
典型的实时流式自动语音识别业务如语音搜索、语音输入等和用户操作相关,直接影响用户体验,最重要的性能指标是延迟,其次是并发路数。TDNN+LSTM 作为一种主流的实时流式声学模型,可以实现低延迟、高并发。本文介绍了快手异构计算与 MMU 音频中心合作的针对 TDNN+LSTM 声学模型的全定点推理硬件加速方案。该方案基于 FPGA,在流式 ASR 服务场景下, 高峰期平均延时减小 37.67 %,并发路数提升 7.5 倍,是 FPGA 在国内大规模数据中心语音场景落地的成功案例之一。
快手异构组选择了全定点推理的 FPGA 定制化方案,考虑业务场景、成本约束和算力限制,为达到最佳效果,在各个环节、各个层面针对性的解决问题和提出创新,如下表所示。
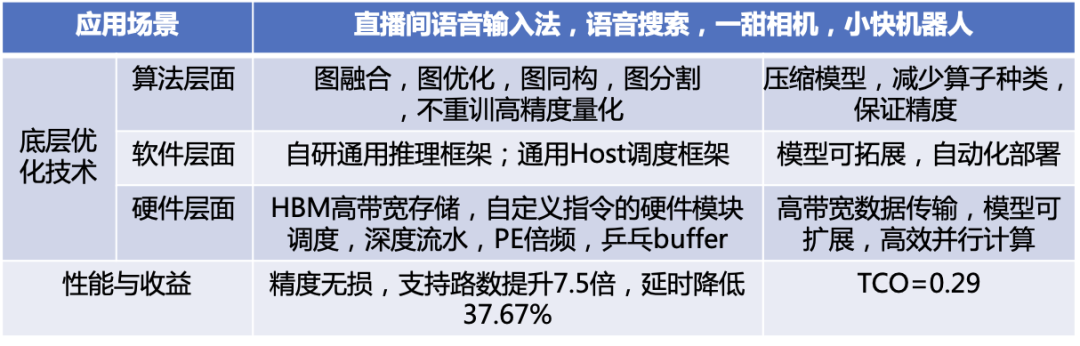
硬件加速方案技术创新
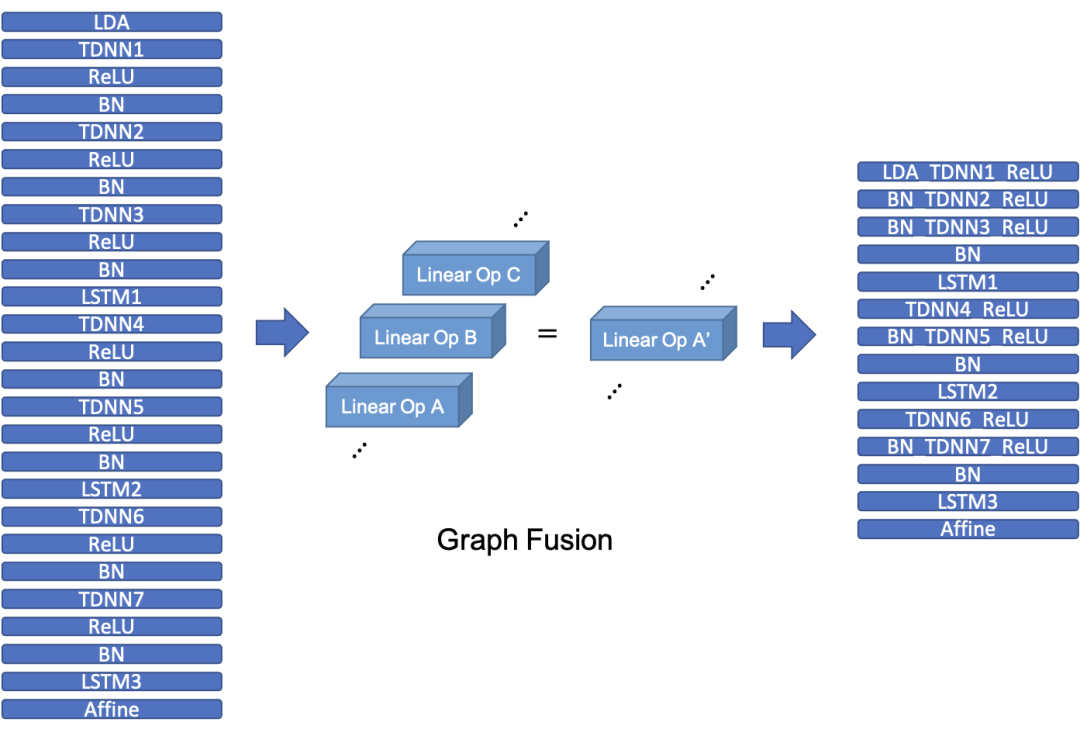
图融合和图优化后的声学模型减少了约 20% 的层数
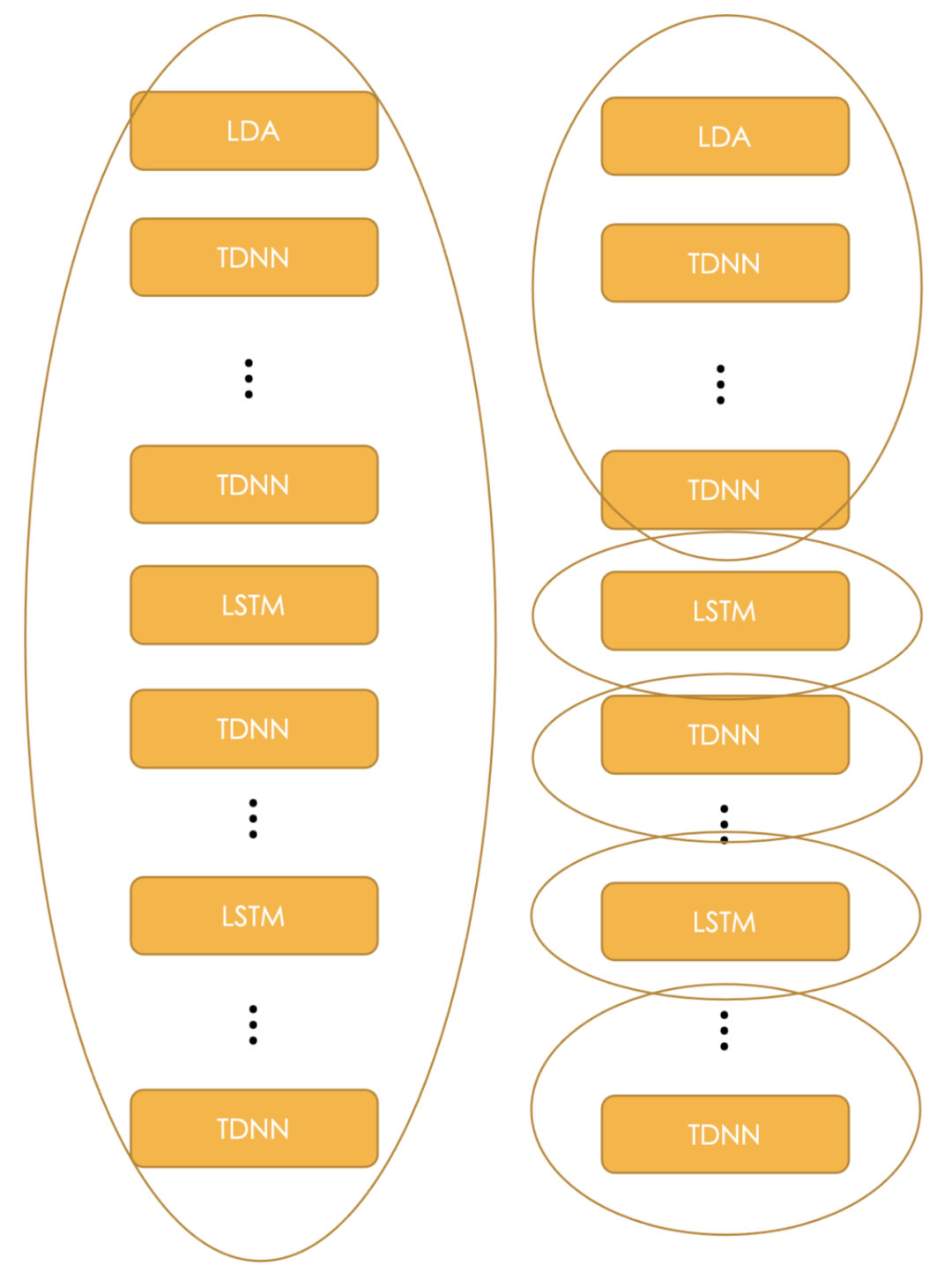
针对 TDNN+LSTM 模型的图分割(Graph partitioning)示意
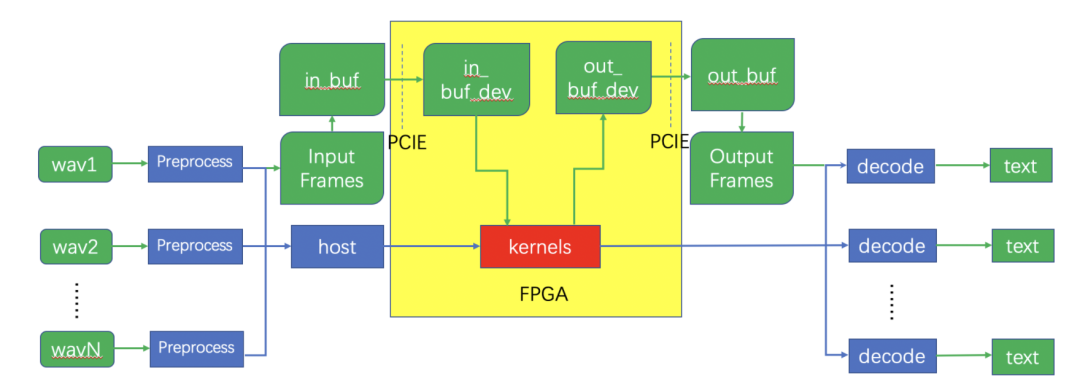
系统整体架构
系统整体架构如上图所示:
-
Host(调度加速引擎的代码框架)接收输入的语音数据,经过前处理,神经网络推理,和后处理过程生成识别后的文本。
-
神经网络推理过程(黄色部分)卸载到 FPGA 加速卡上完成。
-
Host 将输入数据通过 PCIe 接口搬移到 FPGA 加速卡的设备内存中。
-
启动 FPGA 上的 ASR Accel Engine(即 Kernel,负责执行模型计算)进行神经网络推理。
-
将推理结果从设备内存搬移到主机内存。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢