
kaiming最近出的MAE和年初的CLIP可能是今年CV领域唯二的重磅文章,有预感MAE会成为CV领域和BERT地位相当的一篇文章。
从BERT和MAE的形态上来说,都引入了mask机制来做无监督预训练,但是又因为vision和language两种模态上本质的不同,导致mask的设计上和整体框架上有所区别。从NLP的Transformer到BERT,然后到CV的ViT、BEiT,CV领域的无监督预训练经历了漫长的探索,直到MAE的出现,才逐渐感觉到CV的大规模无监督预训练开始走向正轨。
本文先捋顺NLP和CV相关文章之间的关系脉络,然后探讨一下BERT和MAE的关系,最后探讨一下BEiT和MAE的关系。
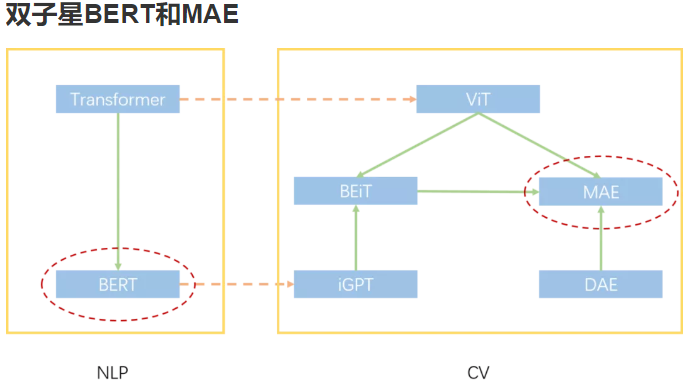
BERT和MAE的关系图。橙色虚线表示NLP和CV跨领域启发,绿色实线表示领域内启发。
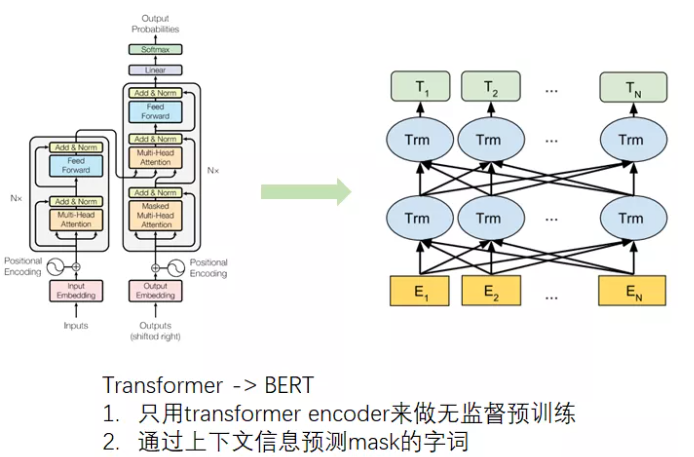
Transformer是整个大规模无监督预训练的开端,Transformer改变了原有Seq2Seq的串行计算的方式,通过矩阵并行计算大幅度提升了长距离依赖的计算效率,并且由于整个框架完全采用attention,Transformer的拟合能力空前绝后。
BERT得益于Transformer强大的计算效率,构造一种类似完形填空的proxy task,可以将不同NLP任务的语料一起拿来做无监督预训练,然后将预训练好的transformer encoder应用于下游任务。
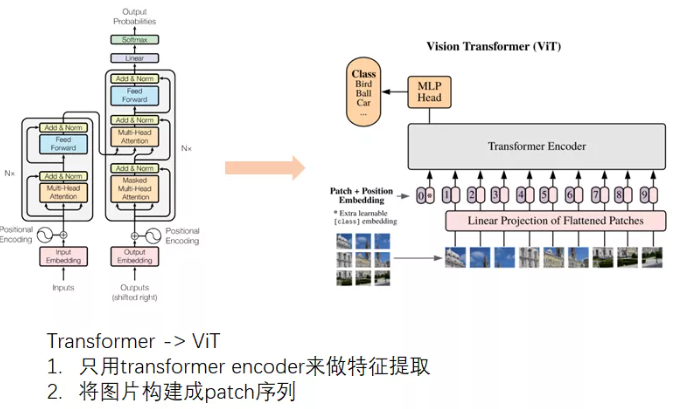
ViT巧妙的将图片构造成patch序列,可以将patch序列送入原始的transformer encoder进行图像分类,ViT直接启发了Transformer和BERT在CV领域的正确打开方式。
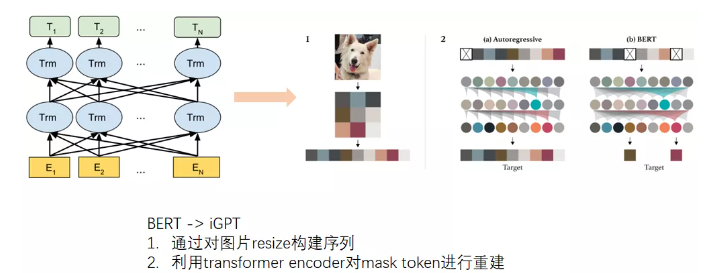
iGPT应该是第一个应用BERT-like的mask方式做CV领域无监督预训练的工作。iGPT把图片resize构建resize序列,同时将resize序列当作监督信号,可以直接使用BERT进行CV的无监督预训练,这给予了cv领域极大的想象空间。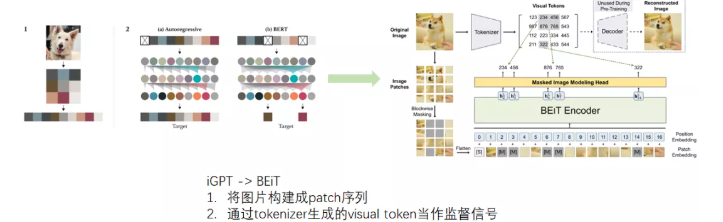
BEiT对iGPT无监督预训练方法进行了改进,借鉴ViT的思路,将图片构建成patch序列,并且通过一个tokenizer得到visual token,用学习的方式得到更精确的监督信号,避免了resize导致的大量信息丢失。
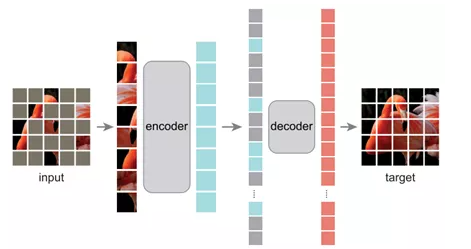
重头戏来了!MAE做的更为极致,设计了一个encoder-decoder预训练框架,encoder只送入image token,decoder同时送入image token和mask token,对patch序列进行重建,最后还原成图片。相比于MEiT,省去了繁琐的训练tokenizer的过程,同时对image token和mask token进行解耦,特征提取和图像重建进行解耦,encoder只负责image token的特征提取,decoder专注于图像重建,这种设计直接导致了训练速度大幅度提升,同时提升精度,真称得上MAE文章中所说的win-win scenario了。
BEiT如今的处境就如同当年NLP的ELMO的处境,碰上MAE如此完美的方法,大部分影响力必然会被MAE给蚕食掉。BERT对整个大规模无监督预训练的发展影响巨大,MAE可能是NLP和CV更紧密结合的开始。
MAE
mask autoencoder在cv领域中起源于denoising autoencoder(DAE),iGPT和BEiT实际上都包含了DAE的思想(DAE是bengio在08年提出来的,DAE认为对输入加噪声,模型可以学习到更鲁棒的特征),MAE则略有不同,将image token和mask token解耦,encoder只对image token进行学习,mask token只在decoder图像重建中使用。
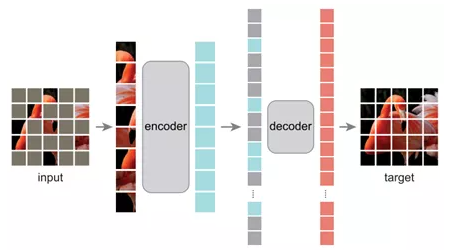
MAE整体上是一个encoder-decoder框架,encoder只对visible patches进行处理,decoder同时处理image token和mask token,得到重建序列,最后还原成图片。其中visible patches是通过shuffle所有patches然后采样前25%得到的(即mask ratio为75%),decoder的输入image token和mask token通过unshuffle还原顺序,并且都需要添加positional embedding来保持patch的位置信息。
BERT vs MAE
MAE最有意思的点是通过mask ratio揭示了vision和language两种模态之间本质差异。
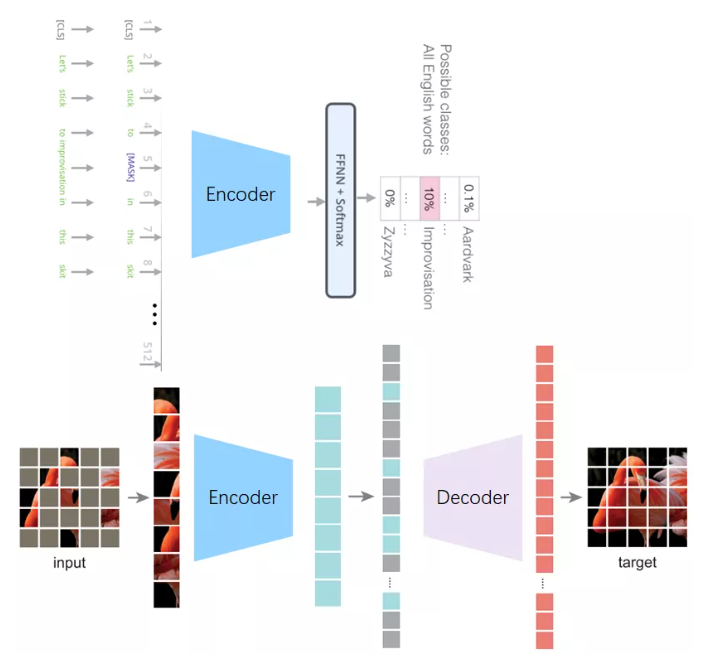
将BERT和MAE的框架进行比较,MAE多了一个decoder重建的过程,并且mask token只用于decoder。BERT的和MAE的encoder功能性有所不同,BERT的功能性更类似于MAE的decoder重建,通过上下文来预测mask信息,而MAE的encoder主要是为了得到好的特征表达,用于图像信息的高度抽象。正是由于language本身就是高度抽象的信息,只需要通过encoder进行重建即可,而vision本身有大量的冗余信息需要先通过encoder获得高度抽象的信息,然后再通过decoder进行重建。另外,NLP大多数的下游任务和BERT的预测mask信息是兼容的,而CV大多数的下游任务不需要重建,而是为了获得高度抽象信息(比如图像分类、目标检测、语义分割),也就是只需要encoder。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢