最近,来自 Google Research 的一篇新论文表明,目前对海量数据集进行管理的趋势可能会对开发有效的人工智能系统产生反作用。
事实上,研究表明,更好的机器学习产品可能来自于在不太准确(即技术上“更差”)的数据集上进行训练。
如果这一结论正确,则意味着“超大规模”数据集,例如最近发布的 LAION-400M(包含 4 亿个文本/图像对),以及神经语言引擎 GPT-3 背后的数据(包含 1750 亿个参数),在传统和流行的机器学习架构和方法中可能会受到某种“热限制”的影响,庞大的数据量让下游应用程序饱和,并阻止它们以有用的方式泛化。
深入研究导致这些现象的原因,团队发现,他们观察到的饱和行为与表示在模型层中演变的方式密切相关。研究人员还展示了一个更极端的场景,其中上游和下游的性能相互矛盾。也就是说,为了获得更好的下游性能,需要损害上游的准确性。
研究人员还提出了重新思考超大规模数据集架构的替代方法,以纠正这种不平衡。
该研究的标题是 Exploring the Limits of Large Scale Pre-training,来自 Google Research 的四位作者(“数据实战派”后台回复“limits”获取论文链接)。
论文作者对“在超大规模数据时代机器学习>数据关系”这一普遍假设提出挑战:缩小模型和数据量大小可以显著提高性能(自 GPT-3 推出后,这一信念得到了巩固),并且这种改进的性能以线性(即理想的)方式“传递”到下游任务,以便形成最终推向市场的设备端算法。该见解源自于无法控制的庞大数据集和未经提炼的训练模型,完全受益于全尺寸上游架构这一理念。
研究人员指出以往的观点表明花费算力和研究工作来提高一个庞大语料库的性能是值得的,因为这将使我们能够几乎免费的解决许多下游任务。
但论文作者认为,缺乏计算资源和“经济”的模型评估方法会导致对数据量与有效的 AI 系统之间的动态关系产生错误印象。作者认为这种习惯是一个致命弱点,因为研究界通常假设当下(积极)的结果将转化为有用的后续实施。
论文指出:“由于计算资源的限制,无法展示不同超参数值选择的性能。如果为每个尺度选择的超参数是固定的或由简单的缩放函数确定,则尺度缩放似乎更有利。”
研究人员进一步指出,许多规模化研究不是根据绝对规模来衡量的,而是根据对最先进技术(SotA)的增量改进来衡量的。同时观察到:先验地将缩放比例保持在研究范围之外,这一说法是没有根据的。
该论文讨论了“预训练”的实践,它是一种旨在节省计算资源和减少从零开始训练大规模数据模型所需的冗长时间尺度的措施。预训练简要说明了一个域内的数据通过训练变得泛化的方式所需要的“原型”,并且通常应用于各种机器学习领域和专业,比如从自然语言处理(NLP)到 DeepFakes(AI 换脸工具)。
早期的学术研究发现,预训练可以显著提高模型的鲁棒性和准确性,但最新的论文表明,即使在训练时间相对较短的预训练模型中,如果将特征的复杂性分流到各通道的后续流程中,可能会带来更多好处。
然而,如果研究人员继续依赖使用当前学习率得到的最佳实践的预训练模型,上述现象将不会发生。研究结论表明,这会显著影响最终应用的准确性。在这方面,作者指出,人们不能指望找到一个在所有可能的下游任务上都表现良好的预训练模型。
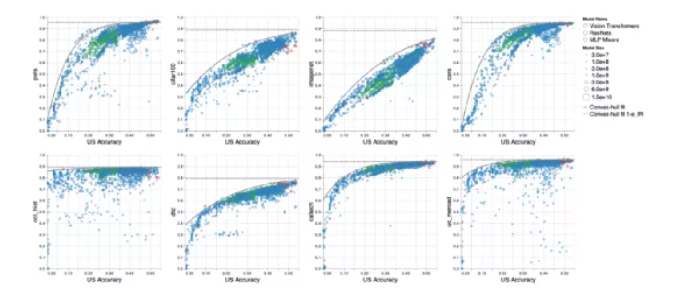
论文通过系统的研究指出,随着上游任务准确性的提高,下游任务性能会趋于饱和。为了研究饱和效应,作者在 Vision Transformers、ResNets 和 MLP-Mixers 上进行了 4800 次实验,每个实验都有不同数量的参数,从 1000 万到 100 亿不等,所有这些都在各自领域可用的最大容量数据集上进行了预训练,包括 ImageNet21K 和 Google 的 JFT-300M,并在各种下游数据集上进行评估。
论文研究了尺寸缩放在图像识别任务中的小样本和迁移学习性能中的作用,并提供了强有力的经验证据证明:缩放(和超参数调整)不会导致一个模型适合所有的解决方案。这其中仍然存在许多未解决的挑战,最核心是下游任务的数据多样性问题。论文对这种现象进行了首次大规模和系统的调查,并讨论起其背后的原因。如图 1 所示,展示各种模型和下游任务中上游性能和下游性能的对比。从图 1 可以观察到,在大多数情况下,随着上游准确度的提升,下游准确度趋于饱和远低于 100% 的值。这种饱和行为是普遍趋势,而不是个别情况。此外给定一组具有相似精度的上游模型,不同的下游任务对应的最佳模型不同。
结果表明,在尝试“扩大”数据、模型参数和计算时间时,应将数据多样性作为附加项考虑。就目前而言,随着大量参数达到“饱和”点,人工智能上游部分的训练资源(和研究人员的注意力)的高度集中正在严重冲击下游应用程序,通过特征和执行推理或效果转换降低了已部署算法的导航能力。
该论文得出结论:通过广泛的研究可以确定,当通过扩大超参数和架构选择来提高上游任务的性能时,下游任务的性能表现出饱和行为。此外,论文提供了强有力的经验证据,表明与常见的叙述相反,缩放不会导致一个模型适合所有的解决方案。论文展示了超参数的作用,并强调不能指望找到一个在所有可能的下游任务上都表现良好的预训练检查点。应该避免只关注一项下游任务,反之应该做出设计选择,进而提高下游任务的性能。
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢