

由于有限的内存,MCU(MicroController Units, MCU)端的TinyDL极具挑战性。为缓解该问题,研究者提出一种广义的patch-by-patch推理机制,它仅对特征图的局部区域进行处理,大幅降低了峰值内存。然而,常规的实现方式会带来重叠块与计算复杂问题。研究者进一步提出了recptive field redistribution调整感受野与FLOPs以降低整体计算负载。人工方式重分布感受野无疑非常困难!研究者采用NAS对网络架构与推理机制进行联合优化得到了本次分享的MCUNetV2。所提推理机制能大幅降低峰值内存达4-8倍。
所推MCUNetV2取得了MCU端新的ImageNet分类记录71.8% ;更重要的是,MCUNetV2解锁了MCU端执行稠密预测任务的可能性,如目标检测取得了比已有方案高16.9%mAP@VOC的指标。本研究极大程度上解决了TinyDL的内存瓶颈问题,为图像分类之外的其他视觉应用铺平了道路 。

论文地址:https://arxiv.org/pdf/2110.15352.pdf
研究者提出一种patch-based inference机制打破初始层的内存瓶颈问题,见下图。
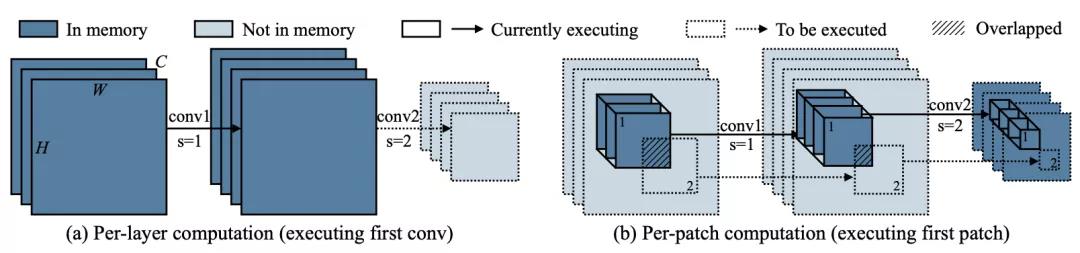 计算复杂度与patch方案初始阶段的感受野相关,考虑到patch阶段的输出,越大的感受野对应越大的输入分辨率,进而导致更多的重叠区域与重复计算。
计算复杂度与patch方案初始阶段的感受野相关,考虑到patch阶段的输出,越大的感受野对应越大的输入分辨率,进而导致更多的重叠区域与重复计算。
研究者提出了重分布(redistribute)感受野以降低计算复杂度,其基本思想在于:
-
降低patch阶段的感受野;
-
提升layer阶段的感受野。
降低初始阶段的感受野有助于降低patch部分的输入尺寸与重复计算。然而,某些任务会因感受野较小导致性能下降。因此,我们进一步提升layer部分的感受野以补偿性能损失。
重新分配感受野使我们能够以最小的计算/延迟开销享受内存减少的好处,但策略因不同的主干而有所不同。在设计主干网络(例如,使用更大的输入分辨率)时,减少的峰值内存还允许更大的自由度。为了探索如此大的设计空间,研究者建议以自动化方式联合优化神经架构和推理调度。
Backbone optimization:研究者参考MCUNet采用了类MnasNet搜索空间,而类MobileNetV3搜索空间因Swish激活函数问题导致难以量化而弃用。作者认为:最佳的搜索空间配置不仅硬件相关,同样任务相关。因此,还将r与w纳入搜索空间。
Inference scheduling optimization:给定模型与硬件约束,将寻找最佳推理机制。框架的推理引擎基于MCUnet中的TinyEngine扩展而来,除了TinyEngine中已有的优化外,还需要确定块数量p与模块数量n以执行patch推理,确保满足SRAM约束。
Joint Search:需要协同设计骨干优化与推理机制。比如,给定相同约束,可以选更小的模型以layer方式推理,或更大的模块以patch方式推理。因此,我们两者纳入优化并采用进化搜索寻找满足约束的最佳组合。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢