVHN)尤其有效,因为与其他方向相比,它们似乎有很大的领域变化。
3、A2Net

论文标题:
Adaptive Adversarial Network for Source-free Domain Adaptation
论文链接:
https://openaccess.thecvf.com/content/ICCV2021/papers/Xia_Adaptive_Adversarial_Network_for_Source-Free_Domain_Adaptation_ICCV_2021_paper.pdf
3.1 Motivation and Insights
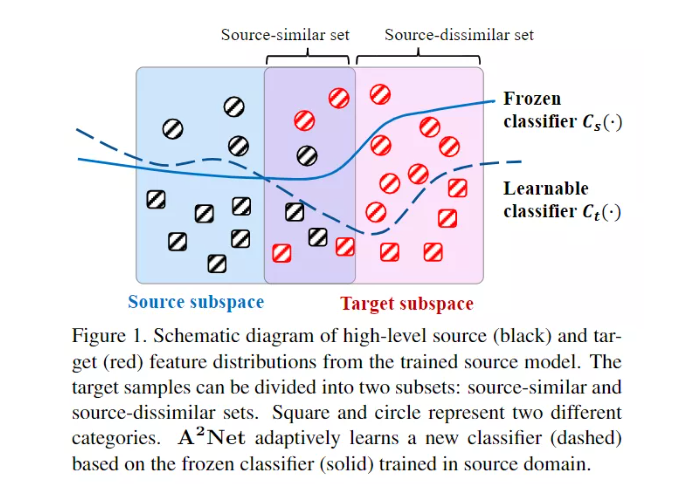
本文关注 source free domain adaptation:即训练过程中我们拿不到源数据,只能拿到在源域训练好的模型。本文的 intuition 在于,如果源数据本身极度不平衡或者存在偏差,那么分类器本身就不太合理。由于受到冻结分类器的限制,这个时候他很难在距离 source distribution 远的分布上表现的好。从另一个角度,本文提出了一个问题:在模型优化过程中,我们能否寻找一种新的针对目标的分类器,并使其适应目标特征?
本文核心的贡献之一在多 classifier 的设计,即保留原有的 source classifier,重新训练一个 target classifier,这样既可以利用目标域数据提升鉴别性,又保留了源域训练得到的宝贵经验,那么如何同时训练这多个分类器就是首当其冲的问题。
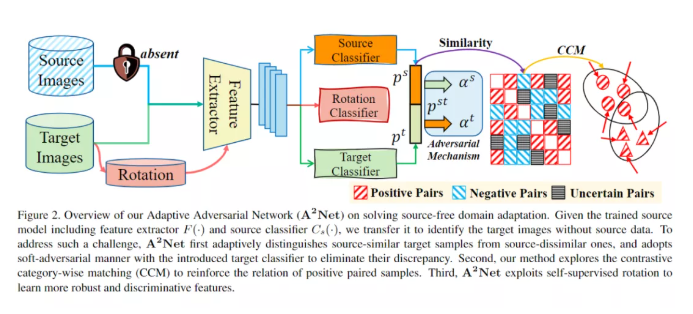
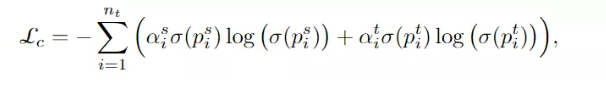
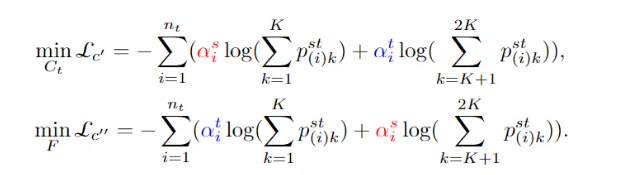
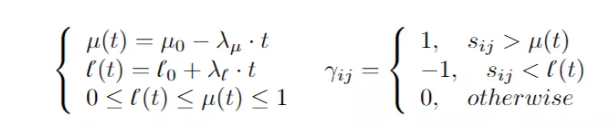
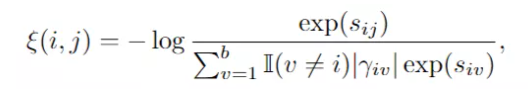
到目前为止,本文主要考虑如何在训练有素的源模型的指导下将知识转移到目标领域。然而,纯分类模型严重依赖于给定的源数据,往往分布不均衡,进一步限制了目标分类器的泛化能力。为了解决这一问题,作者探索了目标域上的自监督旋转方式,以增强样本空间,增强了特征提取和目标分类器的学习。
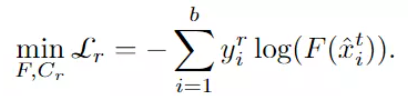

论文标题:
Gradient Distribution Alignment Certificates Better Adversarial Domain Adaptation
论文链接:
https://openaccess.thecvf.com/content/ICCV2021/papers/Gao_Gradient_Distribution_Alignment_Certificates_Better_Adversarial_Domain_Adaptation_ICCV_2021_paper.pdf
代码链接:
https://github.com/gzqhappy/FGDA
4.1 Motivation and Insights
传统的方法大多是基于对抗学习来减小域之间的 discrepancy,但是对抗学习所采用的 MIN-MAX game 并没有一个很好的纳什均衡的保证,即使域分类器完全无法鉴别两个 domain,他们的分布也不一定对齐了。
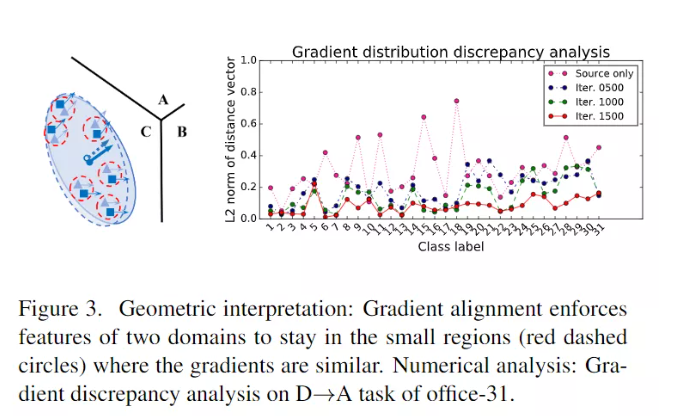
本文提出了 FGDA 方法,如下图所示,该算法通过特征提取器和鉴别器之间的对抗学习来减小特征梯度在两个域之间的分布差异。当达到平衡时,特征分布差异的值是最小的。
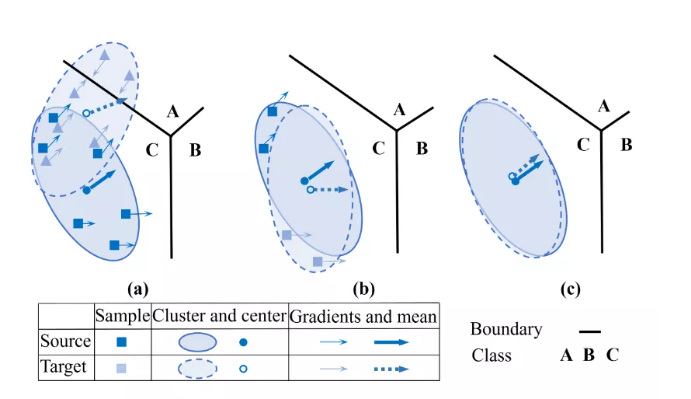
从对抗学习的角度来看,样本的输入梯度可以看作是对输入扰动最小、对模型输出影响最大的敏感方向。直观上,一个样本的特征梯度方向可能倾向于指向其最近决策边界的区域。因此,对齐特征梯度有助于学习潜在表示,从而迫使两个域分布保持更近的距离。这样可以减小特征分布的差异。文章还有一部分理论,验证了 FGDA 可以进一步得到更小的 upper bound。

4.2.1 Feature Gradient Distribution Alignment
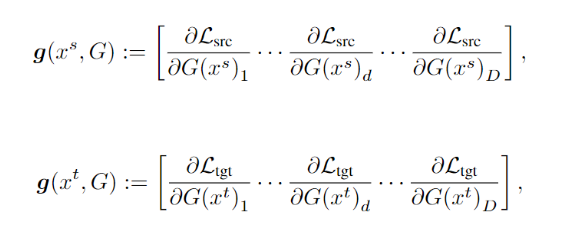
文中依然是使用了对抗学习来,具体来说,鉴别器预测源域和目标域特征梯度的域标签,而特征提取器学习混淆鉴别器。当达到均衡时,特征分布差异达到最小值。
本文也采取了梯度正则化的手段来提升模型的分类能力,具体而言,本文在特征层面采用雅可比矩阵正则化,使得特征提取器可以学习到更多远离决策边界的具有鉴别性的特征,同时分类器可以扩大分类 margin。其中输入输出的雅可比矩阵定义为:
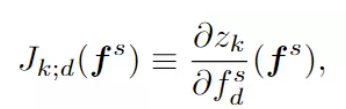
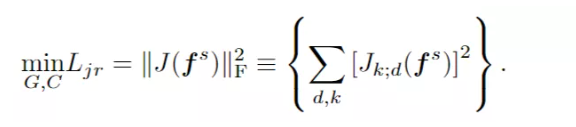
每个类的特征分布质心也被认为是一个原型表示(来了,又融合了 prototype learning),它的分布应该出现在分类器能够自信预测大量样本的区域。质心的更新类似于 k-means 聚类,通过用分类器的置信度加权每个目标特征:
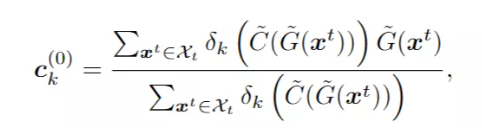
每个目标样本的离线伪标签用最接近质心的标签进行分配:
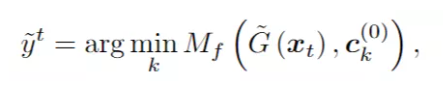
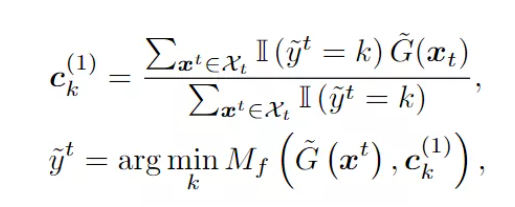
我们想从实验中得到的无非两点:模型是否有效以及梯度对齐为什么有效,作者回答了这两个问题。
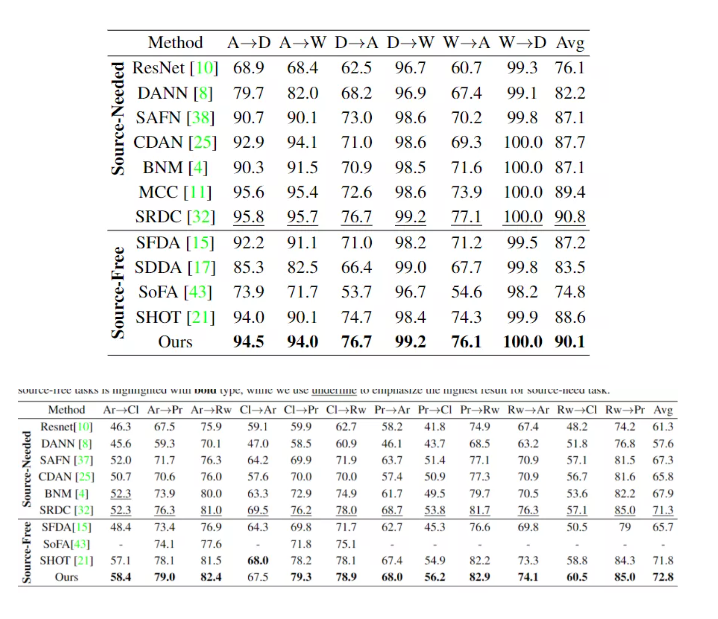
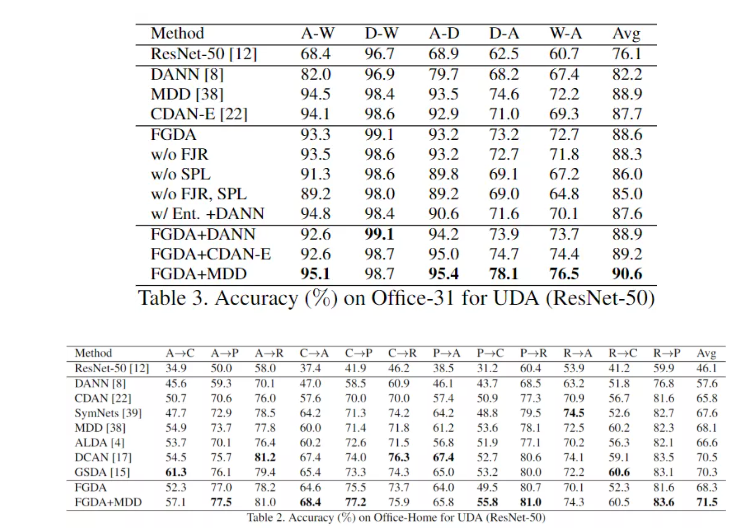
首先 FGDA 与传统减少 domain discrepancy 的方法结合摸到了 sota。虽然 FGDA 单独拿出来效果并没有想象的那么理想,但是 FGDA 毕竟是和现有方法正交的。
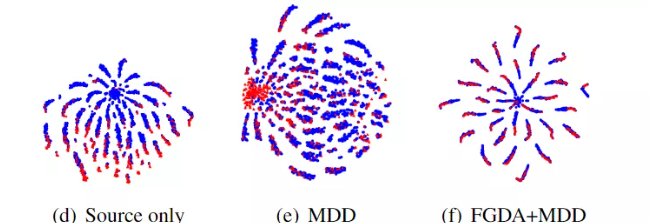
从 t-sne 的结果来看,加了 FGDA 之后特征对齐确实更好的对齐了。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢