BERT 预训练模型问世以来,改变了很多 NLP 任务的习惯。很多 NLP 任务都会直接在 BERT 的基础上做一个 fine-tune,构建一个 baseline 模型,既快捷也使用,但 BERT 在做文本表达任务时也有一些明显的缺点。
既然有缺点,那这么卷的深度学习领域肯定会有解决方法。于是 BERT-flow、BERT-whitening 及 SimCSE 就来了。
最近刚好也在做文本表达类的任务,就把这个任务相关的文章学习总结了一下,欢迎交流学习。
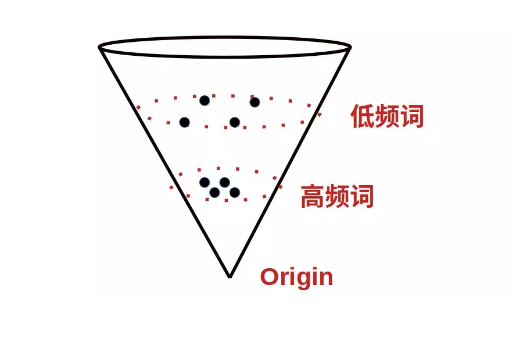
以上是 BERT encode 句子向量具有的两个明显的问题:1)句子向量具有各向异性;2)向量分布不均匀,低频词稀疏,高频词紧密,且聚集于不同的分布空间。
既然问题已经定义清楚了,那这么卷的 NLP 领域肯定会有解决方法。因此 BERT-flow 还有 Bert-whitening 就出现了,这两篇文章解决的都是问题是一致的,都是想解决句子 embedding 的各向异性及向量的分布不均匀问题。
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢