
论文标题: A Survey of Visual Transformers
论文链接:https://arxiv.org/abs/2111.06091
作者单位:中国科学院大学 & 东南大学
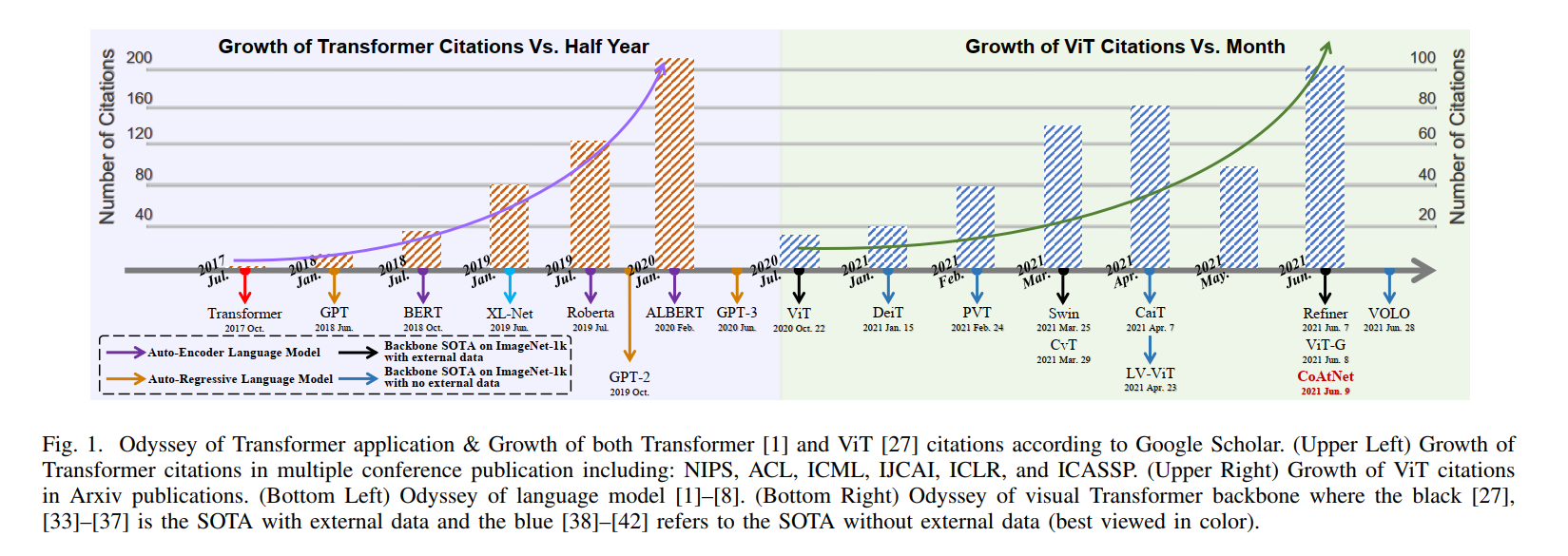
Transformer 是一种基于注意力的编码器-解码器架构,彻底改变了自然语言处理领域。受这一重大成就的启发,最近在将类似 Transformer 的体系结构应用于计算机视觉 (CV) 领域方面进行了一些开创性工作,这些工作已经证明了它们在各种 CV 任务上的有效性。与现代卷积神经网络 (CNN) 相比,visual Transformers 依靠有竞争力的建模能力,在 ImageNet、COCO 和 ADE20k 等多个基准测试中取得了令人印象深刻的性能。在本文中,我们全面回顾了针对三个基本 CV 任务(分类、检测和分割)的一百多种不同的视觉变换器,其中提出了一种分类法来根据它们的动机、结构和使用场景来组织这些方法. 由于训练设置和面向任务的差异,我们还在不同的配置上评估了这些方法,以方便直观地进行比较,而不仅仅是各种基准测试。此外,我们揭示了一系列基本但未开发的方面,这些方面可能使 Transformer 从众多架构中脱颖而出,例如,松弛的高级语义嵌入以弥合视觉和顺序 Transformer 之间的差距。最后,提出了三个有前景的未来研究方向,以供进一步研究。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢