
这次收集的相关文章都是近期关于图分类任务的图神经网络的对抗攻击相关的研究。
相比于节点级别的攻击,图分类的攻击也渐渐成为研究者关注的重点。值得关注和跟进。
1.【ICDM】 Adapting Membership Inference Attacks to GNN for Graph Classification: Approaches and Implications
地址: http://arxiv.org/abs/2110.08760
导读:成员推理攻击(Memebrship Inference Attacks)旨在识别数据样本是否用于训练机器学习模型。它可能会增加严重的隐私风险,因为会员可能会泄露个人的敏感信息。例如,识别一个人是否参与了医院的健康分析训练集表明该人曾经是该医院的患者。而本文则是讲其应用到图神经网络领域的图分类问题上。
在本文中,作者的目标是推断出一个图样本是否已用于训练 GNN 模型。 文章提出两种类型的攻击,1)基于训练的攻击 2)基于阈值的攻击。 文章使用五个具有代表性的 GNN 模型进行了全面的实验,以评估在七个真实世界数据集中的攻击效果。 文章提出的两种攻击都被证明是有效的并且可以实现高性能,即在大多数情况下达到超过 0.7 的攻击 F1 分数。 此外,文章进一步分析了 MIA 对 GNN 的影响。 研究结果证实,与具有非图结构的模型相比,GNN 可能更容易受到 MIA 的影响。 与节点级分类器不同的是,图级分类任务上的 MIA 与 GNN 的过度拟合水平而非其训练图的统计属性更相关。
2. 【USENIX Security 2022】Inference Attacks Against Graph Neural Networks
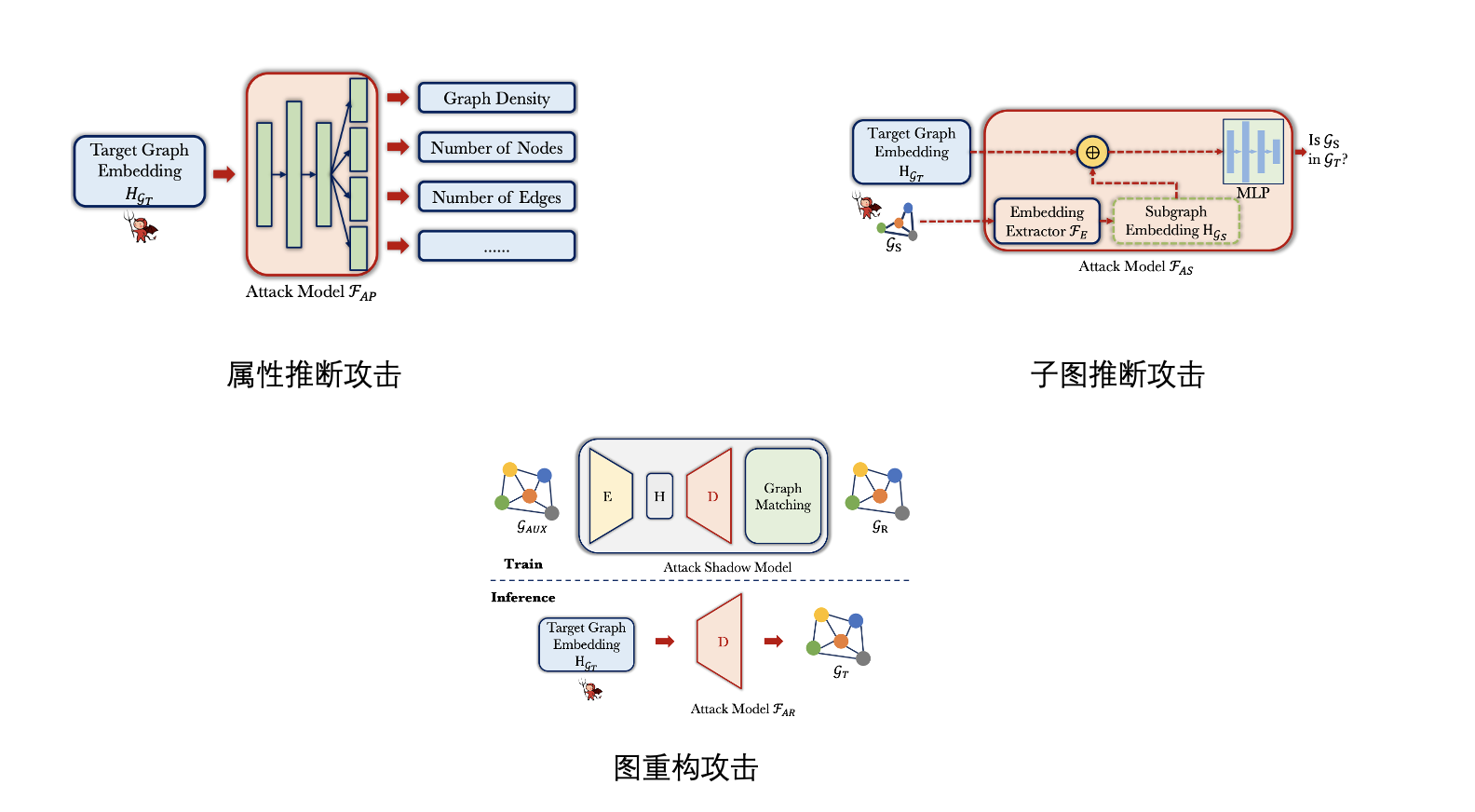
地址:https://arxiv.org/abs/2110.02631
代码:https://github.com/Zhangzhk0819/GNN-Embedding-Leaks
主页:https://yangzhangalmo.github.io/
导读:这个工作来自 CISPA 张阳老师团队,他们组长期专注于机器学习模型的安全性和隐私性。
文章系统的研究了在图表示中存在的信息泄露的问题。
包括:Property Inference Attack(性质推断攻击), Subgraph Inference Attack(子图推断攻击), 和Graph Reconstruction Attack (图重构攻击)。
上述的三种推断攻击方式都会泄漏隐私信息。最后文章还提出了一种高效的基于图嵌入扰动的防御机制缓解推断攻击。并且该机制不会降低图分类任务的性能。
3. 【NeurIPS2021】Adversarial Attacks on Graph Classification via Bayesian Optimisation
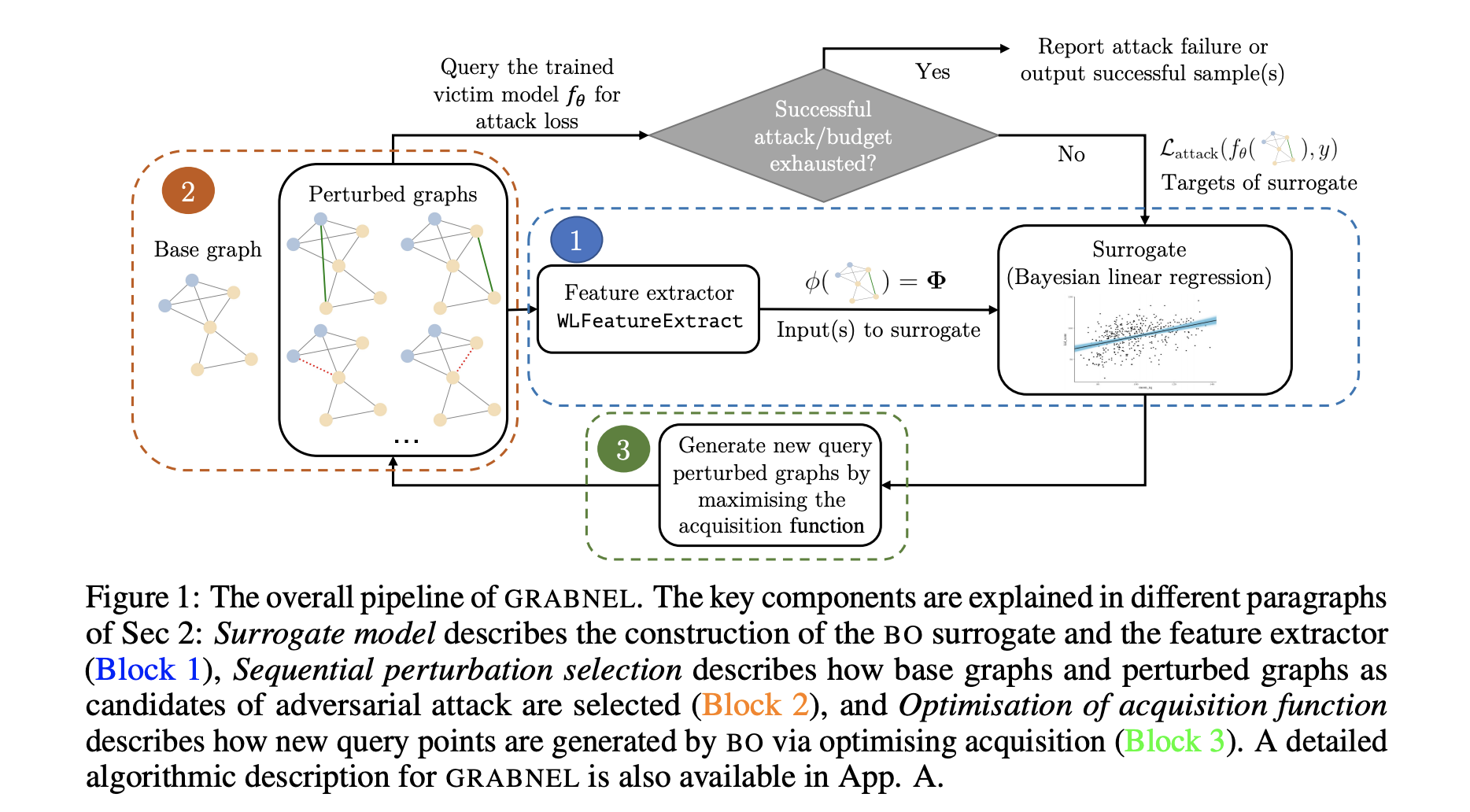
地址:http://arxiv.org/abs/2111.02842
代码:https://github.com/xingchenwan/grabnel
导读:过去已有的大量的工作都证明了图神经网络模型在节点级别的任务上是易被攻击的。
但是较少的工作探索在图分类的任务上,图神经网络模型是否易被攻击。过去的模型通常需要一些不现实的条件,例如需要获取被攻击的模型的内部信息,或者较多的查询来获取模型的信息从而实现攻击。
在本文中, 作者提出了一种基于贝叶斯优化的攻击模型。该模型是黑盒、查询高效且容易应用的。
文章在大量的图分类任务上进行了实验验证,并且分析了常见的对抗样本产生的可解释的模式。这些发现将会进一步去启发设计出对抗鲁棒的图分类模型。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢