
深度学习优化是构建深度学习模型中的一个关键问题。来自NUS的研究人员发布了《大规模深度学习优化》综述论文,DL优化目标是双重的: 模型准确性和模型效率。至于模型的准确性,研究了最常用的优化算法,从梯度下降变量到(大批量)自适应方法,从一阶方法到二阶方法。此外,还阐述了在大批量训练中出现的泛化差距这一有争议的问题。

近年来,学术界和工业界对在具有更高计算能力和内存限制的TPU和GPU等设备的大集群上扩展DL和分布式训练的兴趣激增。数据并行已经成为分布式训练的主要实践。它将一个大的批处理分布到多个设备,其中每个设备持有一个相同的模型副本,计算局部批处理的梯度,最后在每次迭代收集梯度来同步参数更新。通过最新的优化技术,它现在能够在成千上万的GPU设备上训练非常大的批量。然而,这种规模的训练需要克服算法和系统相关的挑战。其中一个主要的挑战是模型精度在超过某一点(例如32k)时的大批量下降。单纯地增加批处理大小通常会导致泛化性能下降,并降低计算效益。此外,我们不能总是通过使用更多的处理器来提高训练速度,因为通信成本是不可忽略的开销。多处理器协同训练一个任务可以减少整体训练时间,但相应的处理器间通信成本很高,限制了模型的可扩展性。更糟糕的是,拥有数百亿到数万亿参数的模型显然无法装入单个设备的内存中,简单地增加更多设备也无助于扩大训练规模。这种限制阻止DL研究人员探索更高级的模型体系结构。现有的工作研究和开发了克服这些问题的优化技术,以加速大规模深度神经网络(DNN)的训练。我们将这些工作分为两类,一种努力在大规模设置下保持/提高模型的准确性,另一种强调模型的效率,设计不太需要通信和内存的算法。重要的是,它们不是相互排斥的,而是可以协同使用,以进一步加快训练。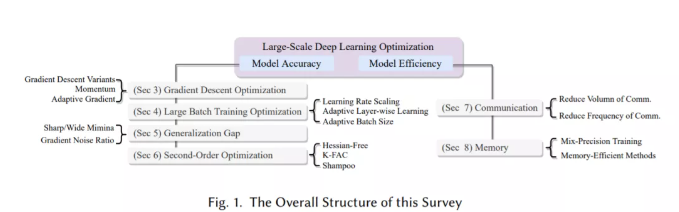
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢