
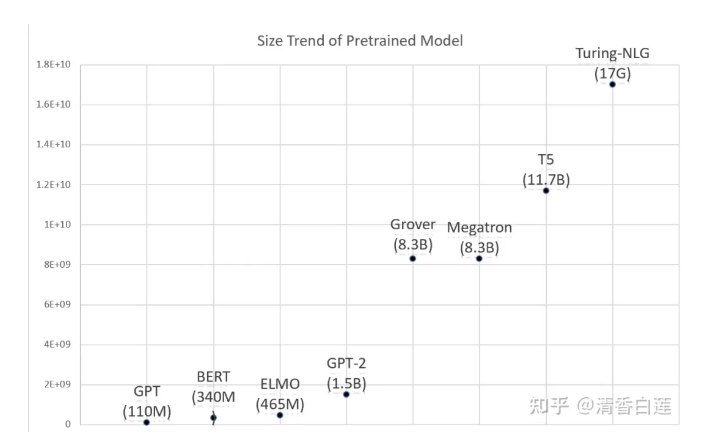
基于 Transformer 的预训练模型,尤其是 BERT,给各种 NLP 任务的 performance 带来了质的飞跃。如今 pretrained model + Fine tune 几乎已经成为 NLP modeling 工作的标准范式。然而这些模型却是越来越重,如 RoBERTa-large 有 3.55 亿参数,GPT2-xl 有 15 亿参数,GPT3 的参数达到了 1750 亿!
在有着三高问题(特点?)的互联网系统中使用这种模型面临着很大的性能瓶颈,甚至已经很难将一个 SOTA 的模型直接搬到线上进行实时的推理计算。本文将介绍最广为使用的预训练模型 BERT 的推理加速技术,这些技术可以应用到其他类似 Transformer Based 预训练模型中。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢