

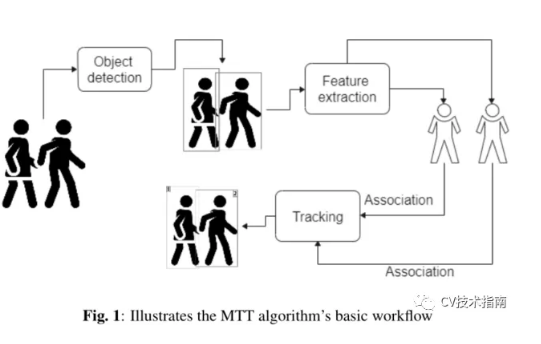
视频监控中的多目标跟踪(MTT)是一项重要而富有挑战性的任务,由于其在各个领域的潜在应用而引起了研究人员的广泛关注。多目标跟踪任务需要在每帧中单独定位目标,这仍然是一个巨大的挑战,因为目标的外观会立即发生变化,并且会出现极端的遮挡。除此之外,多目标跟踪框架需要执行多个任务,即目标检测、轨迹估计、帧间关联和重新识别。已经提出了各种方法,并做出了一些假设,以将问题约束在特定问题的上下文中。本文对利用深度学习表征能力的MTT模型进行了综述。
多目标跟踪分为目标检测和跟踪两个主要任务。为了区分组内对象,MTT算法将唯一ID与在特定时间内保持特定于该对象的每个检测到的对象相关联。然后利用这些ID来生成被跟踪对象的运动轨迹。检测通常由预先训练的检测器提供,亲和力模型提供检测和方法之间的估计。
论文地址:https://arxiv.org/abs/2110.15674
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢