
作者:Arun Babu, Changhan Wang, Andros Tjandra,等
简介:本文介绍了基于 wav2vec 2.0 的跨语言语音表示学习大规模模型 XLS-R。
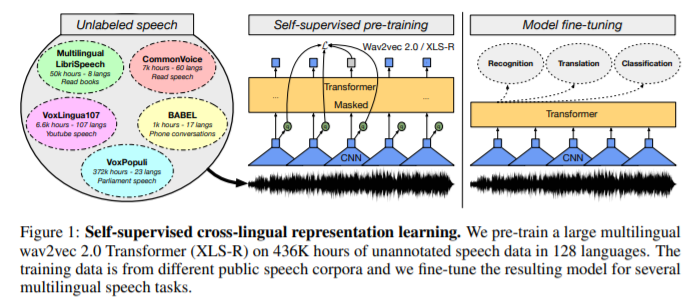
作者在 128 种语言的近 50 万小时的公开语音音频上训练具有高达 2B 参数的模型,这比已知的最大的先前工作多出一个数量级的公共数据。作者的评估涵盖了广泛的任务、领域、数据机制和语言,包括高资源和低资源。在 CoVoST-2 语音翻译基准测试中,作者在 21 个英语翻译方向上将之前的技术水平平均提高了 7.4 BLEU。对于语音识别,XLS-R 改进了 BABEL、MLS、CommonVoice 和 VoxPopuli 上最著名的先前工作,平均相对降低了 14-34% 的错误率。XLS-R 还设置了 VoxLingua107 语言识别的最新技术。而且,作者表明,在有足够的模型大小的情况下,跨语言预训练在将英语语音翻译成其他语言时可以优于仅英语的预训练,这种设置有利于单语预训练。作者希望 XLS-R 可以帮助改进世界上更多语言的语音处理任务。
论文下载:https://arxiv.org/pdf/2111.09296
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢