
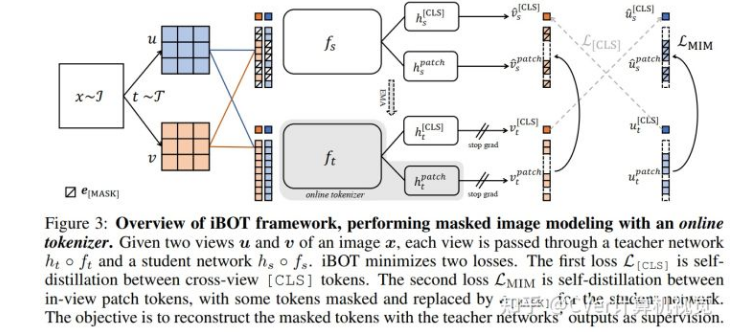
本文研究了视觉Transformer的类 BERT 预训练,并强调了语义上有意义的视觉tokenizer的重要性。提出了一个自监督框架 iBOT,通过使用online tokenizer的自蒸馏执行masked图像建模,在分类、检测、分割任务上取得最先进的结果。

language Transformer的成功主要归功于masked language modeling (MLM) 的pretext任务,其中文本首先被标记为具有语义意义的片段。在这项工作中,我们研究了masked image modeling (MIM),并指出了使用语义上有意义的视觉标记器的优势和挑战。
论文链接:https://arxiv.org/abs/2111.07832
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢