自从 2018 年 BERT 在 NLP 领域声名鹊起,通过预训练在 n 多 NLP 任务中刷榜,成功发掘出了 transformer 的潜力,众多研究者就看到了多模态发展的新的机会——使用大量数据做预训练。
因为从 updn 模型开始,多模态这面普遍把图片提取成区域特征序列做后续处理,这样的话多模态是视觉和文本特征序列,NLP 中是文本特征序列,没什么本质差异,自然可以把预训练搬过来,一系列多模态 transformer 预训练的文章应运而生。
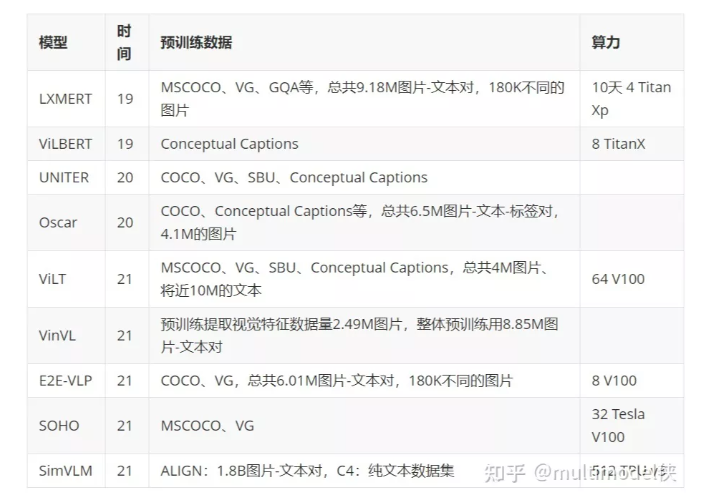
举个栗子:LXMERT、VLBERT、ViLBERT、UNITER、UNIMO、OSCAR、VisualBert、VLP、今年的 ViLT、VinVL、SOHO、SimVLM、METER 等等,以及没有使用预训练也达到很好效果的 MCAN。
按结构主要可以分为单流、双流,单流就是把不同模态特征序列先拼起来,通过 transformer 进行自注意力,双流就是先各个模态特征单独自注意力,再经过 transformer 交叉注意力。模型都是大同小异,或者预训练方法有些小的差别,最主要的趋势是预训练数据越来越大。
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢