
本文转载自知乎专栏,作者Peter潘欣
概述
AI模型的规模在过去4年维持了每年10倍的增长。2021年的产生的大模型已经达到1 trillion parameters。而最近分布式训练号称可以支撑100trillion parameters。似乎这个趋势还能继续维持两年以上。
训练巨大的模型必然需要底层基础软件和芯片的支撑。然而GPU在过去4年中,无论是显存空间,或者是算力的增长,都在10倍这个数量级,显然跟不上10000倍的模型规模增长。硬件不够,软件来凑。深度学习框架的分布式训练技术强势的支撑起了模型暴涨性的增长。
这篇文章总结了过去几年支撑模型规模上涨的关键分布式训练技术。总体来说,核心解决的问题是如何在保障GPU能够高效计算的同时,降低显存的开销。关键可以总结在几个方面的技术上:
- Data Parallelism
- Model Parallelism
- Pipeline Parallelism
- Checkpoint
- Sharding
- Offload
注:比较懒,不怎么单独绘图。如果网上有合适的图片就直接截图了。
Data Parallelism
DP关注的问题是大规模Batch Size下,如何降低显存的开销。我们知道,模型在forward和backward的中间计算过程都会有中间状态,这些中间状态通常占用的空间是和batch size成正比的。
通过将大的batch size切分到多个n个GPU上,每个GPU上部分状态的空间开销能降到1/n,而省下的空间可以用来保存模型的parameter,optimizer state等,因此可以提高GPU上容纳的模型规模。
DP是一种非常简单易用的分布式训练方法,几乎所有的训练框架都支持这种方法。早期比较流行的开源实现是horovod。现在pytorch ddp和tensorflow mirror strategy都原生的支持了。
DP的极限在于两个方面:
- 当batch size=1时,传统方法无法继续切分。
- 经典DP主要切分的是batch size正比的部分中间状态。但是对于parameter, optimizer state等batch size无关的空间开销是无能为力的。
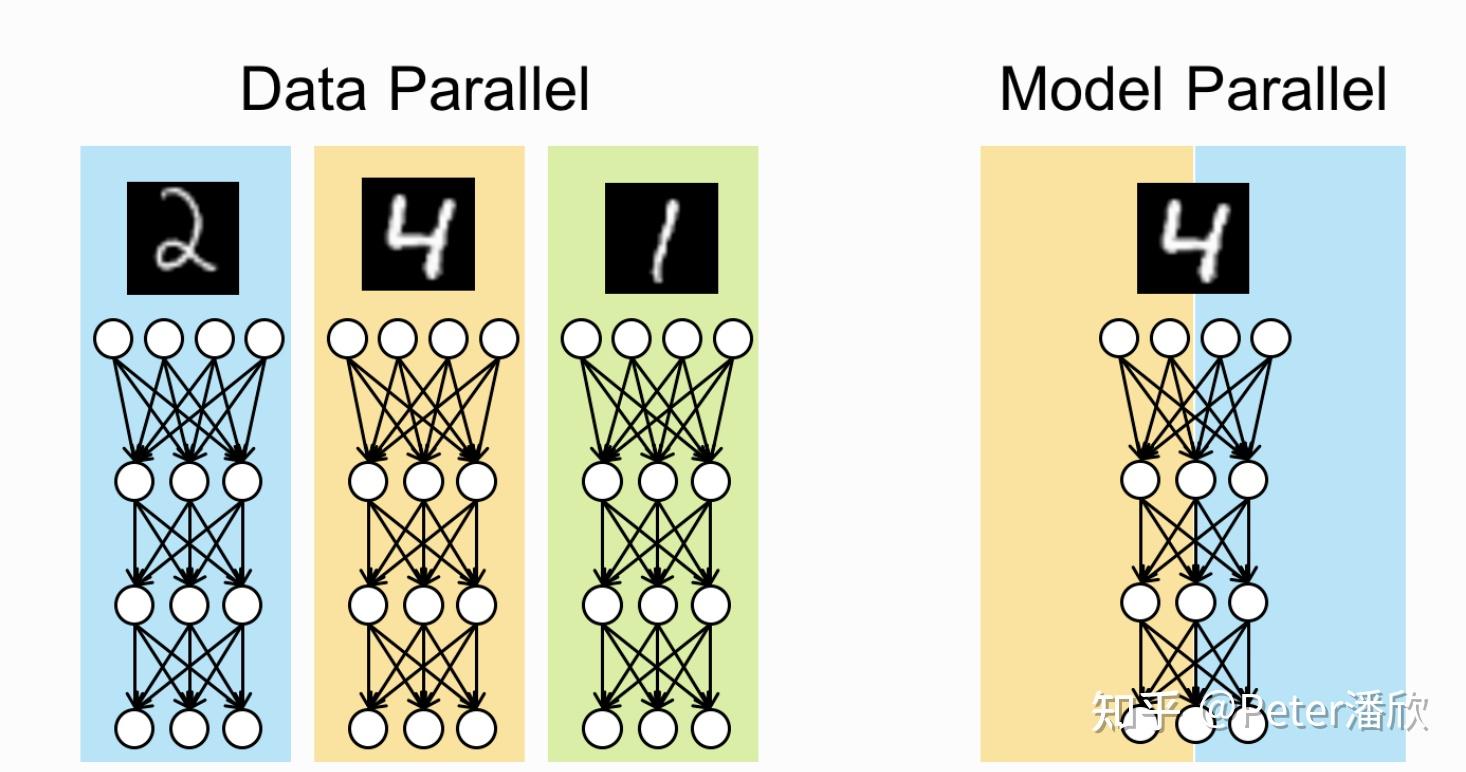
Model Parallelism
关于的DP的极限提到,当batch size=1时,DP难以进一步的提高模型规模的上限。另外,传统DP仅仅是从数据的层面切分,降低显存空间压力。而我们知道每个GPU上依然需要一份完整的parameter等副本。
MP基本含义在于把模型本身进行切分,使得每个GPU卡只需要存模型的一部分。多个GPU配合起来完成一个完整的minibatch。按这个比较宽泛的定义,MP的使用方式就比较的多样,比如:
- 对一个算子进行拆分,比如FC,把参数和计算的切分到多个GPU上,通过通信完成这个原子计算。
- 单纯的把模型的参数切分到多个GPU上,在使用时通过数据驱动的方式,每个GPU从其他GPU上拉取需要的那部分。比如大embedding参数如果有100GB,可以切分成8份放在8个GPU上。每个minibatch计算时embedding层仅需要gather 100GB中很少的一部分。
- 简单的把模型横向切分几份,分别放在不同GPU上。比如一个1000层的ResNet,可以每个GPU放其中100层的参数。当一个minibatch进来后,依次通过这10个GPU,完成这1000层的计算。
TensorFlow可以说是支持MP的典型框架,通过将device placement暴露给用户,开放了几乎所有的玩法。但是弊端就是大部分用户其实并不能合理的使用,达到一个比较好的效果。反而是经常因为配置错误导致性能急剧下降。导致TensorFlow的开发团队不得不投入许多时间帮用户调优。
MP的玩法很多,可以在DP的基础上显著降低单个GPU上的显存压力。但是MP的问题也很多,使用起来远比DP复杂:
- 模型切分的可选项太多,次优解会导致较高的通信开销,显著降低硬件的利用率和训练速度。记得有个同事发了篇论文,用1000个GPU,基于RL算法搜索了一个星期,找到了NMT模型上一个超越所有人工的device placement。(仅适用于特定机房,网络,设备,模型等等的组合)
- MP在一些应用场景(比如上面说的ResNet例子)在计算一个minibatch时,硬件是依次激活的,其他硬件都在等待,硬件的利用率会非常的低。

Pipeline Parallelism
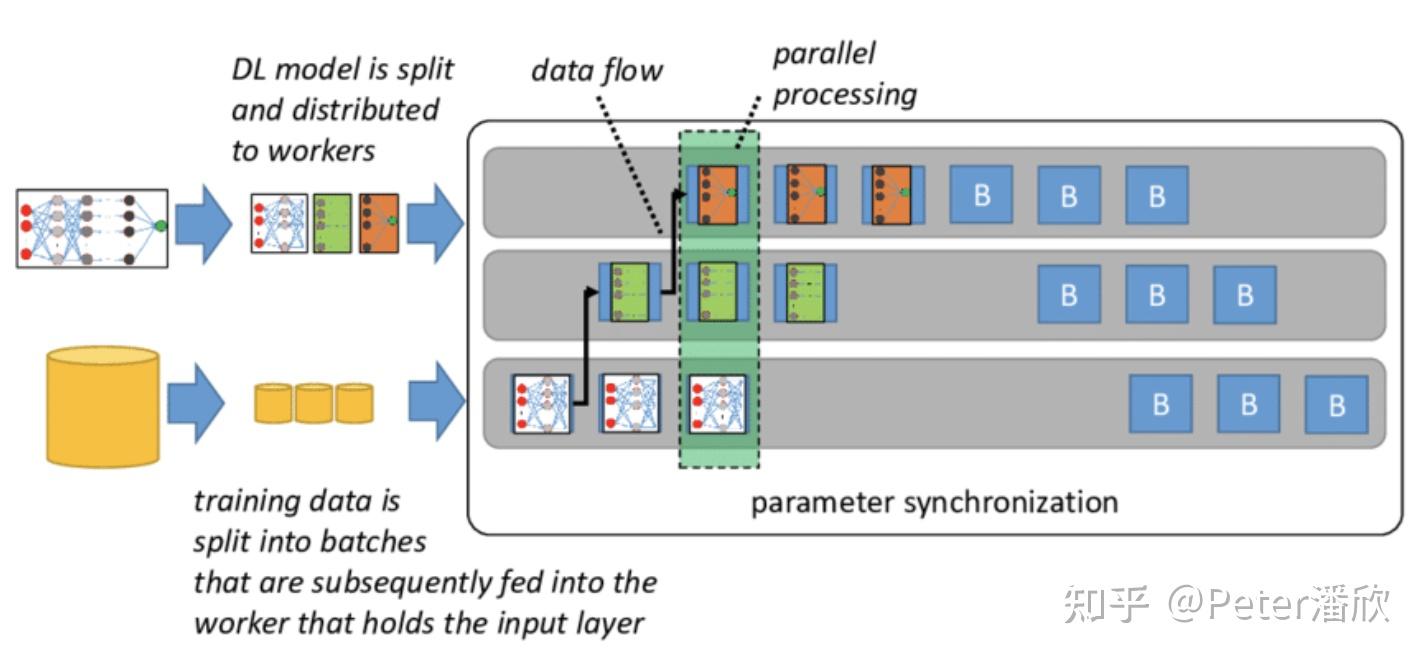
前面提到了MP一个比较大的问题是GPU利用率低。当没有计算到某个GPU上的模型分片时,这个GPU常常是闲着的。PP一定程度上解决了这个问题。
PP的思想也比较简单,使用了经典的Pipeline思想。在模型计算流水线上,每个GPU只负责模型的一个分片,计算完就交给下一个GPU完成下一个模型分片的计算。当下个GPU在计算时,上一个GPU开始算下一个minibatch属于它的模型分片。

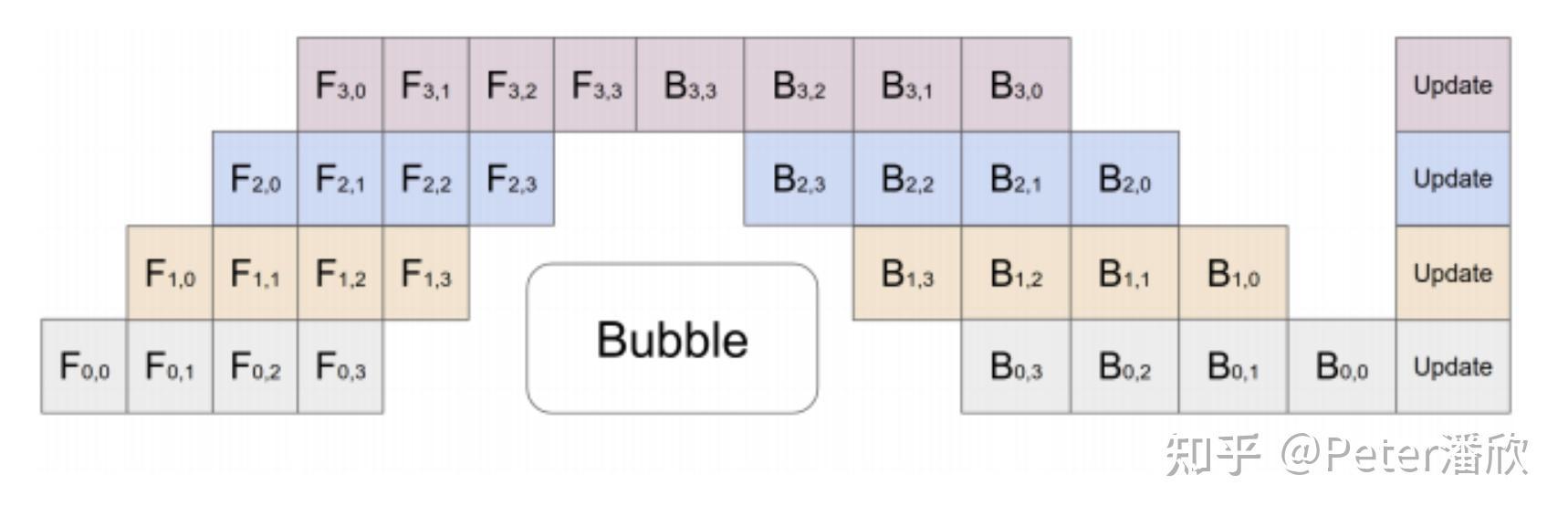
这里需要注意到不同模型分片使用的parameter分片是否同步的问题(防止流水线更新parameter的问题)。从数学上,一个minibatch数据训练使用的所有模型参数都需要是同步的(不完全一定)。因此,在optimize时,整个PP需要进行某种形式的同步。
PP依然没有完全解决部分硬件时间空闲的问题。同时MP使用的复杂性和调优依然是个问题。

Checkpoint
在每个minibatch的计算过程中,forward中的一些中间结果会被保存在显存里,等到backward的时候会被读取出来用于计算gradient。对于一些比较宽和深的模型,这部分forward的空间的开销是非常显著的。
同样输入下,每次forward的中间结果都是一样的(dropout is exception)。Checkpoint利用了这个特点,是一种用时间换空间的技术。在forward的过程中,我们只选择记录其中一部分的中间结果,其他中间结果被扔掉,节约显存。当backward是如果需要这些已经被扔掉的中间结果时,它们可以基于没有被扔掉的上一个中间结果(checkpoint),被重新计算出来。
有些模型中间有一些“小蛮腰”。比如一些sequeeze、encoder模型结构。或者是模型中间有些激活计算比较轻量,重新计算开销较小。基于这些情况,checkpoint很多时候可以大幅节省空间开销,同时额外的计算耗时增加较小。
Sharding
前面提到DP的显存节省的限制,而许多MP又存在易用性差和性能的问题。Sharding技术比较好的解决了这些问题。一方面它可以基于DP叠加,同时我也把它理解成是一种比较易用的MP技术。
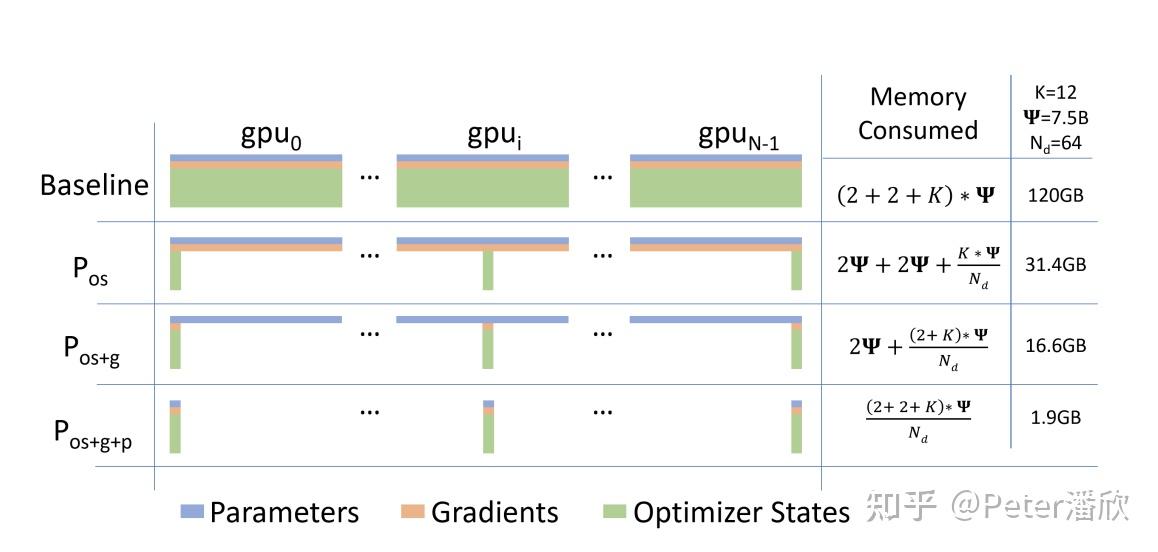
Sharding分为3个层面空间开销的Sharding,使得可以通过增加GPU个数,等比降低每个GPU需要的显存。
- Optimizer States Sharding。对于一些优化器,比如Adam,Optmizer State的空间开销往往比Parameter本身还大。因此可以被Sharding到各个GPU上。
- Gradient Sharding。传统DP需要让每张卡都获得其他所有卡计算的gradient,用于Optimize本地的完整parameter副本。Sharding后,每个卡仅负责模型一部分Gradient的Reduce,因此只需要从其他卡获取这部分的gradient,并通过本地那部分的optimizer state,计算出一部分的最新parameter。在下一minibatch时,各个卡再从其他所有卡上gather每张卡更新的那一部分parameter。
- 进一步,每张卡也不再保留完整parameter副本了。而是只保存各自负责一部分的parameter,并基于各自负责的一部分optimizer state和gradient,去更新自己负责的那一部分parameter。当道minibatch计算需要用到某一部分parameter时,再从负责这部分parameter的卡上获取。
通过这种方式,模型的规模可以极大的提高。
而性能的问题,也有非常巧妙的解决办法。由于模型的结构通常是固定的,因此在forward阶段,可以提前并行预拉取parameter,掩盖这部分的通信开销。
比较经典的就是Zero论文,已经开源的DeepSpeed实现。
顺便提一下,过去几年,GPU之间的通信技术得到了比较突破性的提高,所以Sharding技术导致的通信开销往往不会非常显著,而分布式GPU训练集群的规模也因此可以做的更大。

Offload
其实到这里,感觉优化的已经非常极致了。然而还有更猛的。
现在业界有两种超大规模模型:
- 一种是sparse embedding超大的模型,可以达到几十TB。常见于推荐,广告模型。
- 另一种是dense parameter超大的模型,也可以达到几十TB。常见于NLP,多模态等模型中。
对于这种模型,把所有参数放在GPU显存里面都显得非常的奢侈。特别是sparse embedding超大的模型,虽然总体embedding parameter规模很大,然而每个minibatch仅使用其中1%不到的一小部分。
Offload的思想简单来说就是:
- 尽量把parameter, optimizer state等放在内存或者NVME设备上。
- 通过pipeline的方式掩盖掉从低速存储到GPU计算间的通信开销。
Sparse Embedding
前面提到,实际每个minibatch需要使用的embedding只占全量embedding很少一部分。
因此,可以通过CPU流水线,提前计算出来下面N个minibatch用到的所有embedding的总和(较少),并将这部分embedding批量导入GPU。这样GPU就可以连续训练N个minibatch,高效利用GPU算力。当GPU完成N个minibatch训练后,下N个minibatch需要的embedding也已经被CPU通过pipeline的方式提前算好了,所以GPU不需要停下等待。
Dense Parameter
Dense层稍微麻烦一些,通常(目前有些MoE类似的sparse model是例外)每个minibatch都需要用到所有的parameter。
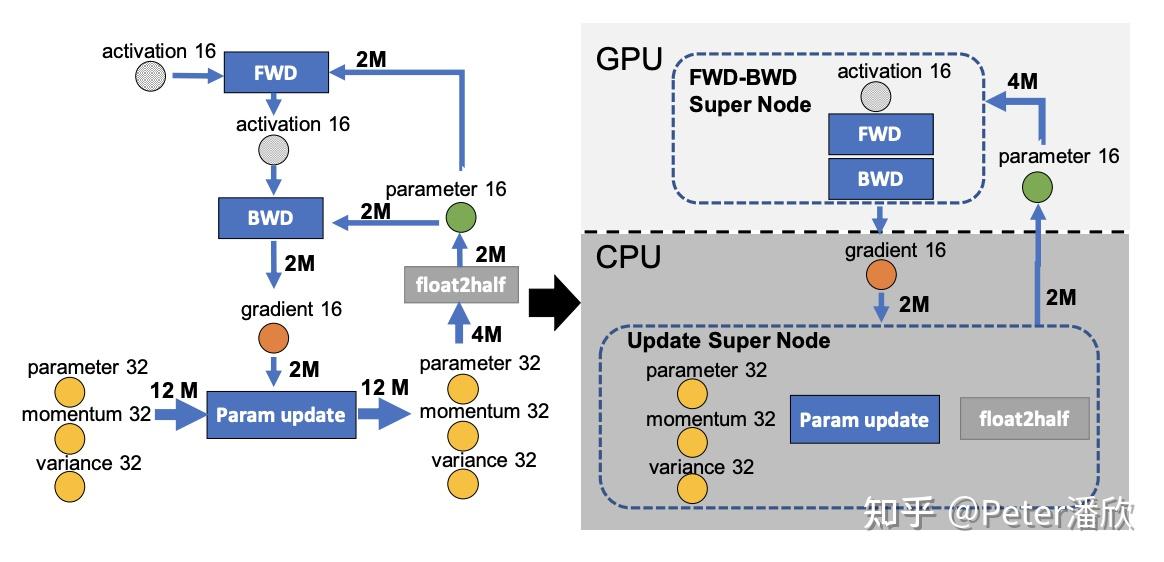
这里同时也需要用到一些混合精度,pipeline的优化:
- 全量的fp32 parameter和optimizer state被放在了CPU(或者NVME)上
- 每个minibatch时,parameter被先被批量转成fp16(节省通信),然后被fetch到GPU上。通过前文提到的预取的方式(需要batch size够大),来掩盖通信的开销。
- gradient在backward时被并行的发送到cpu上,来掩盖通信开销。
- optimize阶段在CPU上通过多核并行完成。由于optimize的计算量和batch size无关,所以在batch size较大时,optimize在CPU上计算并不会显得非常慢。而且甚至能随着GPU个数的增加(batch size增加),出现超线性的scalability。
这里offload不影响性能的关键点在于:
- cpu计算开销于batch size无关。gpu的计算开销于batch size有关。在足够大的batch size下,CPU的计算显得不比GPU慢。
- 另外还有一些优化可以将当前optimize和下个minibatch gpu计算并行起来。虽然有参数过期的风险,实验发现通过预热的方式可以有效避免模型效果的下降。

总结
本文总结了深度学习框架技术是如何在硬件条件限制下,通过多年的技术升级,让AI模型的规模突破天际的。如果我们从更高的视角看,AI模型的增长还有硬件,算法等领域的许多突破。整个生态正在飞速的往前发展。
另外,一些瓶颈也显得越来越明显,这里列几点:
- 模型的无效计算。当前大部分DNN在训练或者推理时都需要完成整个模型的“激活”。而我们知道人类的大脑在思考时,往往只需要大脑的一部分参加工作。相比之下,当前AI模型的计算就显得非常低效。
- 模型的可解释性。巨大的模型虽然带来了意想不到的效果,但是也将AI模型不可解释问题推向了一个极致。我们几乎无法有效的判断模型的能力,模型的潜在风险,或是对模型进行有效的干预。
- 训练Pipeline的易用性。虽然很多技术被提出来,并实现。但是在真实场景中,受限于数据中心网络拓扑,分布式数据系统的能力,机型配置和软件栈,深度学习框架本身的调优等许多原因,很难有效的发挥理论的较优结果。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢