标题:阿里|M6-10T: A SHARING-DELINKING PARADIGM FOR EFFICIENT MULTI-TRILLION PARAMETER PRETRAINING(M6-10T:用于高效多万亿参数预训练的共享去链接范式)
作者:Junyang Lin, An Yang, Hongxia Yang
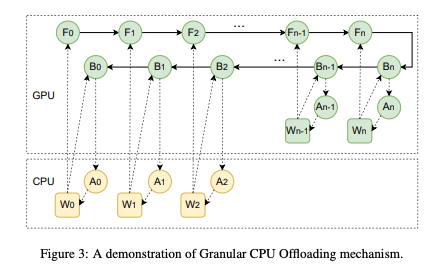
简介:本文介绍一种训练大模型的CPU内存并维护高GPU的方法。深度学习算法、分布式训练、甚至大型模型的硬件设计也使得训练超大规模模型比较困难,比如 GPT-3和Switch Transformer拥有数千亿或甚至数万亿个参数。然而,在资源有限的情况下,极端规模需要大量计算和内存占用的模型训练在模型收敛方面的效率低得令人沮丧。在本文中,作者为需要高内存占用的大型模型提出了一种称为“伪到实”的简单训练策略。“伪到实”兼容大模型具有顺序层的架构。作者展示了预训练的实践前所未有的 10 万亿参数模型,比10天内仅在512个GPU上实现了最先进的技术。除了演示“伪到实”的应用,作者还提供了一种技术,Granular CPU offloading,管理用于训练大型模型的 CPU 内存并维护高 GPU 实用程序。在相当数量的资源上,快速训练超大规模模型可以带来更小的碳足迹,并为更环保的人工智能做出贡献。
论文下载:https://arxiv.org/pdf/2110.03888.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢