标题:META|Masked Autoencoders Are Scalable Vision Learners(屏蔽自编码器是可扩展的视觉学习器)
作者:Kaiming He, Xinlei Chen等
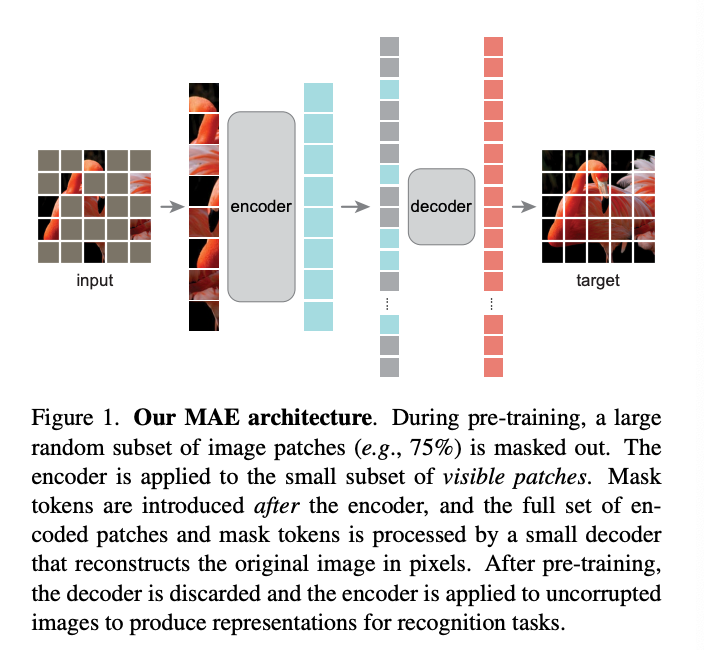
简介:本文介绍了掩码自编码器 (MAE) 用于计算机视觉的可扩展自监督学习。作者的MAE方法很简单:屏蔽了输入图像并重建丢失的像素。它基于两个核心设计,首先,作者开发一个不对称的编码解码器架构,具有仅对补丁的可见子集(没有掩码标记)进行操作的编码器,以及用于重建的轻量级解码器来自潜在表示和掩码的原始图像符号;其次,作者发现掩饰的比例很高输入图像,例如 75%,产生一个非平凡的和有意义的自我监督任务。结合这两种设计使作者能够高效地训练大型模型:作者加速训练(3 倍或更多)并提高准确性。作者的可扩展方法允许学习泛化能力强的高容量模型:例如,仅使用 ImageNet-1K数据的方法,ViT-Huge模型达到了最好的准确率(87.8%)。下游任务中的性能优于有监督的预训练,并显示出有希望的扩展行为。
论文:https://arxiv.org/pdf/2111.06377.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢