
【论文标题】MutFormer: A context-dependent transformer-based model to predict pathogenic missense mutations
【作者团队】Theodore Jiang, Li Fang, Kai Wang
【发表时间】2021/10/27
【机 构】宾州儿童医院、宾大
【论文链接】https://doi.org/10.1101/2021.10.25.465689
【代码链接】https://github.com/CaiLiLab/MuRaL
错义突变是一种点突变,导致蛋白质序列中的一个氨基酸被替换。目前,错义突变约占导致人类遗传性疾病的已知突变体的一半,但准确预测错义变体的致病性仍然是一个挑战。深度学习的最新进展表明,Transformer模型在序列建模方面特别强大。在这项研究中,本文介绍了MutFormer,一个用于预测致病性错义变异的基于BERT的模型。本文对MutFormer进行了蛋白序列和由常见遗传变异导致的替代蛋白序列的预训练,MutFormer可以直接分析蛋白质序列,不需要任何同源信息或额外数据。本文测试了不同的微调方法来预测致病性,MutFormer能够在SNPs的致病性预测方面与目前的方法相匹配或优于其表现。
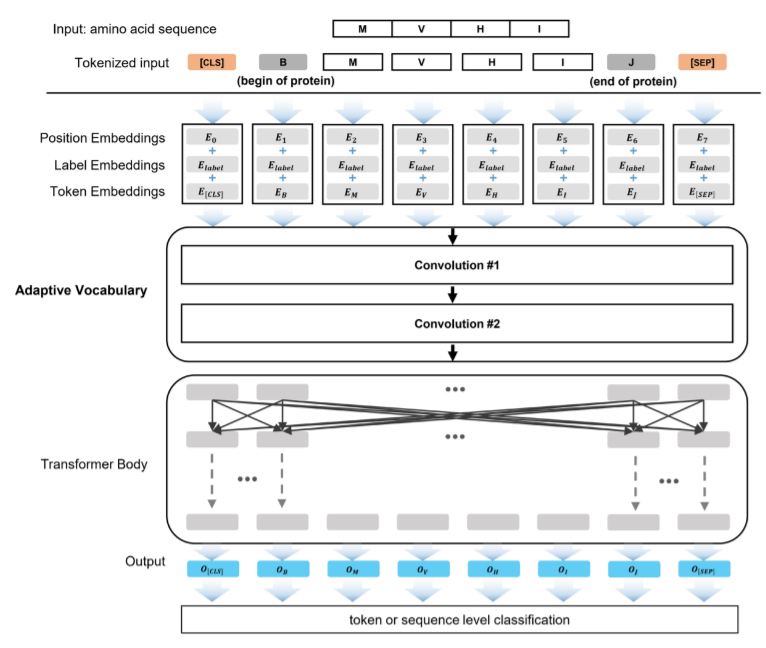
上图展示了Mutformer的架构,首先,一个由position、labe和token嵌入组成的系统被用来对输入标记进行矢量化;接下来,两个卷积层学习适应性词汇;之后,一个具有自注意力的双向Transformer体考虑了上下文并学习了蛋白质序列的模式,输出嵌入被用于标记或序列级分类。

上图展示了本文中的不同微调方法。
A)每个残基分类。输入是一个可能包含突变体的蛋白质序列。每个残基都有一个良性/病理性的标签,良性变体和与参考序列相同的残基被标记为良性。微调的任务是预测每个氨基酸的标签。这与NLP中的标记分类问题(如命名实体识别)相似。
B) 单一序列分类。输入是一个可能含有致病变体的蛋白质序列。最后一层的[CLS]标记的嵌入被用来预测该序列是否包含致病变体。这与NLP中的句子分类问题(如情感分析)类似。
C) 序列对分类。输入是一对两个序列:一个参考蛋白序列和一个变异的蛋白序列(中间有一个良性或致病的变体)。最后一层中[CLS]标记的嵌入被用来预测突变的序列是否包含致病变体。这与NLP中的句子对分类问题(如句子相似性)类似。
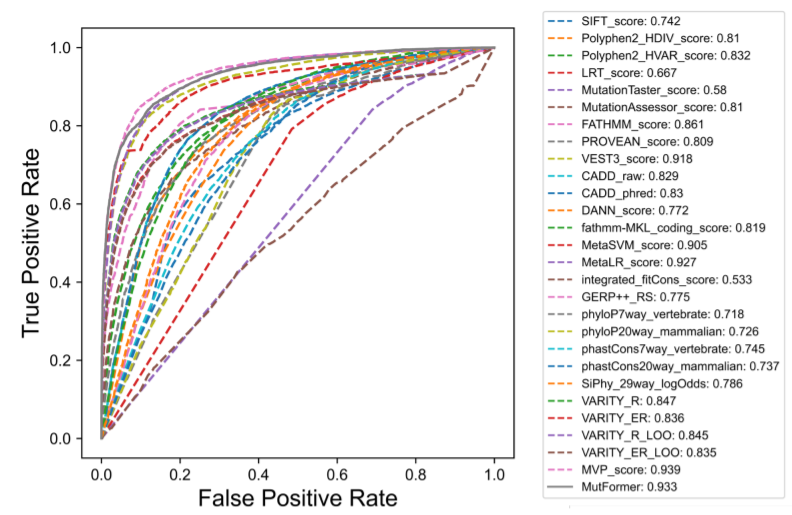
上图显示了MutFormer与现有方法的ROC曲线性能比较。
由于成对的序列分类表现最好,本文专注于这种微调方法并测试了不同的超参数。MutFormer在测试集上的最佳AUC得分是0.933,这是通过对MutFormer12L(最优模型)进行微调,使用批次大小为32,最大输入序列长度为256实现的。使用相同的测试集,本文将本文的模型与现有的各种方法进行比较,包括一些最新的研究,如MVP和VARITY。本文将每种方法的得分归一化为0和1之间的范围,并绘制ROC曲线。如果一种方法没有提供分数,本文就认为对一个突变的预测是错误的。MutFormer优于多种广泛使用的方法,包括SIFT、PolyPhen、MutationTaster、FATHMM、CADD以及本文以前的方法MetaSVM和MetaLR。MVP是唯一取得比MutFormer更高的AUC的方法。
不过,MVP使用了多种手工制作的特征(如GC含量、保存分数、基因突变不耐受分数),并纳入了以前11种方法的致病性分数。MutFormer却只将一对蛋白质序列(参考序列和突变序列)作为唯一输入。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢