
本文分享 NeurIPS 2021 论文『Attention Bottlenecks for Multimodal Fusion』,思考《MBT》多模态数据怎么融合?谷歌提出基于注意力瓶颈的方法,简单高效还省计算量。

论文链接:
https://arxiv.org/abs/2107.00135
在本文中,作者提出了一种视听融合的Transformer结构(MBT),并利用token间的交叉注意探索了多种不同的融合策略。为了提高计算效率,作者提出了一种新的融合策略,可以通过一小部分融合 “瓶颈” 来限制跨模态注意力,并证明这可以以较低的计算成本提高交叉注意力的性能,并在多个基准数据集上实现SOTA的结果。
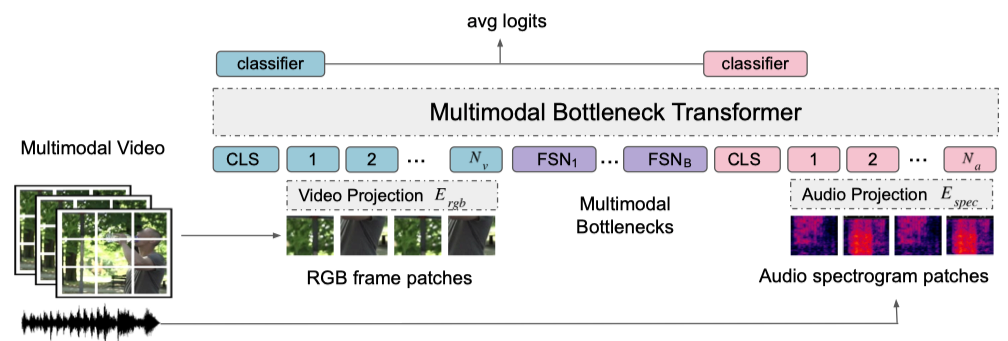
作者提出了一个Multimodal Bottleneck Transformer (MBT)结构来融合多模态数据。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢