

论文链接:https://arxiv.org/pdf/2109.04712.pdf
文章源码:https://github.com/Roche/BalancedLossNLP
多标签文本分类是自然语言处理中的一类经典任务,训练模型为给定文本标记上不定数目的类别标签。然而实际应用时,各类别标签的训练数据量往往差异较大(不平衡分类问题),甚至是长尾分布,影响了所获得模型的效果。重采样(Resampling)和重加权(Reweighting)常用于应对不平衡分类问题,但由于多标签文本分类的场景下类别标签间存在关联,现有方法会导致对高频标签的过采样。本项工作中,我们探讨了优化损失函数的策略,尤其是平衡损失函数在多标签文本分类中的应用。基于通用数据集 (Reuters-21578,90 个标签) 和生物医学领域数据集(PubMed,18211 个标签)的多组实验,我们发现一类分布平衡损失函数的表现整体优于常用损失函数。研究人员近期发现该类损失函数对图像识别模型的效果提升,而我们的工作进一步证明其在自然语言处理中的有效性。
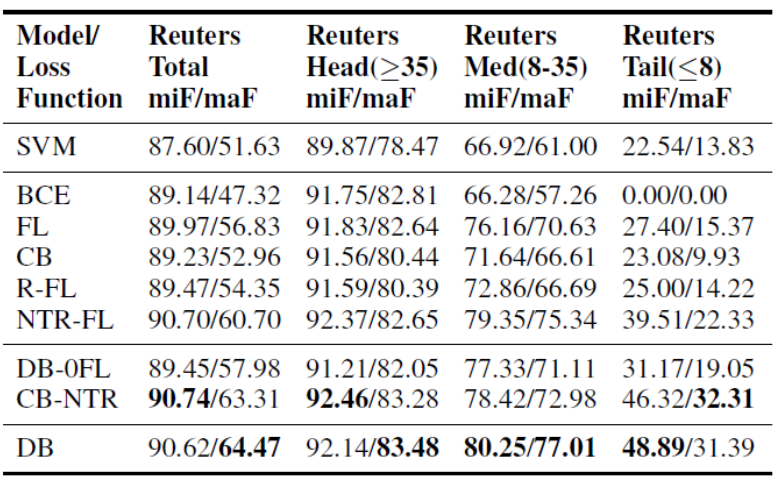
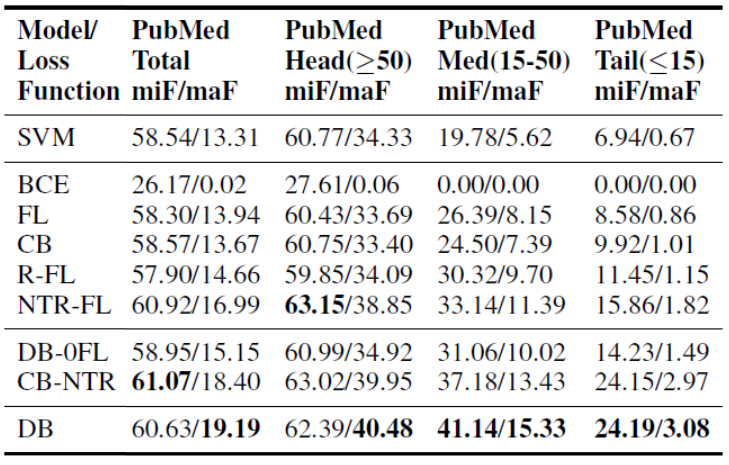
我们比较了不同损失函数与经典 SVM one-vs-rest 模型的表现。对于各个数据集和模型,我们计算了标签集整体以及头部、中部、尾部标签子集的micro-F1 和 macro-F1 得分(Wu et al., 2019;Lipton et al., 2014 )。表 2 汇总了不同损失函数的实验结果。Reuters-21578 结果中,BCE 的表现最差。依次对比 micro-F1 和 macro-F1之间、及不同组间的得分可以看出长尾分布的影响。PubMed 数据由于不平衡更明显,长尾分布的影响更大。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢