
作者:Shira Guskin, Moshe Wasserblat, Ke Ding, Gyuwan Kim
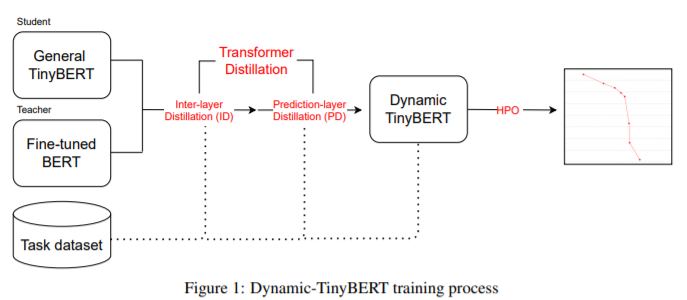
简介:本文研究基于优化TinyBERT的模型如何显著提升计算效率。有限的计算预算通常会阻止在生产中使用Transformer,也无法利用其高精度。TinyBERT 通过将 BERT 自我提炼为具有更少层和更小的内部嵌入的更小的Transformer表示来解决计算效率问题。然而,当将层数减少 50% 时,TinyBERT 的性能会下降,当将层数减少 75% 时,TinyBERT 的性能下降得更厉害,例如跨度问答等高级 NLP 任务。此外,必须针对具有不同计算预算的每个推理场景训练一个单独的模型。在这项工作中,作者提出了 Dynamic-TinyBERT---基于TinyBERT 模型、利用序列长度缩减和超参数优化来提高每个计算预算的推理效率。Dynamic-TinyBERT 只训练一次,性能与 BERT 不相上下,并实现了优于任何其他有效方法的准确度-加速权衡(高达 3.3 倍,损失下降 <1%)。
 未来本研究工作的代码将开源。
未来本研究工作的代码将开源。
论文下载:https://arxiv.org/pdf/2111.09645.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢